







在PageRank算法出现之前,早期的搜索引擎是根据关键词出现次数对网页进行排序,但这样的算法有严重的缺陷,假设网站A像祥林嫂一样反复重复几个热门关键词,那么用户在搜索这些关键词的时候,网站A就会被排在前面,而这显然不是用户希望得到的结果,更严重的后果是网络上会充斥着广告和垃圾信息,而真正有用的信息却难以被用户搜索到。
于是, 1996 年初, 谷歌公司的创始人, 当时还是美国斯坦福大学 (Stanford University) 研究生的佩奇 (Larry Page) 和布林 (Sergey Brin) 开始了对网页排序问题的研究。他们从学术界判别论文重要性的通用方法,即考量引用次数得到了灵感,认为网页的重要性(也就是排序)是不能靠每个网页自己来标榜的,而应该通过全互联网所有网页间的相互链接来确定。具体地说,一个网页被其它网页链接得越多, 它的排序就应该越靠前。不仅如此,Larry和Sergey还进一步提出,一个网页越是被排序靠前的网页所链接,它的排序就也应该越靠前。这一条的意义也是不言而喻的,就好比一篇论文被诺贝尔奖得主所引用,显然要比被普通研究者所引用更说明其价值。
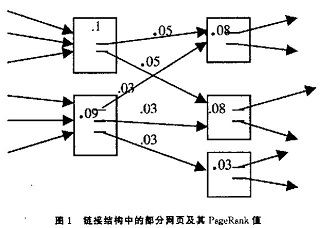
思路虽然有了,实现却并非易事。网页 Wi 的排序 Pi 由所有其他的网页的排序 Pj≠i 决定,而 Pi 又会对 Pj≠i 产生影响,于是就面临了“先有鸡还是先有蛋”的难题。
Larry和Sergey的解决方法是这样的:假设用户A是互联网上所有用户的平均(即A不存在个人喜好),那么再假定经历足够多的网上漫游过后,A在n时刻处在页面 Wi 的概率为 Pi , Wi 页面有 Ni 个外链,由于A没有个人喜好,因此点击每个外链的可能性均为 1/Ni
根据这个假设,我们可以得出: Pi(n+1)=∑jPj(n)pj→i/Nj
其中 pj→i 是一个描述互联网链接结构的指标函数 (indicator function),其定义是如果网页 Wj 有链接指向网页 Wi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 212
212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









