









 本文介绍了Hadoop1.0与2.0时期的架构变化,详细解析了HDFS的工作原理及其组件功能,包括NameNode、SecondaryNameNode及DataNode的角色与职责。同时涵盖了MapReduce的基本概念及其特性,以及YARN架构的作用。此外,还介绍了基于Hadoop的数据仓库Hive和分布式数据库HBase,并概述了Hadoop的开源发行版。
本文介绍了Hadoop1.0与2.0时期的架构变化,详细解析了HDFS的工作原理及其组件功能,包括NameNode、SecondaryNameNode及DataNode的角色与职责。同时涵盖了MapReduce的基本概念及其特性,以及YARN架构的作用。此外,还介绍了基于Hadoop的数据仓库Hive和分布式数据库HBase,并概述了Hadoop的开源发行版。
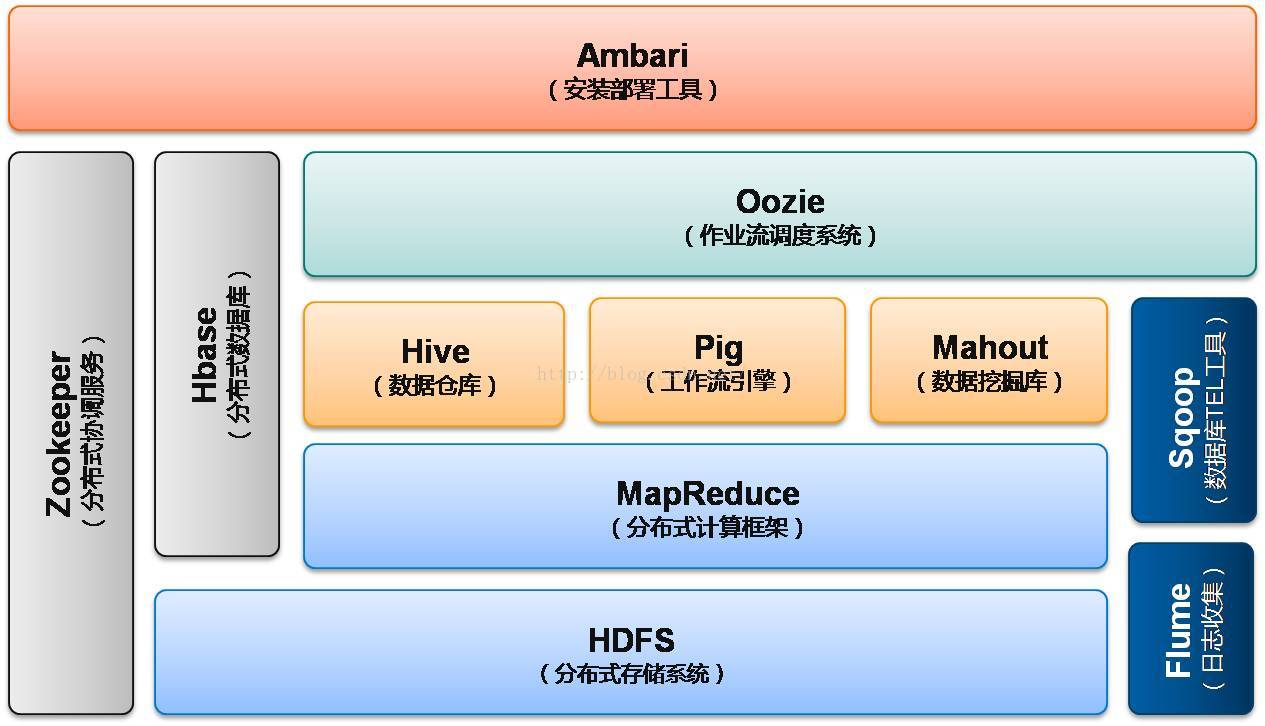
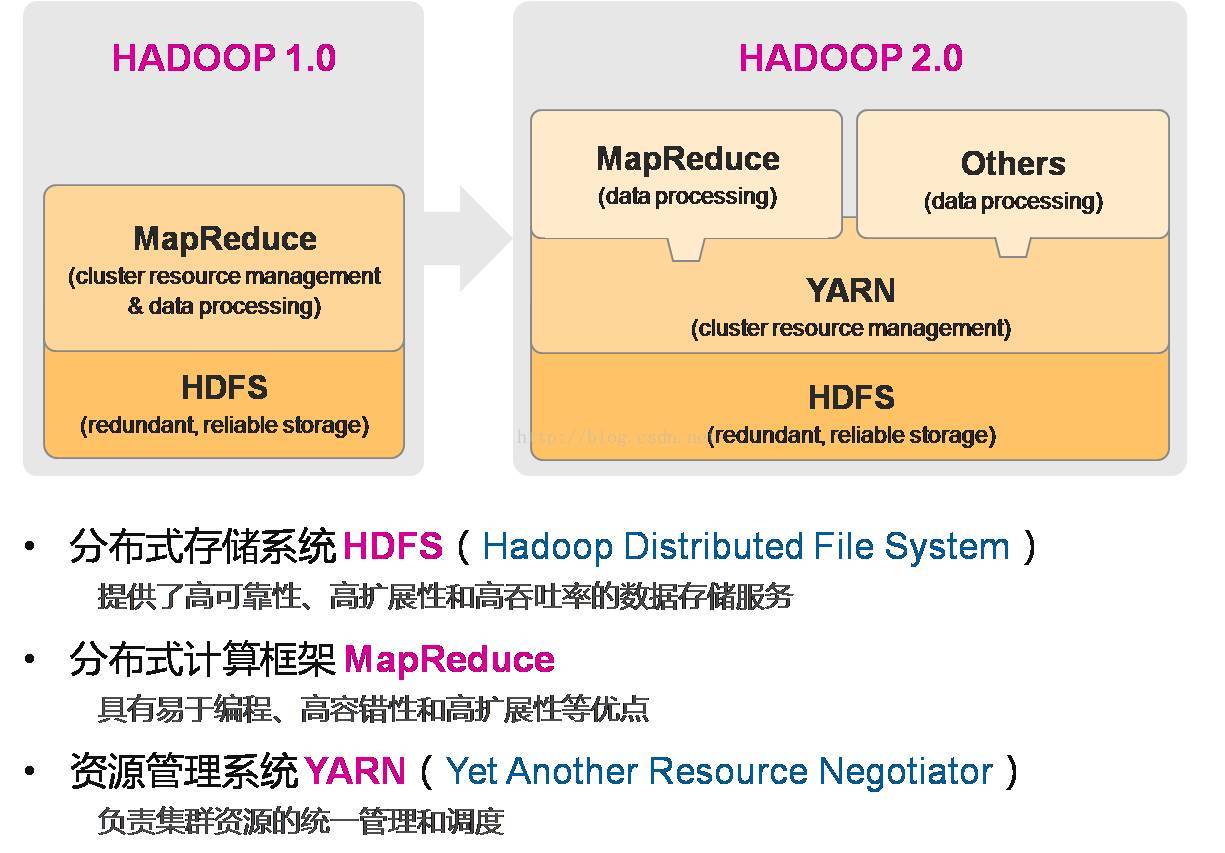
1、hadoop1.0时期架构
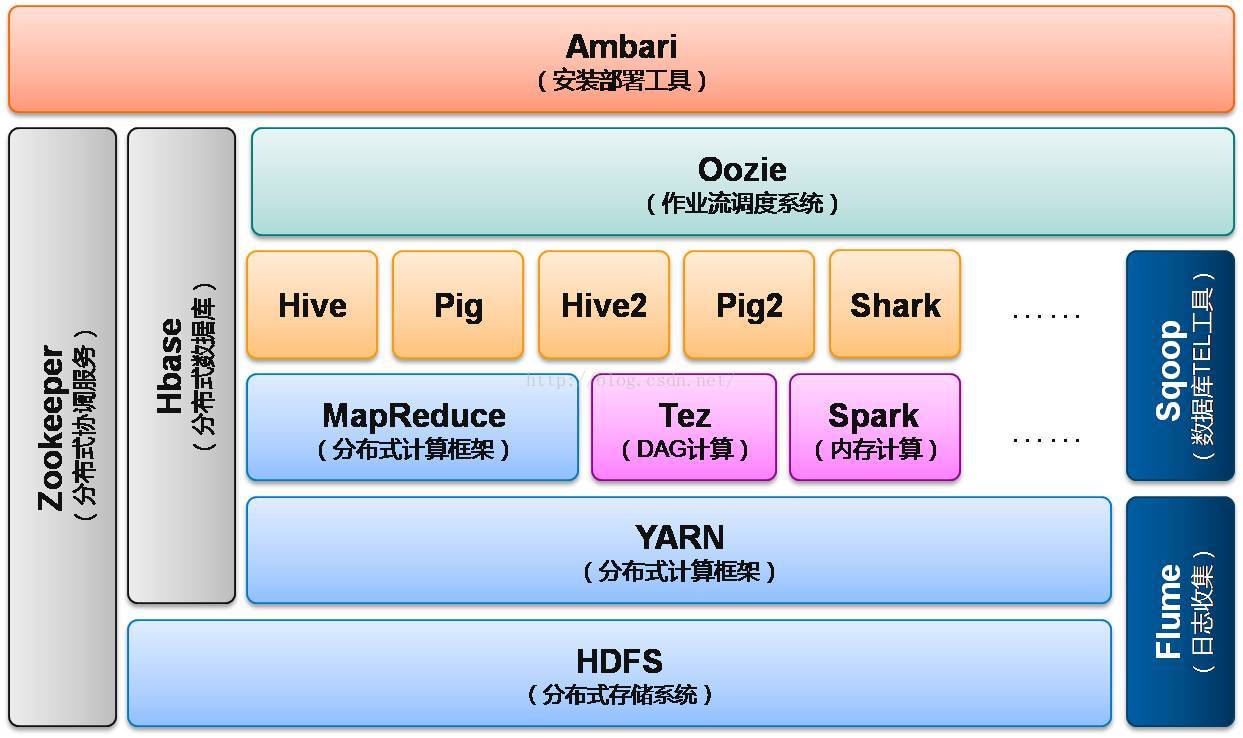
2、hadoop2.0时期架构
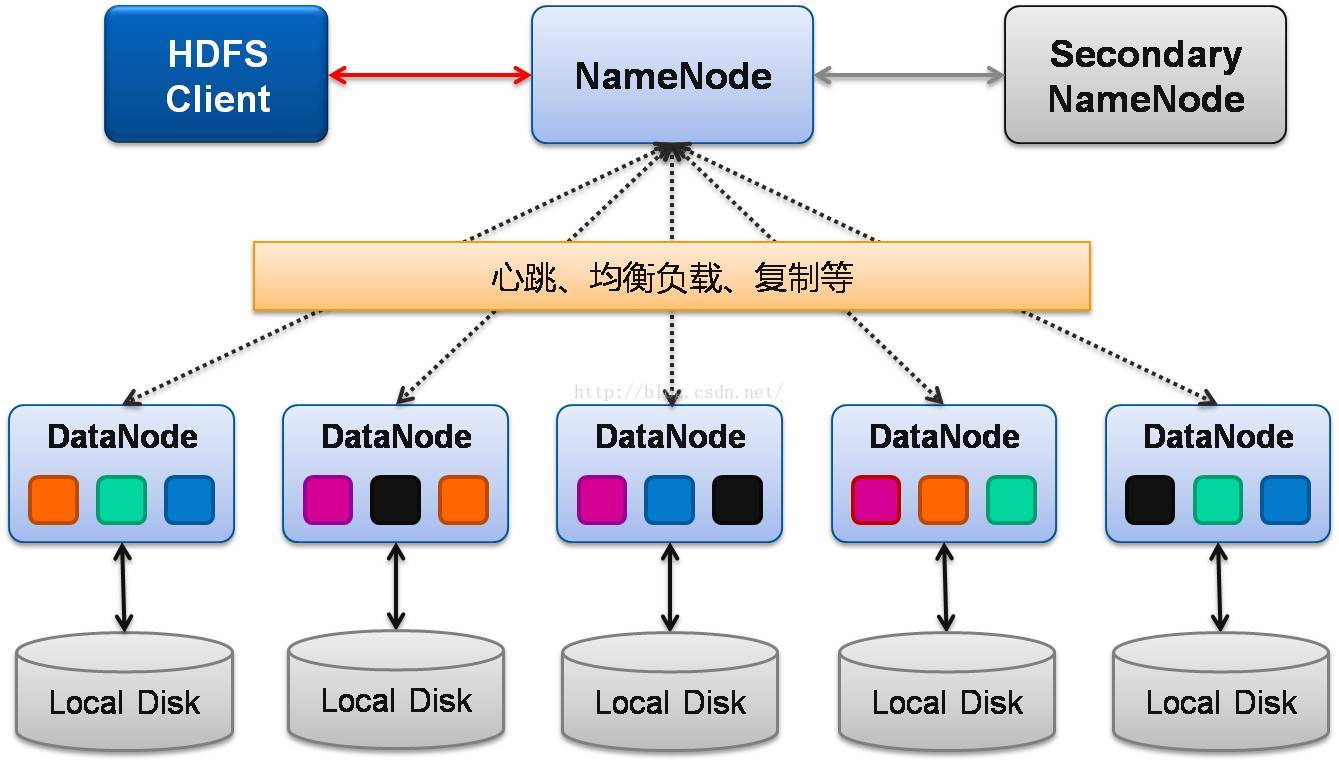
3、hdfs架构
Active Namenode
主 Master(只有一个),管理 HDFS 的名称空间,管理数据块映射信息;配置副本策略;处理客户端读写请求
Secondary NameNode
NameNode 的热备;定期合并 fsimage 和 fsedits,推送给 NameNode;当 Active NameNode 出现故障时,快速切换为新的 Active NameNode。
