









有关贝叶斯定理和贝叶斯公式的推导过程,在阮一峰大神的博客里的《贝叶斯推断及其互联网应用(一):定理简介》写得非常全面,简洁明了。
下面是我的个人笔记总结:
贝叶斯定理
基于假设的先验概率,给定假设下观察到的不同数据的概率,提供了一种计算后验概率的方法。
先验概率:由以往的数据分析得到的概率。
后验概率:得到信息之后再重新加以修正的概率。
在人工智能领域是非常有代表性的不确定性知识表示和推理方法。
条件概率
P(A|B)
表示事件B发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。
贝叶斯公式
P(B|A) 是根据A参数值去判断其属于类别B的概率,是后验概率。 P(B) 是直接判断某个样本属于B的概率,是先验概率。 P(A|B) 是在类别B中观察到A的概率, P(A) 是在样本中观测到A的概率。
朴素贝叶斯算法-原理
基本思想
对于给定的待分类项 X{a1,a2,a3,...,an} ,求解此项出现的条件下,各个类别 yi 出现的概率,哪个 P(yi|X) 最大,就把此分类项 X 分为那个类别。
算法定义
- 设
X{a1,a2,a3,...,an} 为一个待分类项,每个 ai 为X的一个特征属性,特征属性之间互相独立。- 设 C{y1,y2,y3,...,yn} 为一个类别集合。
- 计算 P(y1|X),P(y2|X),P(y3|X),...,P(yn|X)
- P(yk|X)=max{P(y1|X),P(y2|X),P(y3|X),...,P(yn|X)},则X∈yk
求 P(yk|X) 的步骤
- 找到一个已知分类的待分类项集合,这个集合叫训练样本集。
- 得到各个类别下,各个特征属性的条件概率,即
P(a1|y1),P(a2|y1),P(a3|y1),...,P(an|y1),P(a1|y2),P(a2|y2),P(a3|y2),...,P(an|y2),P(a1|y3),P(a2|y3),P(a3|y3),...,P(an|y3),⋮,⋮,⋮,...,⋮,P(a1|yn),P(a2|yn),P(a3|yn),...,P(an|yn), - 在贝叶斯公式中分母相当于在样本数据中
X
的概率,所以对任何一个待分类项来说
P(X) 是常数,固定的。求后验概率 P(yi)|X 只需要考虑分子即可。因为个特征属性独立,所以有:
P(X|yi)P(yi)=P(a1|yi)P(a2|yi)P(a3|yi)...P(an|yi)P(yi)=P(yi)∏j=1nP(aj|yi)
所以:
P(X|yi)=∏k=1nP(ak|yi)
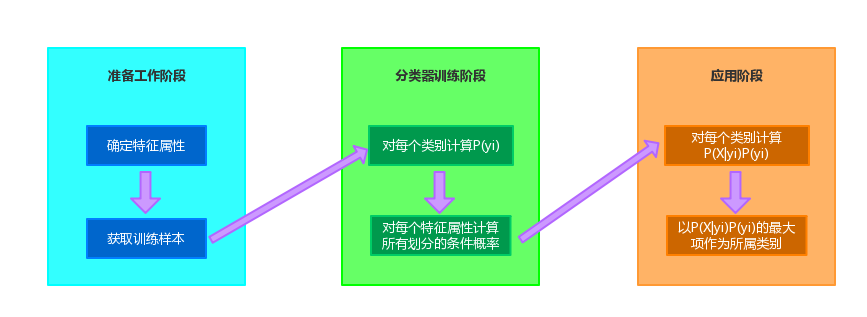
处理流程
简单实例
数据样本:
age income student credit_rating buys_computer <=30 high no fair no <=30 high no excellent no 31..40 high no fair yes >40 medium no fair yes >40 low yes fair yes >40 low yes excellent no 31..40 low yes excellent yes <=30 medium no fair no <=30 low yes fair yes >40 medium yes fair yes <=30 medium yes excellent yes 31..40 medium no excellent yes 31..40 high yes fair yes >40 medium no excellent no 待分类数据:
X=(age<=30,income=medium,student=yes,credit_rating=fair)第一阶段:准备阶段
根据具体情况确定特征属性,并且对特征属性进行适当划分。然后就是对一部分待分类项进行人工划分,以确定训练样本。这一阶段输入的是所有待分类项,输出的是特征属性和训练样本。所以:
**数据样本属性:**age、income 、student 、 credit_rating
**类别属性:**buys_computer
y1 :buys_computer=”yes”
y2 :buys_computer=”no”第二阶段:分类器训练阶段
计算每个类别在训练样本中出现的频率,以及每个特征属性划分对每个类别的条件概率。输入时特征属性和训练样本,输出是分类器。
计算每个类别的先验概率:
P(y1) =9/14=0.643
P(y2) =5/14=0.357计算每个特征属性对于每个类别的条件概率:
P(age<=”30”|buys_computer=”yes”)=2/9=0.222
P(income=”medium”|buys_computer=”yes”)=4/9=0.444
P(student=”yes”|buys_computer=”yes”)=6/9=0.667
P(credit_rating=”fair”|buys_computer=”yes”)=6/9=0.667P(age<=”30”|buys_computer=”no”)=3/5=0.600
P(income=”medium”|buys_computer=”no”)=4/9=0.400
P(student=”yes”|buys_computer=”no”)=1/5=0.200
P(credit_rating=”fair”|buys_computer=”no”)=2/5=0.400计算条件概率 P(X|yi)
P(X|buyscomputer="yes") =0.222*0.444*0.667*0.667=0.044
P(X|buyscomputer="no") =0.600*0.400*0.200*0.400=0.019第三阶段:应用阶段
计算对于每个 yi 的 P(X|yi)P(yi)
P(X|buys_computer="yes")P(buys_computer="yes") =0.444*0.643=0.028
P(X|buys_computer="no")P(buys_computer="no") =0.019*0.357=0.007到此,对于待分类的样本X,朴素贝叶斯分类预测buys_computer=”yes”
总结:
朴素贝叶斯算法的优点:
1. 算法逻辑简单,易于实现
2. 分类过程中时空开销小
3. 算法稳定,对于不同的数据特点其分类性能差别不大,健壮性比较好。















 5358
5358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









