







http://antkillerfarm.github.io/
贝叶斯统计和规则化(续)
p(θ|S) 可由前面的公式得到。
假若我们要求期望值的话,那么套用求期望的公式即可:
由上可见,贝叶斯估计将 θ 视为随机变量, θ 的值满足一定的分布,不是固定值,我们无法通过计算获得其值,只能在预测时计算积分。
上述贝叶斯估计方法,虽然公式合理优美,但后验概率 p(θ|S) 通常是很难计算的,因为它是 θ 上的高维积分函数。
观察 p(θ|S) 的公式,在分母 P(S) 一定的情况下,分子越大则值越大,也就是 p(θ|S) 的概率越大。
因此,可得如下算法:
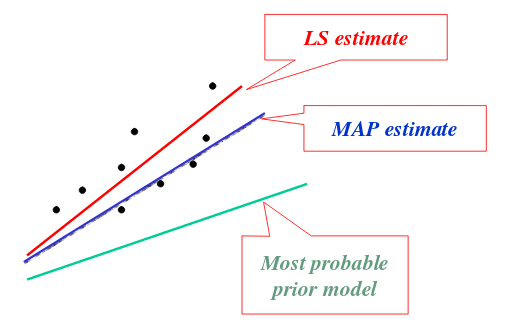
这个算法叫做最大后验概率估计(maximum a posteriori)。
和ML相比,MAP算法只是在最后多了一项 p(θ) 。通常使用中,我们认为 p(θ) 符合 θ∼N(0,τ2I) 。
由于 p(θ) 实际上就是先验分布,它会对最后结果进行一定的修正。因此,实际上最大后验概率估计相对于最大似然估计来说,较容易克服过度拟合的问题。
参见:
http://www.cs.cornell.edu/courses/cs5540/2010sp/lectures/Lec9.Estimation-continued.pdf
在线学习
我们之前讨论的算法,都是给定一个训练集S,经训练之后,得到预测函数h,然后再在新的样本集上进行预测。这种方法被称为批量学习(batch learning)。
与之相对的,还有一种边学习边预测的在线学习(online learning)算法。其步骤如下:
1. i:=0 。
2.输入 x(i) ,算法预测 y(i) 。
3.根据 y(i) 的真实值,修正算法模型。这一步也被称作更新过程(update procedure)
4.令 i:=i+1 ,以处理下一个数据样本。
在线学习的优点:
1.算法在学习过程中,即可预测。
2.随着数据样本的增多,预测会更加准确,即具有自我完善的的能力。
下面以感知器(perceptron)算法为例,讨论一下在线学习的误差问题。
首先回忆一下感知器算法:
对于训练样本 (x,y) ,其更新过程为:
这里给出一个和感知器算法有关的定理:
对于给定的m个样本序列(注意“序列”二字,在线算法对于样本的顺序是敏感的) x(i) ,如果所有的 ∥x(i)∥≤D ,并且存在单位向量u,使得所有样本的 y(i)(uTx(i))≥γ ,则感知器算法在该序列上的预测错误个数最多为 (D/γ)2 。
这个定理是Henry David Block和Albert B. J. Novikoff于1962年提出的。
注:Henry David Block,1920~1978,美国数学家。
这个人的经历有点非典型。20岁本科毕业,由于专业是文学和心理学,结果找不到工作。只好回炉,又读了个土木工程的本科。
二战期间在Goodyear的飞机工厂(没错就是那个卖轮胎的Goodyear)担任测试工程师。在那里碰到一个当医生的英国妹子,搞定之。
1946年,他老婆在Iowa State University获得了一个职位,于是他也跟着搬了过去。估计是无所事事,他经常到大学里蹭课,然后就发现自己对数学很感兴趣。