Datanode
Slave(有多个);存储实际的数据块;执行数据块读 / 写
Client
与 NameNode 交互,获取文件位置信息;与 DataNode 交互,读取或者写入数据;管理 HDFS、访问 HDFS。
4、MapReduce
源自于 Google 的 MapReduce 论文
发表于 2004 年 12 月
Hadoop MapReduce 是 Google MapReduce 克隆版
MapReduce特点
良好的扩展性
高容错性
适合 PB 级以上海量数据的离线处理
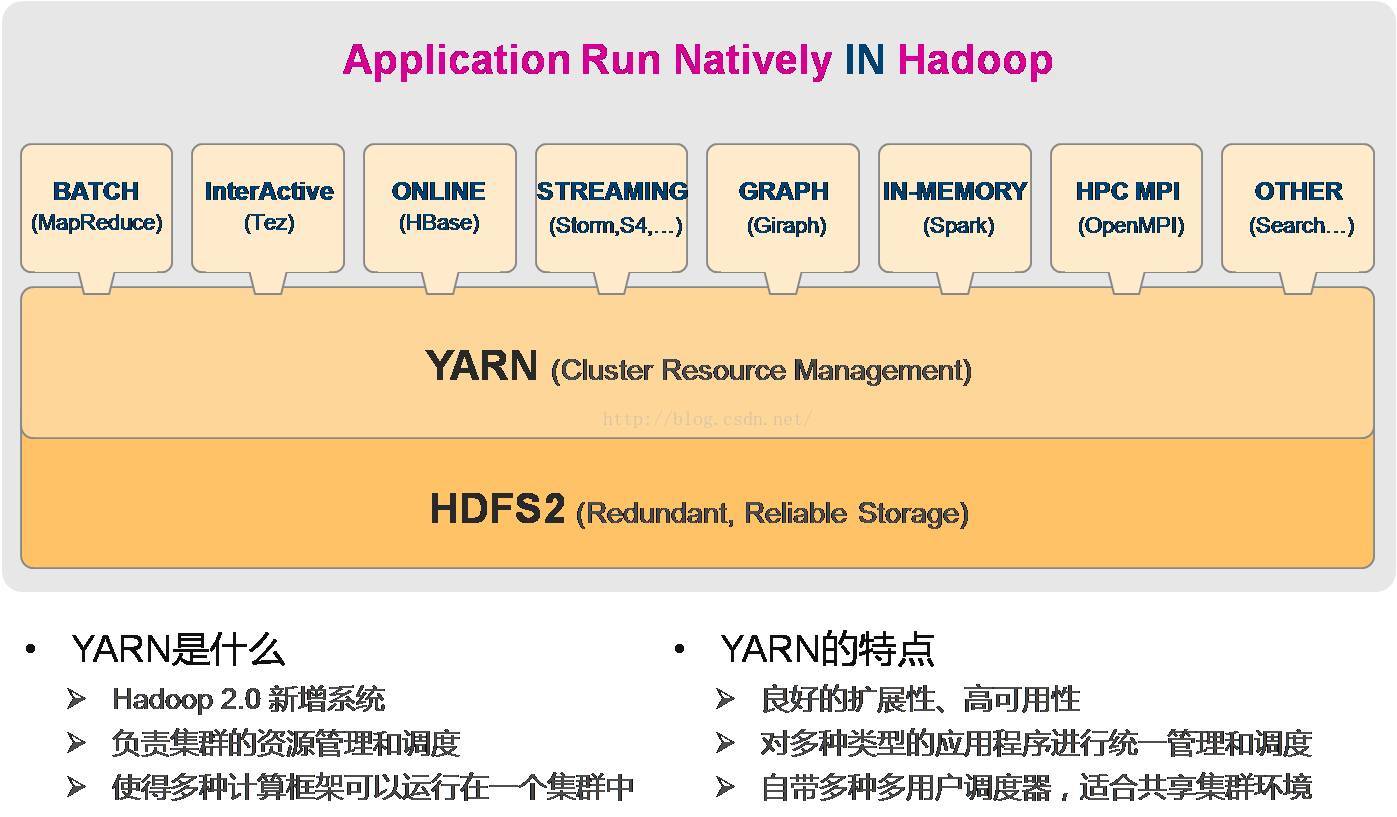
5、yarn架构
6、hadoop1.0与hadoop2.0比较图
7、Hive(基于MR的数据仓库)
由Facebook开源,最初用于海量结构化日志数据统计;ETL(Extraction-Transformation-Loading)工具构建在Hadoop之上的数据仓库;数据计算使用 MapReduce,数据存储使用HDFS
Hive 定义了一种类 SQL 查询语言——HQL
类似SQL,但不完全相同
通常用于进行离线数据处理(采用 MapReduce);可认为是一个 HQL→MR 的语言翻译器
8、Hbase(分布式数据库)
源自 Google 的 Bigtable 论文
发表于 2006 年 11 月
Hbase 是 Google Bigtable 克隆版
9、Hadoop 发行版(开源版)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









