







XML作为一种通用的数据交换格式,应用越来越广泛。目前许多系统的配置文件都使用XML格式,本书中所涉及到的众多配置文件都是XML格式的,新的JSP规范也推出了采用XML语法的JSP文档,因此,要深入学习和掌握Java Web开发技术,必须有一些基本的XML语言知识。由于XML的通用性和广泛应用,在读者以后实际项目开发和应用中,很多地方都要用到XML方面的知识,所以,对XML知识的了解和掌握,已经是从事电子商务网站和相关系统开发的编程人员所必须掌握的基本知识。
F指点迷津:什么是配置文件
配置文件就是记录应用程序的配置信息的文件。例如,某个程序要连接网络上的数据库系统时,需要指定数据库服务器的ip地址、服务器的网络监听端口号、数据库的名称、用户名和密码等信息,这些信息可以作为应用程序的配置信息来对待,即不要将这些信息写死在源程序中,而是写在一个文本文件中。应用程序要连接数据库系统时,从该文本文件中读取所需要的信息,如果连接的数据库系统的信息发生了改变,则只需要修改该文本文件,而不用修改源程序,这个文本文件就是应用程序的配置文件。传统的配置文件通常采用如下格式:
#Db.Properties
DBServer=192.168.0.100
Port=1443
Database=emp
Username=zxx
Password=123
上面这种格式的配置文件只能表述一些简单的信息,而很难表达具有层次结构和数据项目要动态增加的信息。例如,如果要在一个文件中表达出“一个国家中的每个省及省长的名称、每个省下面的每个市及市长的名称、每个市下面的每个镇及镇长名称”,使用上面的格式就很难表达。采用XML格式的配置文件很容易表达出这种层次结构,具体细节请参看本章后面部分的讲解。
文档声明
在一个完整的XML文档中必须包含一个XML文档声明,该声明必须位于文档的第一行。这个声明表示该文档是一个XML文档,以及遵循的是哪个XML版本的规范。最简单的XML文档声明语法如下:
<?xml version="1.0" ?>
在“<”和“?”之间、“?”和“>”之间以及第一个“?”和xml之间不能有空格,这就是XML语法严格性的一个体现。在第二个“?”之前可以没有、也可以有一个或多个空格。声明语句中的version属性表示XML的版本,因为解析器对不同的版本的解析肯定会有区别,尽管目前只有1.0版本,但在声明中必须指定version属性。
由于人们可以采用不同的字符编码集来书写一个字符内容完全相同的XML文档,所以,XML软件工具(包括分析器)就需要知道该XML文档所使用的字符编码方式。这可以通过在XML文档声明中指定encoding属性来说明,例如,使用下面的语句来指明文档中的字符编码方式为GB2312编码。
<?xml version="1.0" encoding="GB2312" ?>
W3C的XML1.0规范里规定,所有的XML解析器必须接受UTF-8和UTF-16编码的Unicode字符,所以,符合 XML 规范的软件工具一定都支持这两种Unicode编码。如果XML声明中没有设置encoding属性来明确指定文档所用的字符编码方式,则一律以Unicode编码看待。XML解析器通过寻找XML文档开始处的字节顺序标记,能够自动检测出文档中的Unicode编码是UTF8,还是UTF16。也就是说,encoding属性默认的设置是Unicode编码,如果文档中的字符是以UTF-8或者是UTF-16作为编码,则可以不设置这个属性。
在XML文档声明语句中,还可以指定另外一个可选属性:standalone,例如:
<?xml version="1.0" encoding="UTF-8" standalone="yes" ?>
standalone属性用于说明文档是否是独立的,如果将其设置为“yes”,则表示该文档没有依赖外面的任何文件而可以独立存在,即不需要DTD文件来验证其中的标识是否有效,也不需要XSL、CSS文件来控制其显示外观;将standalone属性设置为“no”时,则表示该文档依赖于外面的某个文件,例如,依赖于某个DTD文件或XSL、CSS文件。standalone属性的默认值为“yes”。
注意:如果同时设置了encoding和standalone属性,standalone属性要位于encoding属性之后。
:动手体验:加深对encoding属性的理解
对于含有中文字符的XML,其中的字符可以采用unicode来编码或GB2312(简体中文字符编码)编码来表示,如果文档中的字符使用的是GB2312编码,则必需设置为encoding属性为GB2312,下面通过一个实验来说明这个问题。
(1)用Windows自带的记事本程序创建一个名为book.xml的文件,文件内容如例程1-1所示。
例程1-1 book.xml
<?xml version="1.0" ?>
<书架>
<书>
<书名>Java就业培训教程</书名>
<作者>张孝祥</作者>
<售价>39.00元</售价>
</书>
<书>
<书名>JavaScript网页开发</书名>
<作者>张孝祥</作者>
<售价>28.00元</售价>
</书>
</书架>
(2)用IE5.0以上的浏览器打开book.xml文件,看到的结果如图1.2所示。
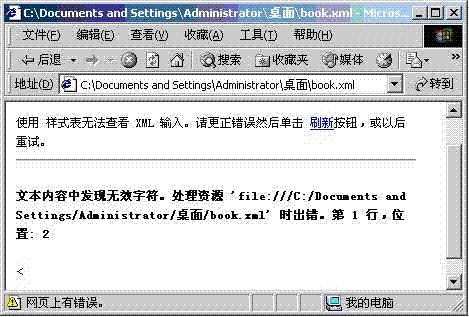
错误提示的信息是“文本内容中发现无效字符”,这就是因为在book.xml的XML文档声明语句中没有明确指定文档中的字符编码方式,浏览器就会用默认的Unicode编码来解析该文档,而该文档中的字符实际上使用的是GB2312编码,而非Unicode编码。
(3)单击浏览器的“查看”à“源文件”菜单,将打开的book.xml文件内容中的第一行修改成如下形式:
<?xml version="1.0" encoding="GB2312" ?>
保存修改后,刷新显示book.xml文件的浏览器窗口,看到的结果如图1.3所示。单击某个标签前面的减号(-),嵌套在该标签中的所有内容将被折叠起来,标签前面的减号(-)也将变成加号(+)。单击某个标签前面的加号(+),嵌套在该标签中的所有内容将被展开,标签前面的加号(+)也将变成减号(-)。
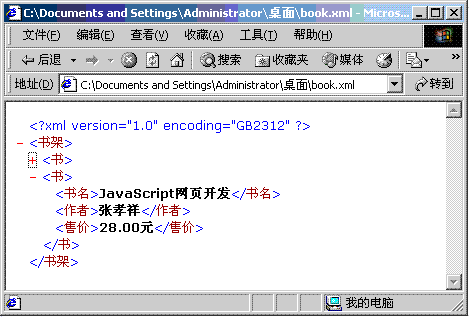
(4)在上面打开book.xml文件的记事本程序中,单击“文件”à“另存为”菜单,在打开的“另存为”对话框中,选择“保存类型”为“所有文件”,编码为“UTF-8”,如图1.4所示。

