







详细综述的所有不同类型的集群与他们的用例
地理空间聚类(Geospatial Clustering)
地理空间聚类是将一组空间对象分组为称为“聚类”的组的方法。簇内的对象表现出高度的相似性,而簇则尽可能地不同。聚类的目标是进行概括并揭示空间和非空间属性之间的关系。
让我们通过一个小例子来理解空间聚类
假设您是一个大都会城市的食品配送链的负责人,您想了解客户的偏好,以便扩大您的业务。由于查看每个客户的详细信息是不可行的,因此您将他们分成组并为每个组/集群制定商业计划。
空间聚类可以分为以下五种主要类型:
1.分区聚类 2. 层次聚类 3. 模糊聚类 4. 基于密度的聚类 5. 基于模型的聚类
通过 Locale,我们致力于让每个在地面移动资产的企业都能访问位置数据。让我们深入研究聚类的类型并详细了解每一种!
分区聚类(Partition Clustering)
分区聚类是将数据点分离成不重叠的子集(聚类),使得每个数据点都在一个子集中。基本上,它通过满足以下两个要求将数据分类:
1. 每个数据点只属于一个集群。 2. 每个簇至少有一个数据点。
分区聚类分为三种类型:K-means 聚类、K-medoids 聚类/PAM 和 CLARA(Classification Large Application)
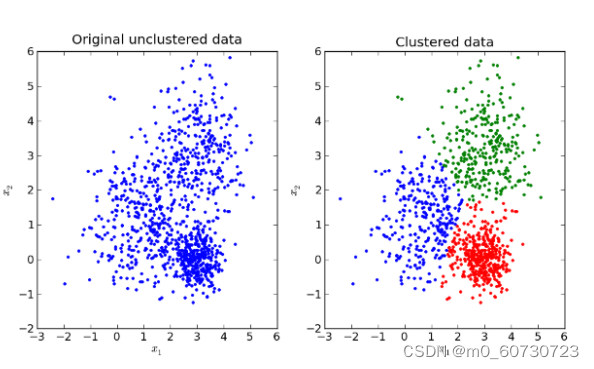
1. K-means 聚类(K-means Clustering)
K-means 聚类是一种分区方法,该方法根据数据集的属性将数据集分解为一组 K 分区。您可以在此处阅读有关 k 均值的更多信息。
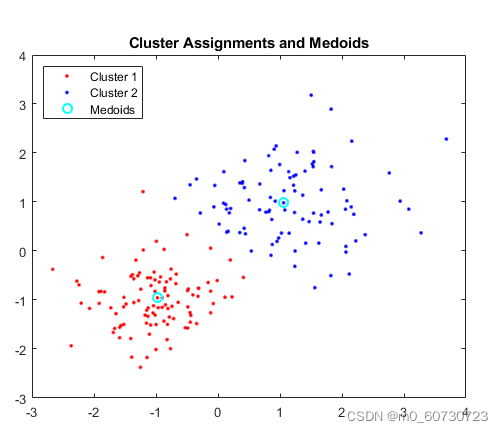
2. K-medoids聚类(K-medoids clustering/PAM)
K-medoids聚类是一种类似于K-means聚类的划分方法。中心点是集群中与集群中所有其他点具有最小差异的点。查看此内容以了解有关 PAM 的更多信息。
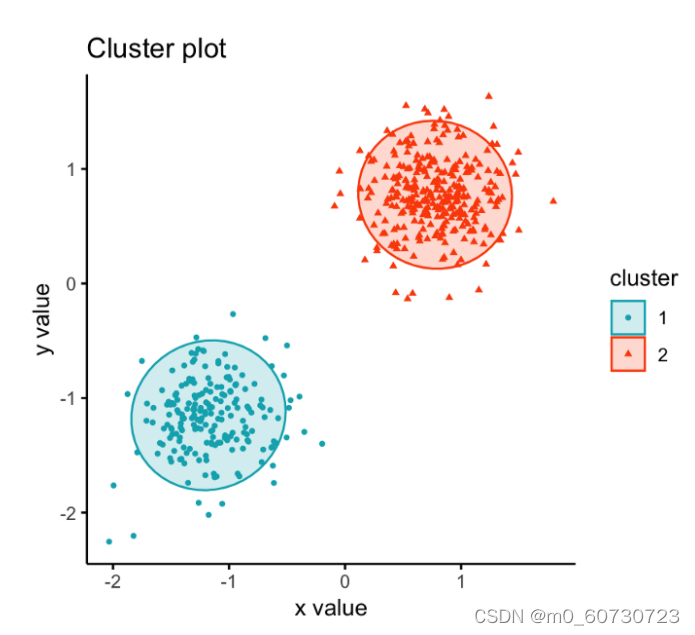
3. CLARA
这是针对大型数据集的 PAM 方法的扩展。 CLARA 不是为整个数据集寻找中心点,而是考虑固定大小的小数据样本,并应用算法为样本生成最佳中心点集。
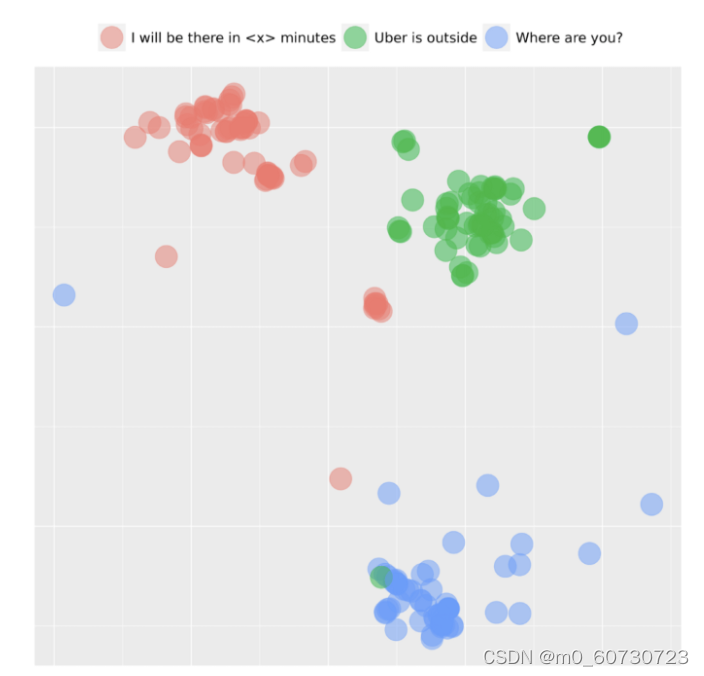
