









本文是应师妹符博士的要求,专门写的科普文章,精通arcpy的同学可以直接跳过了。
前面曾经写了一篇文章,是用Pycluster包的kmeans算法,来实现聚类(前看前面的文章:《使用Pycluster包进行聚类分析实例》),实际上我觉得用R语言会更容易,不过因为“python大法好”的原因,我还是更喜欢这种面向码农的东西。
好了,下面进入正题。
首先你先要确定你安装的pycluster包,能够在ArcGIS环境里面应用,因为ArcMap使用的python环境很复杂,默认是32位,而如果按照了后台64位处理包的话,还可以使用64位的python,所以在使用之前,先要确定你的pycluster包已经被安装到了你的ArcMap用的环境里面,确定的方式如下:
首先要写一个测试脚本,确定你的环境能够使用这个包,方法如下:
建立一个py文件,如我建立的叫做“test.py”的文件,内容如下:
| # -*- coding: cp936 -*- import arcpy try: import Pycluster arcpy.AddMessage("恭喜你,可用哦") except: arcpy.AddError("狗带了") |
这个脚本的意思,就是直接导入Pycluster包,如果导入成功,就在你的ArcGIS的通知窗体上显示可用,否则就用大红色的字体显示狗带。。。
然后把这个脚本,添加到你的ArcToolbox里面去,添加的方式如下:
随便找一个toolbox(当然是自己建的),点右键,选择add——Scrtip
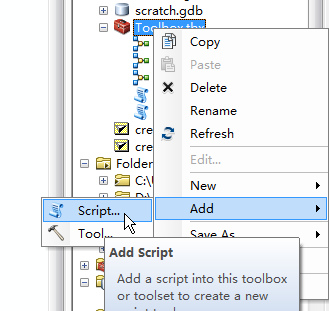
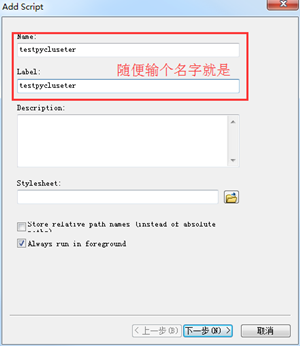
接下去,随便取个名字:然后点下一步
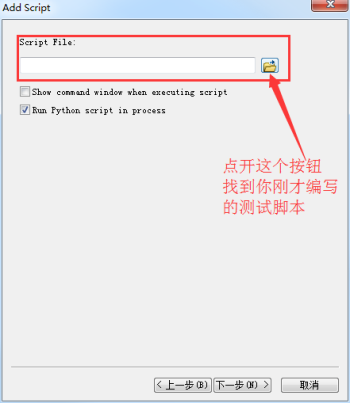
把你刚才编写的测试脚本扔进去:
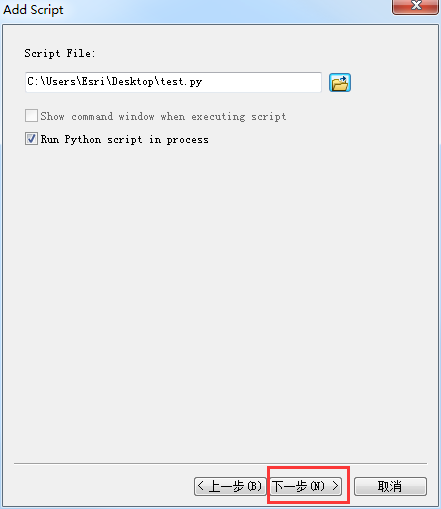
找到之后,直接下一步到结束,因为测试脚本,不用设置任何的参数:
