







Hive 简介
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
使用Hive的原因
- 操作接口采用类SQL语法,提供快速开发的能力
- 避免了去写MapReduce,减少开发人员的学习成本
- 扩展功能很方便
Hive的特性
- 可扩展:Hive可以自由的扩展集群的规模,一般情况下不需要重启服务
- 延展性:Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数,就像SQL中的UDF
- 容错性:良好的容错性,节点出现问题SQL仍可完成执行,分布式存储的优点
容错性的原因:MapRuduce的整个编配工作由主节点控制,一般每份mapper的输入数据会同时分发到多个节点形成多分副本,用于事务的失效处理,每个节点必须与主节点通信,表示自己工作正常。如果某节点失效或则工作异常,主节点将重启该节点或者将该节点移出可用机器池。
注:
- 在任何时候,每个mapper和reducer间都不进行通信,每个节点只处理自己的事务,并且在本地分配的数据集上运算。
Hive与Hadoop的关系
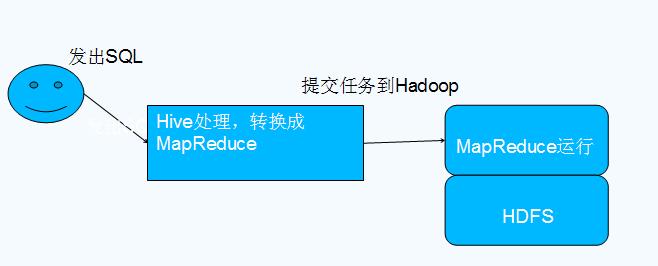
MapRuduce学习要点
- 主节点控制MapReduce 的作业流程
- MapReduce的作业可以分成map任务和reduce任务
- map任务与reduce任务之间不做数据交流
- 在map和reduce阶段中间有一个sort或combine阶段
- 数据被重复存放在不同的机器上,以防某个机器失效
- mapper和reducer传输的数据形式为key/value对
Hive命令
命令选项
- -i: 初始化SQL文件
- -e ‘quoted query string’: 运行引号内sql查询语句
- -f filename: 从文件中运行sql语句
- -S: 无声模式在互动的Shell,只有数据发出
- –h: 查看应用的帮助文档
- -hiveconf: 设置hive/hadoop的配置变量
HIVE_HOME/bin/hive -S -e ' select count(*) from c02_clickstat_fatdt1' > a.txt
HIVE_HOME/bin/hive -f /home/my/hive-script.sqlHive中的连接操作
- 只支持相等JOIN。
- 多表连接当使用不同的列进行Join时,会产生多个MapReduce作业。
- 最后的表的数据是从流中读取,而前面的会在内存中缓存,因此最好把最大的表放在最后。
排序
- order by
跟传统的 sql 中的 order by 作用相同 ,对查询的结果做一次全局排序,因此无论有多少个 map,order by 的数据都会放到一个 reducer 中去处理,会消耗很多时间也浪费了资源。
- sort by
在每一个reducer上都会做排序,保证了局部有序,但是不能保证所有数据都有序,可以为接下来的全局排序提高不少效率(做一次归并排序)
- distribute by
控制map的输出在reducer上如何划分
select mid ,money,name from store distribute by mid sort by midmid相同的数据会被送到一个reducer上去处理(distribute by mid),然后在每一个reducer上会按照mid排序(sort by mid)
- cluster by
功能就是distribute by 与 sort by的结合
select mid ,money,name from store cluster by midcluster by指定的列只能降序,不能指定asc,desc















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