于是继续读书,1949年拿到博士学位。经过几年助教生涯之后,最终成为康奈尔大学应用数学教授。
话说,根据缩写找人真是太痛苦了,很多资料都不是你要找的人,Block又是个大路货。我最后是在他的一位同事的论文中找到他的全名的。那篇论文发表于1985年,距离他去世已经7年,但他仍是作者之一,可见人缘不错。Albert B. J. Novikoff,全名不详,只知道是纽约大学教授。从岁数来看应该已经退休了。
下面给出这个定理的证明过程:
由公式1可知, θ 的值只有在发生预测错误的时候才会改变,因此我们可以使用 θ(k) 表示第k个错误。同时令 θ1=0 。
根据更新公式可得:
所以:
由数学归纳法可得:
另外,
由感知器算法的定义可得:
所以:
同样,由数学归纳法可得:
因为:
由公式2、3、4可得:
所以:
K-Means算法
聚类算法属于无监督学习算法的一种。它的训练样本中只有 x(i) ,而没有 y(i) 。聚类的目的是找到每个样本x潜在的类别y,并将同类别y的样本x放在一起,形成一个聚类(clusters)。样本 x(i) 所属的聚类用 c(i) 表示。
K-Means算法的步骤如下:
1.随机选取k个聚类质心点(cluster centroids) μ1,…,μk
2.重复下面过程直到收敛 {
对于每一个样例i,计算其应该属于的聚类: c(i):=argminj∥x(i)−μj∥2
对于每一个聚类j,重新计算该聚类的质心: μj:=∑mi=11{c(i)=j}x(i)∑mi=11{c(i)=j} 。
}
其中,k是我们事先定义的聚类个数。下图展示了对n个样本点进行K-means聚类的效果,这里k取2。

K-means算法面对的第一个问题是如何保证收敛。前面的算法中强调结束条件就是收敛,可以证明的是K-means完全可以保证收敛性。下面我们定性的描述一下收敛性,我们定义畸变函数(distortion function)如下:
J函数表示每个样本点到其质心的距离平方和。K-means算法的目的是要将J调整到最小。假设当前J没有达到最小值,那么首先可以固定每个类的质心 μj ,调整每个样例的所属的类别 c(i) 来让J函数减小,同样,固定 c(i) ,调整每个类的质心 μj ,也可以使J减小。 这两个过程就是内循环中使J单调递减的过程。当J递减到最小时, μ 和c也同时收敛。(在理论上,可以有多组不同的 μ 和c值,能够使得J取得最小值,但这种现象实际上很少见。)
由于畸变函数J是非凸函数,意味着我们不能保证算法取得的最小值是全局最小值,也就是说k-means对质心初始位置的选取比较敏感。但一般情况下k-means达到的局部最优已经满足需求。但如果你怕陷入局部最优,那么可以选取不同的初始值跑多遍k-means,然后取其中最小的J对应的 μ 和c输出。
参考:
http://www.csdn.net/article/2012-07-03/2807073-k-means
http://www.cnblogs.com/leoo2sk/archive/2010/09/20/k-means.html
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006910.html
