 构建分布式Hadoop集群教程
构建分布式Hadoop集群教程





本文将展示如何构建分布式的Hadoop集群
我们将使用三台主机,需先配置好SSH证书登陆,参考威廉之前的文章SSH证书连接配置DEBUG步骤
分别设置三台主机hostname为master,slave1,slave2,并分别创建spark用户
# 配置hosts
vi /etc/hosts
# 编辑hosts文件,配置内网IP与hostname的匹配
192.168.175.118 master
192.168.203.53 slave1
192.168.175.65 slave2解压jdk,hadoop到/usr/local路径,创建HDFS文件夹路径
mkdir /usr/local/hadoop-2.7.1/tmp
mkdir /usr/local/hadoop-2.7.1/hdfs
mkdir /usr/local/hadoop-2.7.1/hdfs/name
mkdir /usr/local/hadoop-2.7.1/hdfs/data配置环境变量
# 编辑bash配置文件
vi /home/spark/.bash_profile
# 配置环境变量
export JAVA_HOME=/usr/local/jdk1.7.0_80
export JRE_HOME=${JAVA_HOME}/jre
export CLASS_PATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export HADOOP_HOME=/usr/local/hadoop-2.7.1
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export PATH=$PATH:$HOME/bin:${JAVA_HOME}/bin:${HADOOP_HOME}/bin
# 使配置生效
source /home/spark/.bash_profile接下来的Hadoop配置可以在master主机统一写好了直接复制到slave主机
# 配置hadoop-env.sh
vi $HADOOP_CONF_DIR/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.7.0_80
# 若SSH端口不是默认的22,可以在这里配置
export HADOOP_SSH_OPTS="-p 22000"
# 配置core-site.xml
vi $HADOOP_CONF_DIR/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7.1/tmp</value>
</property>
</configuration>
# 配置hdfs-site.xml
vi $HADOOP_CONF_DIR/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:/usr/local/hadoop-2.7.1/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:/usr/local/hadoop-2.7.1/hdfs/data</value>
</property>
</configuration>
# 配置mapred-site.xml
vi $HADOOP_CONF_DIR/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
</configuration>
# 配置yarn-site.xml
vi $HADOOP_CONF_DIR/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
# 配置masters文件,写入master主机的hostname
vi $HADOOP_CONF_DIR/masters
master
# 配置slaves文件,写入slave主机的hostname
vi $HADOOP_CONF_DIR/slaves
slave1
slave2更多配置信息可以在http://hadoop.apache.org/docs/current/hadoop-project-dist/查到
将master主机的配置文件同步到slave主机,省去分别设置的麻烦
scp -P 22000 $HADOOP_CONF_DIR/hadoop-env.sh spark@slave1:$HADOOP_CONF_DIR/hadoop-env.sh
scp -P 22000 $HADOOP_CONF_DIR/core-site.xml spark@slave1:$HADOOP_CONF_DIR/core-site.xml
scp -P 22000 $HADOOP_CONF_DIR/hdfs-site.xml spark@slave1:$HADOOP_CONF_DIR/hdfs-site.xml
scp -P 22000 $HADOOP_CONF_DIR/mapred-site.xml spark@slave1:$HADOOP_CONF_DIR/mapred-site.xml
scp -P 22000 $HADOOP_CONF_DIR/yarn-site.xml spark@slave1:$HADOOP_CONF_DIR/yarn-site.xml
scp -P 22000 $HADOOP_CONF_DIR/masters spark@slave1:$HADOOP_CONF_DIR/masters