然后你会发现你的toolbox里面出现了这样一个文件,然后点击运行即可:
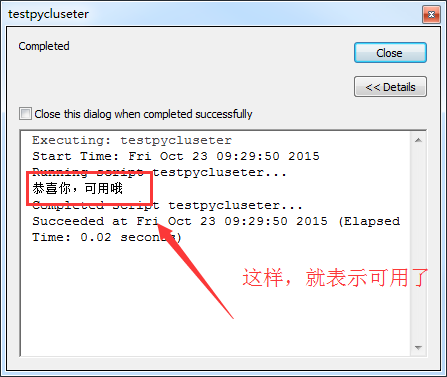
但是,如果你安装的不对付,也可能出现这样的提示:
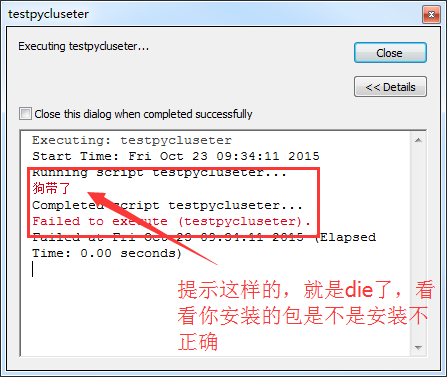
如果你的包可用,那就可以进入第二阶段了。
先看看数据的描述:
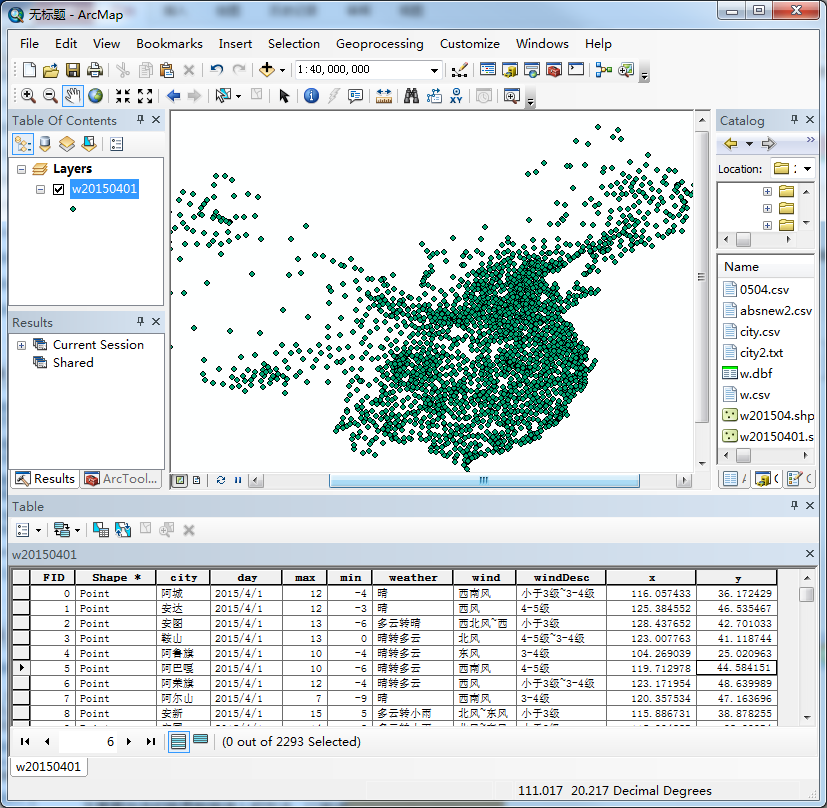
数据在我后面提供的文件包里面,会给大家,一共2293条,是全国2293个气温测站点在2015年4月1日的数据,那么我们要用的,是max(最高温度),min(最低温度)这两个字段进行聚类分析,后面的xy是用来在matplotlib中画图的,如果仅需要再ArcMap中做,不用通过matplotlib绘制出来,那么这两经纬度就不用了。
接下去,我们看看具体的流程,之前先要看原来的脚本里面需要的内容:
主要要改造的就是数据读入的方法,以前读入的方式是这样的:
data = np.loadtxt(filename, delimiter = ",",usecols=(3,4))
xy = np.loadtxt(filename, delimiter = ",",usecols=(8,9))
现在要改成从featrue或者shapefile里面读入这四个信息,(上面说了,如果就在ArcMap中做,后面xy就不用读了)那么读的方式主要是通过arcpy的da包中的SearchCursor接口来读,读的方式如下:
| with arcpy.da.SearchCursor(infeat, ['max','min',"x","y"]) as cursor: for row in cursor: data.append([row[0],row[1]]) xy.append([row[2],row[3]]) |
读完之后,用这个方法来写:
| with arcpy.da.UpdateCursor(outFeat,"classFNum") as cursor: f = 0 for row in cursor: row[0] = clustermap[f] f+=1 cursor.updateRow(row) |