高斯混合模型和EM算法
本篇讨论使用期望最大化算法(Expectation-Maximization)进行密度估计(density estimation)。
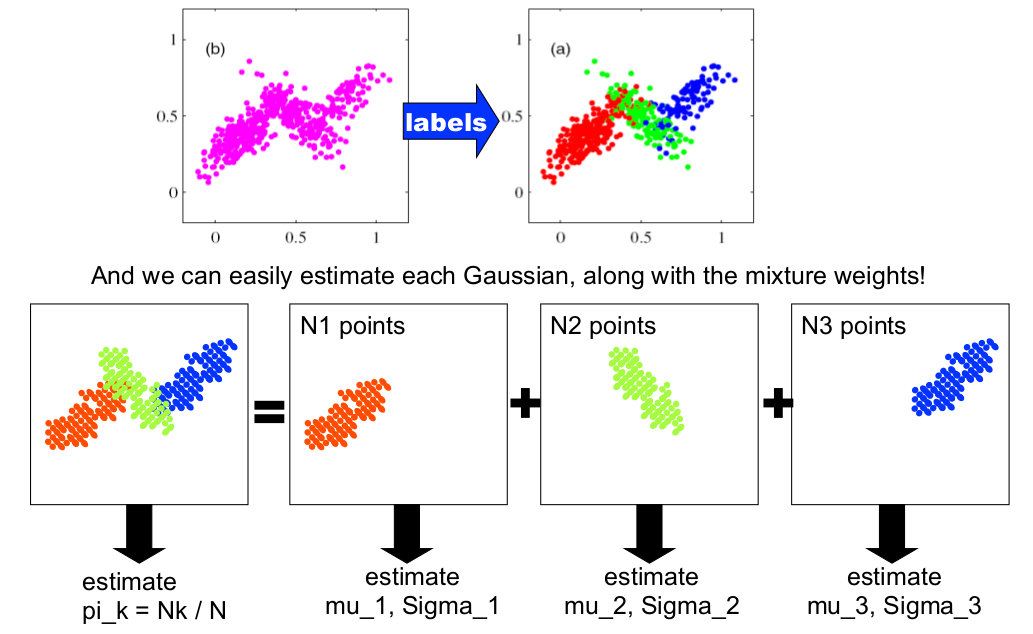
从上面的讨论可以形象的看出,聚类问题实际就是在数据集上,找出一个个数据密度较高的“圆圈”。我们可以反过来思考这个问题:如果我们已知圆圈的圆心和半径,那么也可以根据圆心、半径以及样本分布模型,来随机生成这些数据。显然,这和前一种做法在效果上是等效的。
首先我们假设样本数据满足联合概率分布
其中, z(i)∼Multinomial(ϕ) (这里的 ϕj=p(z(i)=j) ,因此 ϕj≥0,∑kj=1ϕj=1 ), z(i) 的值为k个聚类之一。
假定 x(i)|z(i)=j∼N(μj,Σj) ,则该模型被称为高斯混合模型(mixture of Gaussians model)。
整个模型简单描述为对于每个样例 x(i) ,我们先从k个类别中按多项分布抽取一个 z(i) ,然后根据 z(i) 所对应的k个多值高斯分布中的一个生成样例 x(i) 。注意的是这里的 z(i) 是隐含的随机变量(latent random variables)。
因此,由全概率公式可得:
该模型的对数化似然函数为:
这个式子的最大值不能通过求导数为0的方法解决的,因为它不是close form。(多项分布的概率密度函数包含阶乘运算,不满足close form的定义。)
为了简化问题,我们假设已经知道每个样例的 z(i) 值。这实际上就转化成《机器学习(二)》所提到的GDA模型。和之前模型的区别在于, z(i) 是多项分布,而且每个聚类的 Σ 都不相同,但结论是类似的。
这里的直接推导非常复杂,可参考以下文章:
http://www.cse.psu.edu/~rtc12/CSE586/lectures/EMLectureFeb3.pdf
上面这篇文章比较直观,比Andrew讲义的Problem Set详细的多。然而Andrew这样写是有原因的,在后面的章节,借助Jensen不等式,Andrew给出一个更简单且一般化的推导过程。
接下来的问题就是: z(i) 的值我们是不知道的,该怎么办呢?
EM算法的思路是:
1.猜测 z(i) 的值。(这一步即所谓的Expectation,简称E-Step。)
2.最大化计算,以更新模型的参数。(这一步即所谓的Maximization,简称M-Step。)
具体到这里就是:
Repeat until convergence {
(E-step) For each i, j:
w(i)j:=p(z(i)=j|x(i);ϕ,μ,Σ)
(M-step) Update the parameters:
ϕj:=1m∑mi=1w(i)j
μj:=∑mi=1w(i)jx(i)∑mi=1w(i)j
Σj:=∑mi=1w(i)j(x(i)−μj)(x(i)−μj)T∑mi=1w(i)j
}















 3105
3105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