用例:
通常,基于分区的聚类用于查找未在数据中明确标记的组。它有助于将任何新数据点分配给正确的集群。企业使用基于分区的聚类来分割购买历史、按销售活动对库存进行分组、在健康监控中识别组等。
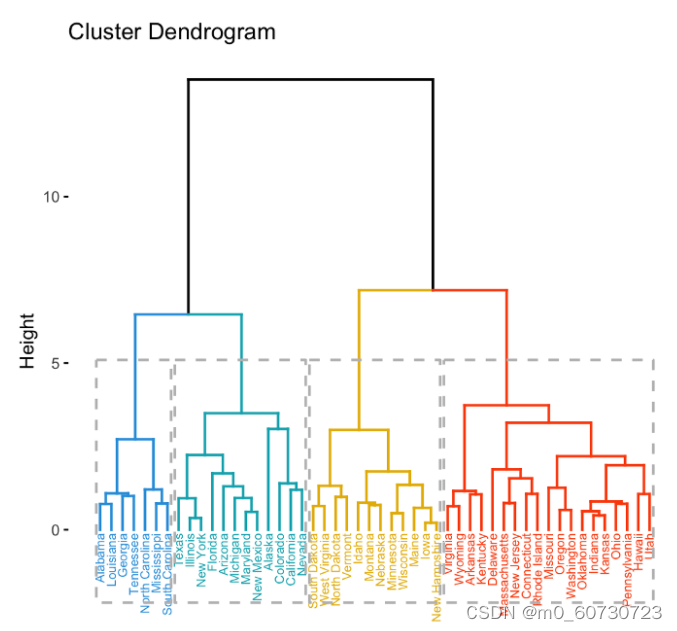
层次聚类(Hierarchical Clustering)
分层聚类是一种类似于基于分区的聚类的聚类方法,但它对数据点进行分类的方式不同。它首先将每个数据点视为一个单独的集群。然后合并彼此最接近的最相似的集群。它不断迭代,直到所有集群合并。
层次聚类的两种类型如下:Agglomerative 和 Divisive
1.凝聚层次聚类(Agglomerative Hierarchical Clustering)
这适用于计算点/簇的邻近矩阵的简单算法。在每次迭代中,它合并最近的点/集群并更新邻近矩阵。这一直持续到形成一个簇或 k 簇。这可以被认为是一种“自下而上”的方法。
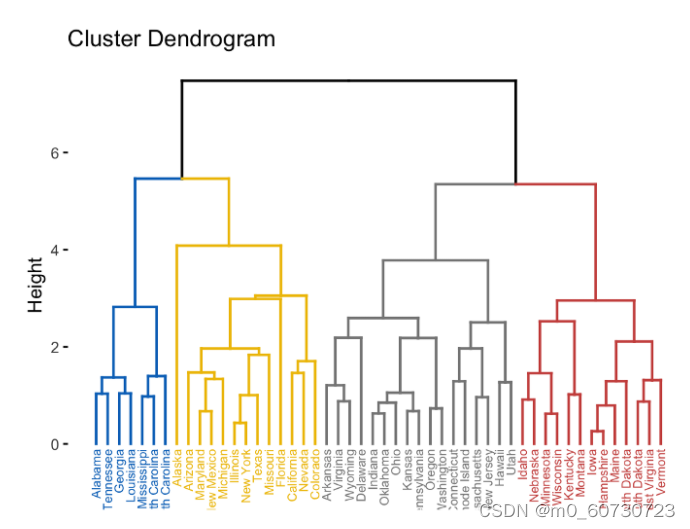
2.分裂层次聚类(Divisive Hierarchical Clustering)
这与凝聚聚类完全相反。在这种方法中,最初,所有数据点都被认为属于一个单一的集群。在每次迭代中,不相似的数据点从集群中分离出来。每个分离的数据点都被视为一个单独的集群。这个过程一直持续到我们有 K 集群。这可以被认为是一种“自上而下”的方法。
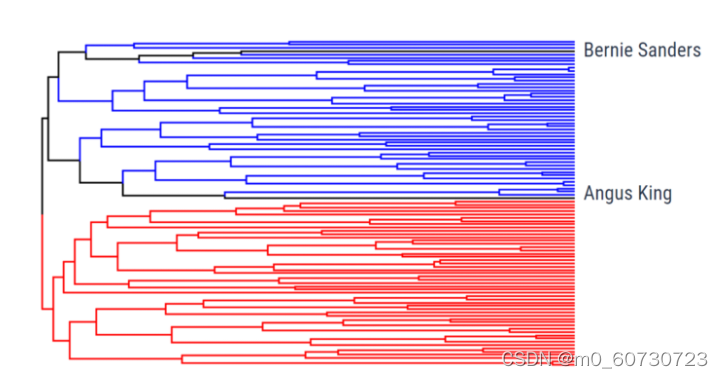
用例:
虽然层次聚类在计算上可能很昂贵,但会产生直观的结果。当对手头的数据知之甚少时,它很有用,因为层次聚类不需要很多假设。层次聚类广泛存在的一种现实场景是在流行病传播期间进行病毒映射以及银行业或零售业的客户细分。
模糊聚类(Fuzzy Clustering)
在模糊 c 均值聚类中,我们找出数据点的质心,然后计算每个数据点与给定质心的距离,直到形成的集群变得恒定。它与基于分区的聚类的不同之处在于,它允许将数据点部分分类为多个聚类。
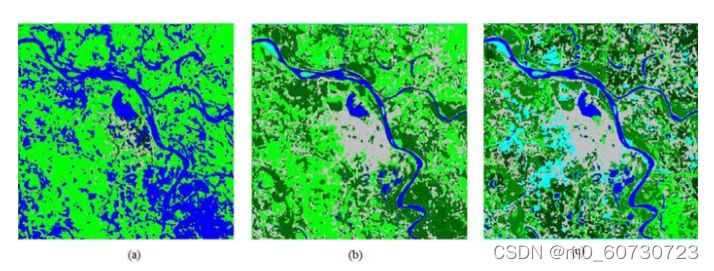
理论上,每个数据点都可以属于所有具有介于 0 和 1 之间的隶属函数的组。0 是数据点离集群中心最远的地方,1 是数据点离中心最近的地方。
用例:
当您需要进行图像分割或您的目标是分割卫星图像中的水、植被和岩石区域时,模糊聚类非常有用。在无法预先确定集群数量的情况下,它很有用。在这种情况下,可以合并具有弱边界的集群。与 K-means 相比,模糊聚类在计算上是昂贵的,因为对于每个点计算它属于每个聚类的概率。
基于密度的聚类(Density-based Clustering)
基于密度的聚类通过对高密度区域进行分组并将它们与低密度区域分开来工作。最著名的基于密度的聚类算法是 DBSCAN 算法(应用噪声的基于密度的空间聚类)
通过使用以下两个参数计算密度
1.EPS:这定义了数据点周围的邻域,即如果两点之间的距离小于或等于 eps,则称它们为邻域
2. MinPts:这定义了形成邻域的最小数据点数。数据集的大小和 MinPts 的值成正比。
DBSCAN 算法访问每个点,如果它在 eps 中包含 MinPts,则集群形成开始。任何其他点都被定义为噪声。这个过程一直持续到形成一个密度连接的簇,然后它从一个新点重新开始。
用例:
DBSCAN 主要用于平面空间的聚类。如果用于绘制自然灾害的影响或绘制城市中气象站的位置,则可以获得良好的效果。当数据由非离散点组成并且有利于处理异常值时,也可以使用此方法。推荐引擎/系统利用 DBSCAN 向客户推荐产品/节目。
基于模型的聚类(Model-Based Clustering)
这种聚类方法使用特定的聚类模型,并尝试优化数据和模型之间的拟合。在基于模型的聚类方法中,数据被视为来自概率分布的混合,每个分布代表一个不同的集群。换句话说,在基于模型的聚类中,假设数据是由概率分布的混合生成的,其中每个分量代表不同的聚类。每个组件(即集群)由正态分布或高斯分布建模。
期望最大化是一种众所周知的基于模型的聚类算法。当数据符合模型时,可以说特定的聚类算法运行良好。
用例:
这在集群具有弱边界并且数据点在集群之间具有混合成员资格的情况下很有用。它在集群协方差方面也更加灵活。在这种情况下,集群分配要灵活得多,并且集群可以根据分布采取任何形状。
参考:
https://towardsdatascience.com/geospatial-clustering-kinds-and-uses-9aef7601f386
欢迎关注我的公众号遥感迷,一起探究学习。


















 1205
1205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