scp -P 22000 $HADOOP_CONF_DIR/slaves spark@slave1:$HADOOP_CONF_DIR/slaves
# slave2
scp -P 22000 $HADOOP_CONF_DIR/hadoop-env.sh spark@slave2:$HADOOP_CONF_DIR/hadoop-env.sh
scp -P 22000 $HADOOP_CONF_DIR/core-site.xml spark@slave2:$HADOOP_CONF_DIR/core-site.xml
scp -P 22000 $HADOOP_CONF_DIR/hdfs-site.xml spark@slave2:$HADOOP_CONF_DIR/hdfs-site.xml
scp -P 22000 $HADOOP_CONF_DIR/mapred-site.xml spark@slave2:$HADOOP_CONF_DIR/mapred-site.xml
scp -P 22000 $HADOOP_CONF_DIR/yarn-site.xml spark@slave2:$HADOOP_CONF_DIR/yarn-site.xml
scp -P 22000 $HADOOP_CONF_DIR/masters spark@slave2:$HADOOP_CONF_DIR/masters
scp -P 22000 $HADOOP_CONF_DIR/slaves spark@slave2:$HADOOP_CONF_DIR/slaves配置完成,从master主机格式化HDFS文件系统
hadoop namenode -format完成后,从master主机启动HDFS
cd $HADOOP_HOME/sbin
./start-dfs.sh
# 控制台输出
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/hadoop-2.7.1/logs/hadoop-spark-namenode-master.out
slave2: starting datanode, logging to /usr/local/hadoop-2.7.1/logs/hadoop-spark-datanode-slave2.out
slave1: starting datanode, logging to /usr/local/hadoop-2.7.1/logs/hadoop-spark-datanode-slave1.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop-2.7.1/logs/hadoop-spark-secondarynamenode-master.out
# 我们看到master主机启动了NameNode,SecondaryNameNode两个进程,slave主机启动了DataNode进程,与我们之前的配置相同
jps
9905 NameNode
10100 SecondaryNameNode
ssh -p 22000 slave1
jps
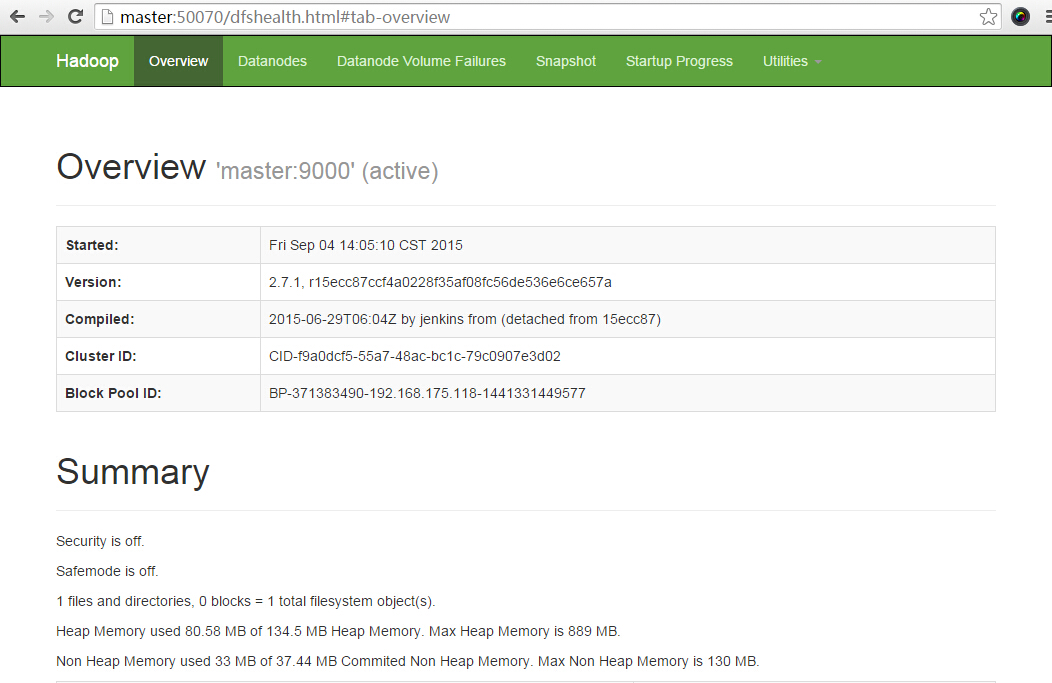
5917 DataNode登陆 http://master:50070/ 可以查看NameNode的web控制台
从主机启动YARN
cd $HADOOP_HOME/sbin
./start-yarn.sh
# 控制台输出
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.7.1/logs/yarn-spark-resourcemanager-master.out
slave2: starting nodemanager, logging to /usr/local/hadoop-2.7.1/logs/yarn-spark-nodemanager-slave2.out
slave1: starting nodemanager, logging to /usr/local/hadoop-2.7.1/logs/yarn-spark-nodemanager-slave1.out
# master主机启动了ResourceManager进程,slave主机启动了NodeManager进程
jps
9905 NameNode
10100 SecondaryNameNode
10400 ResourceManager
ssh -p 22000 slave1
jps
5917 DataNode
6074 NodeManager和NameNode一样,也可以登陆 http://master:8088/ 查看ResourceManager的web控制台
web控制台端口的设置是在以下的文件中
hdfs-site.xml
dfs.namenode.http-address 0.0.0.0:50070
dfs.namenode.secondary.http-address 0.0.0.0:50090
dfs.datanode.http.address 0.0.0.0:50075
yarn-site.xml
yarn.resourcemanager.webapp.address ${yarn.resourcemanager.hostname}:8088
yarn.nodemanager.webapp.address ${yarn.nodemanager.hostname}:8042
















 920
920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









