




 本文介绍了贝叶斯网络,它是贝叶斯分类算法的一种,区别于朴素贝叶斯算法的独立假设,贝叶斯网络允许属性之间的关联。文章通过举例说明了贝叶斯网络在处理关联问题上的优势,并提供了计算概率的公式及代码实现链接,帮助读者深入理解这一算法。
本文介绍了贝叶斯网络,它是贝叶斯分类算法的一种,区别于朴素贝叶斯算法的独立假设,贝叶斯网络允许属性之间的关联。文章通过举例说明了贝叶斯网络在处理关联问题上的优势,并提供了计算概率的公式及代码实现链接,帮助读者深入理解这一算法。
前言
一看到贝叶斯网络,马上让人联想到的是5个字,朴素贝叶斯,在所难免,NaiveByes的知名度确实会被贝叶斯网络算法更高一点。其实不管是朴素贝叶斯算法,还是今天我打算讲述的贝叶斯网络算法也罢,归根结底来说都是贝叶斯系列分类算法,他的核心思想就是基于概率学的知识进行分类判断,至于分类得到底准不准,大家尽可以自己用数据集去测试测试。OK,下面进入正题--贝叶斯网络算法。
朴素贝叶斯
一般我在介绍某种算法之前,都事先会学习一下相关的算法,以便于新算法的学习,而与贝叶斯网络算法相关性比较大的在我看来就是朴素贝叶斯算法,而且前段时间也恰好学习过,简单的来说,朴素贝叶斯算法的假设条件是各个事件相互独立,然后利用贝叶斯定理,做概率的计算,于是这个算法的核心就是就是这个贝叶斯定理的运用了喽,不错,贝叶斯定理的确很有用,他是基于条件概率的先验概率和后验概率的转换公式,这么说有点抽象,下面是公式的表达式:
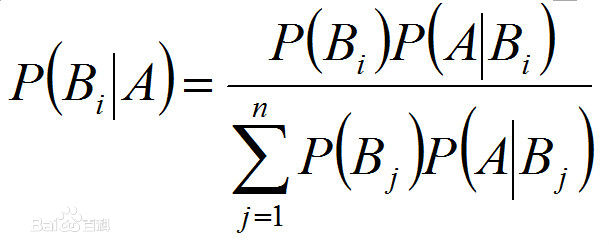
大学里概率学的课本上都有介绍过的,这个公式的好处在于对于一些比较难直接得出的概率通过转换后的概率计算可得,一般是把决策属性值放在先验属性中,当做目标值,然后通过决策属性值的后验概率计算所得。具体请查看我的朴素贝叶斯算法介绍。
贝叶斯网络
下面这个部分就是文章的主题了,贝叶斯网络,里面有2个字非常关键,就是网络,网络代表的潜在意思有2点,第一是有结构的,第二存在关联,我们可以马上联想到DAG有向无环图。不错,存在关联的这个特点就是与朴素贝叶斯算法最大的一个不同点,因为朴素贝叶斯算法在计算概率值上是假设各个事务属性是相互独立的,但是理性的思考一下,其实这个很难做到,任何事务,如果你仔细去想想,其实都还是有点联系的。比如这里有个例子:
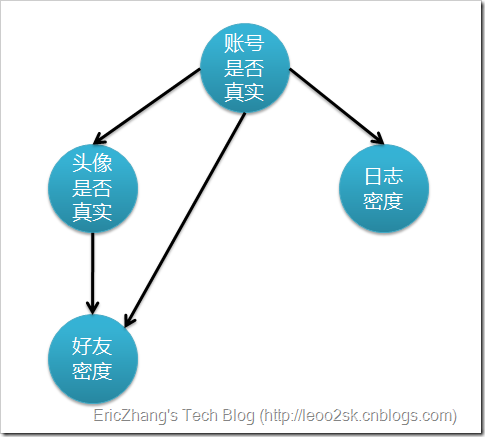
在SNS社区中检验账号的真实性
如果用朴素贝叶斯来做的话,就会是这样的假设:
i、真实账号比非真实账号平均具有更大的日志密度、各大的好友密度以及更多的使用真实头像。
ii、日志密度、好友密度和是否使用真实头像在账号真实性给定的条件下是独立的。
但是其实往深入一想,使用真实的头像其实是会提高人家添加你为好友的概率的,所以在这个条件的独立其实是有问题的,所以在贝叶斯网络中是允许关联的存在的,假设就变为如下:
i、真实账号比非真实账号平均具有更大的日志密度、各大的好友密度以及更多的使用真实头像。
ii、日志密度与好友密度、日志密度与是否使用真实头像在账号真实性给定的条件下是独立的。
iii、使用真实头像的用户比使用非真实头像的用户平均有更大的好友密度。
在贝叶斯网络中,会用一张DAG来表示,每个节点代表某个属性事件,每条边代表其中的条件概率,如下:
贝叶斯网络概率的计算
贝叶斯网络概率的计算很简单,是从联合概率分布公式中变换所得,下面是联合概率分布公式:
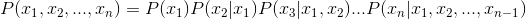
而在贝叶斯网络中,由于存在前述的关系存在,该公式就被简化为了如下:<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