具体的说明,有兴趣的同学去看ArcGIS的帮助文档。
全部代码如下:
| # -*- coding:utf-8 -*-
''' Created on 2015-10-23 @author: godxia ''' import Pycluster as pc import numpy as np import matplotlib.pylab as pl import arcpy def myCKDemo(infeat,n,outFeat):
#这一段是从shapefile里面,读取需要的数据 data = [] xy = [] with arcpy.da.SearchCursor(infeat, ['max','min',"x","y"]) as cursor: for row in cursor: data.append([row[0],row[1]]) xy.append([row[2],row[3]])
#下面这段是使用Pycluster包的方法不解释了。 clustermap = pc.kcluster(data, n)[0] centroids = pc.clustercentroids(data, clusterid=clustermap)[0] m = pc.distancematrix(data) mass = np.zeros(n) for c in clustermap: mass[c] += 1 sil = np.zeros(n*len(data)) sil.shape = ( len(data), n ) for i in range( 0, len(data) ): for j in range( i+1, len(data) ): d = m[j][i] sil[i, clustermap[j] ] += d sil[j, clustermap[i] ] += d for i in range(0,len(data)): sil[i,:] /= mass s=0 for i in range( 0, len(data)): c = clustermap[i] a = sil[i,c] b = min(sil[i,range(0,c)+range(c+1,n)]) si = (b-a)/max(b,a) s+=si