以UTF-8编码保存book.xml文件后,尽管在记事本程序窗口中显示的效果没有任何变化,但是book.xml文件内部存储的数据已经改变,这通过比较book.xml保存前后的文件大小就可以看出来。刷新显示book.xml文件的浏览器窗口,看到的结果如图1.5所示。
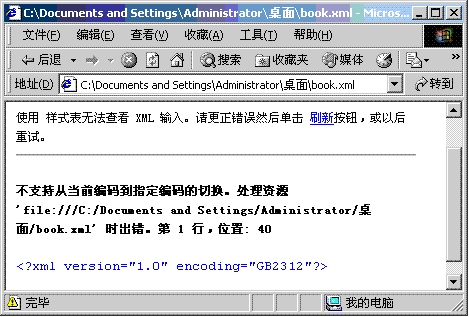
因为现在的book.xml文件的字符编码已经转换为UTF-8,而文档的起始声明中指定encoding属性为GB2312,所以,浏览器在解析book.xml文件时会发生错误。
(5)将book.xml的文档起始声明的encoding属性修改为UTF-8,保存后刷新显示book.xml文件的浏览器窗口,就又可以看到类似图1.3所示的正常显示效果了。
Trackback: http://tb.blog.csdn.net/TrackBack.aspx?PostId=760127















 379
379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