arcpy.AddMessage("Classification Number:%d \nSilhouette Coefficient:%f"%(n, s/len(data)))
#下面这段,是调用arcpy的写入功能,生成一个新的图层,并且把分类信息写进去 #copy一个完全一样的图层 arcpy.CopyFeatures_management(infeat,outFeat) #添加一个字段,用来记录类别 arcpy.AddField_management(outFeat,"classFNum","SHORT")
with arcpy.da.UpdateCursor(outFeat,"classFNum") as cursor: f = 0 for row in cursor: row[0] = clustermap[f] f+=1 cursor.updateRow(row)
#以下这段是用matplotlib绘图 fig, ax = pl.subplots() cmap = pl.get_cmap('jet', n) cmap.set_under('gray') x = [list(d)[0] for d in xy] y = [list(d)[1] for d in xy] cax = ax.scatter(x, y, c=clustermap, s=30, cmap=cmap, vmin=0, vmax=n) pl.show()
if __name__ == '__main__': #以下是从ArcMap中获取参数,相关说明参考帮助文档 inFeat = arcpy.GetParameterAsText(0) n = int(arcpy.GetParameterAsText(1)) outFeat = arcpy.GetParameterAsText(2) myCKDemo(inFeat,n,outFeat) |
全部写完之后,把这个脚本封装到toolbox里面,封装的过程如下:
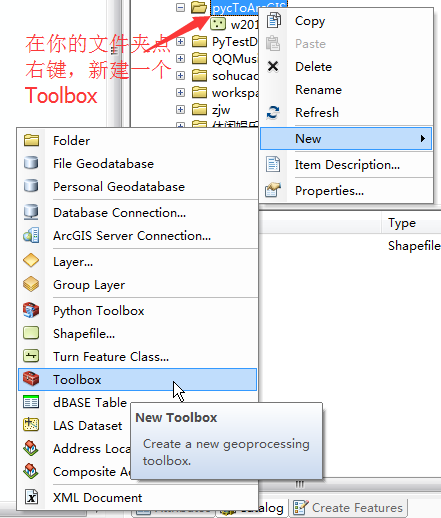
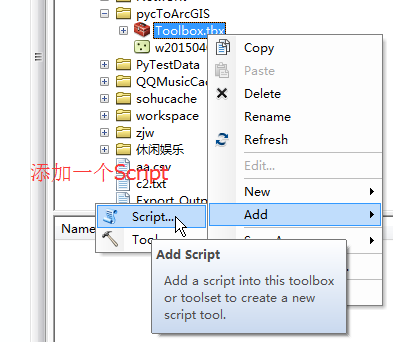
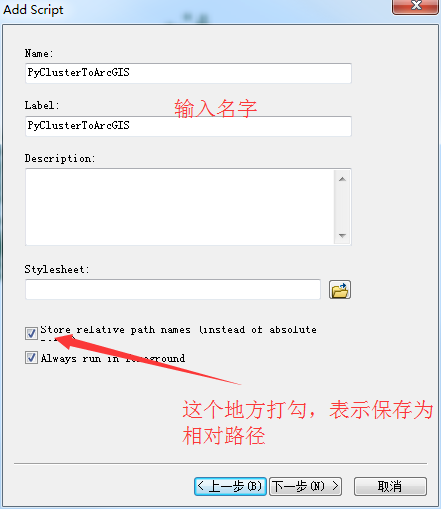
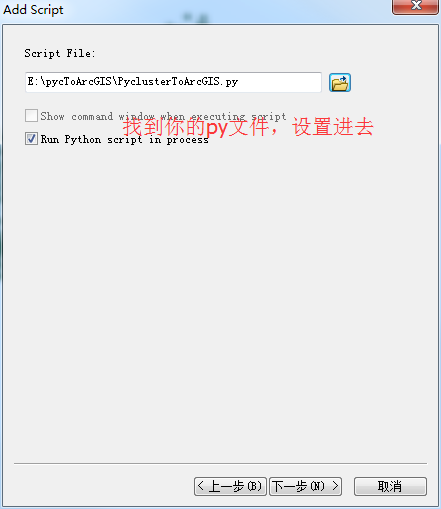
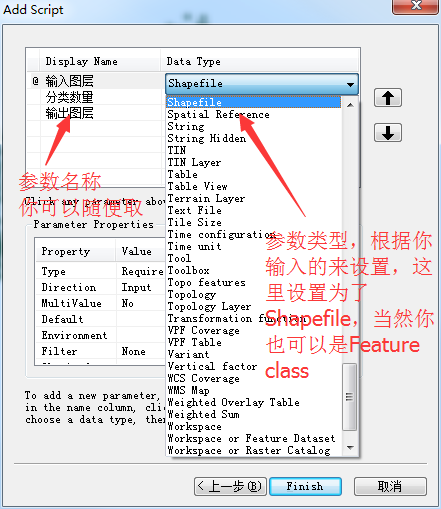
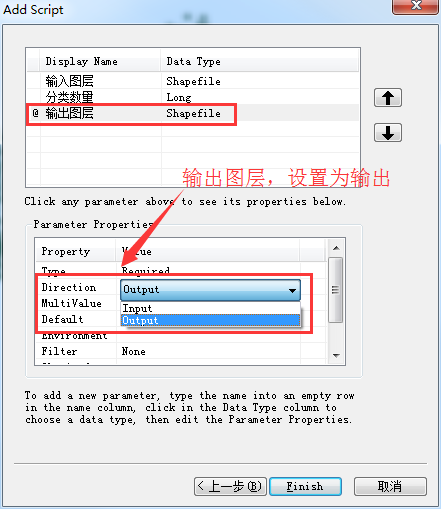
封装完成之后,如下:
双击运行这个脚本工具,如下:
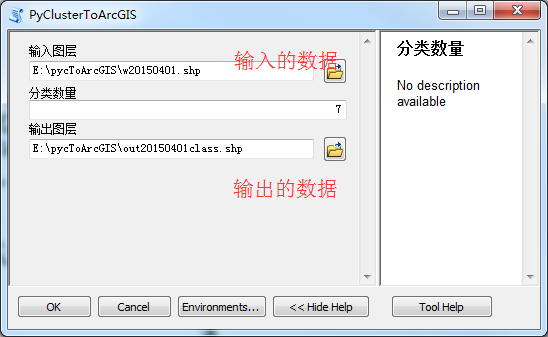
完成之后,点击OK
运行之后,会在运行的过程中弹出你用matplotlib画的图。
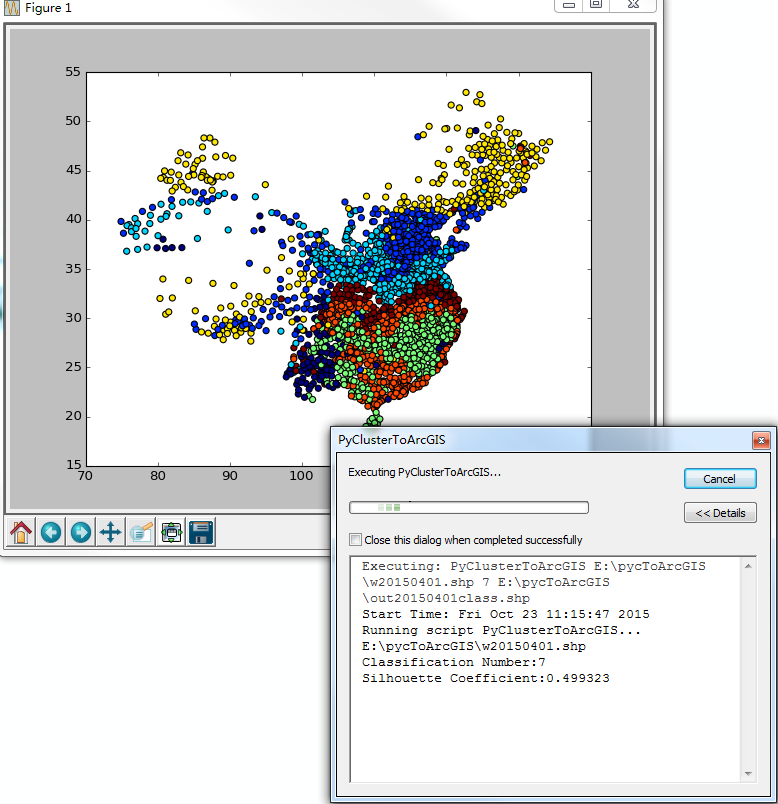
千万注意:在关闭matplotlib的图形之前,工具的运行是暂停状态的,一定要关闭matplotlib,才能够继续运行下去,否则就一直卡在这里了。
最后,运行完成,生成了一个新的图层,可以进行可视化了(类别和颜色自己调整):
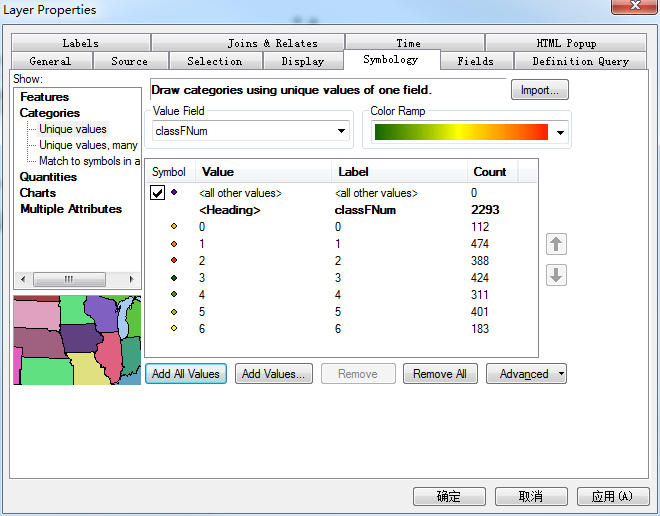
结果如下:
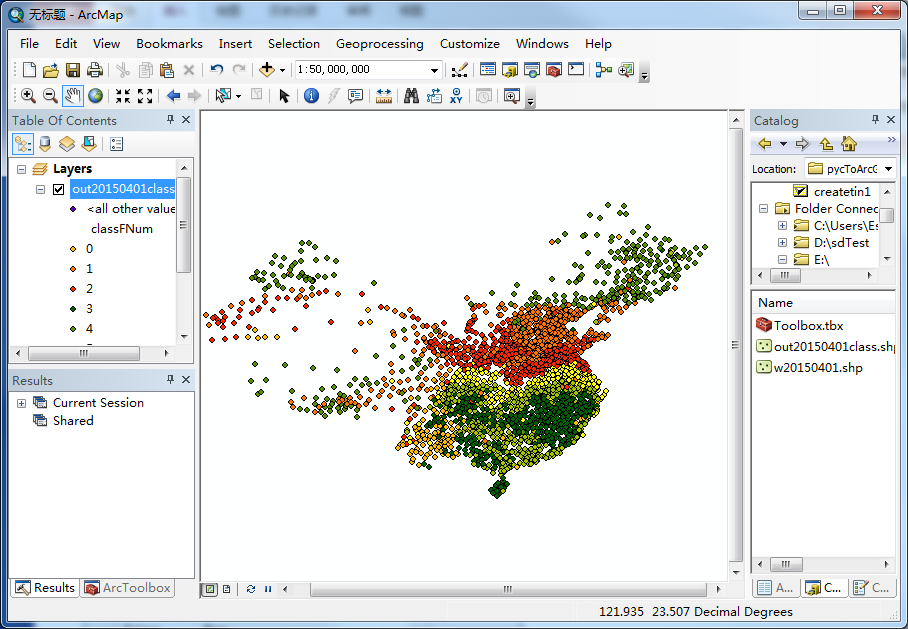
最后,贴出源码和数据以及工具的云盘地址:
链接:http://pan.baidu.com/s/1pJKjbbP 密码:l1k7
注意,我的工具是在ArcGIS10.3.1下面封装的,如果打不开,就根据上面的内容自己封装,然后脚本肯定是打得开的。
另外,脚本的arcpy.da包,必须是ArcGIS 10.1及以上版本才能使用,10的版本自己去改造。
















 1338
1338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











