







在这篇文章里,威廉将展示如何构建一个简单的Spark集群
我们采用VMware Workstation搭建数台虚拟机,具体信息如下:
物理机操作系统:Windows 7 Professional Service Pack 1 64位
虚拟机操作系统:Ubuntu 14.04 LTS 64位
虚拟机网络设置:
- 连接方式:NAT
- 子网IP:192.168.32.0
- 网关:192.168.32.2
- DNS:192.168.32.2简单的Spark集群由至少一台Master和数台Slave构成;在本文中尝试构建3台虚拟机,1台用作Master,另外2台作Slave
接下来威廉就带大家详细的介绍部署的步骤
1. 虚拟机安装
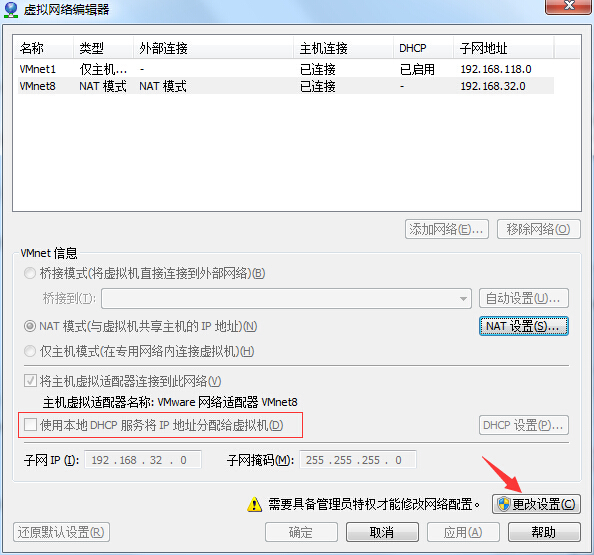
在创建虚拟机前,先修改下Workstation的默认网络设置,点击编辑->虚拟网络编辑器
在这里需要注意的是,默认VMnet8网卡,也就是用于和物理机通信的网卡,是打开了DHCP服务的,我们需要按下图所示将其关闭,否则在后面设置静态IP的时候会产生冲突
下载虚拟机镜像,在VMware Workstation中创建虚拟机,威廉选取的是Ubuntu 14.04 LTS 64位的操作系统版本,大家可以自由选择,但注意如果是RedHat系列的Linux系统,在之后步骤用到的命令会有所不同
在本文中,我们一共需要创建3台虚拟机,1台用作master,2台用作slave,并修改相应的hostname为master和slave1,slave2
1.1 hostname配置
关于如何修改hostname,在man hostname中我们可以找到有这么一段:
The host name is usually set once at system startup in /etc/init.d/hostname.sh
(normally by reading the contents of a file which contains the host name,
e.g. /etc/hostname).所以我们可以通过修改/etc/hostname文件来改变默认hostname,重启使之生效
1.2 创建统一用户
为所有虚拟机建立统一的用户,我们选取spark
sudo adduser spark注:新创建的spark用户在使用sudo时可能出现not in the sudoers file的错误,解决方式参考1
1.3 JDK安装及JAVA_HOME设置
下载JDK并解压,编辑/home/spark/.profile文件,追加以下内容:
# set JAVA_HOME if not exist
if [ -n "$JAVA_HOME" ]; then
JAVA_HOME="/home/spark/jdk1.7.0_75"
export JAVA_HOME
PATH="$JAVA_HOME:$PATH"
fi2. 网络配置
2.1 固定IP配置
在spark集群中,master与slave之间将通过ssh相互通信,因此每台主机需要有固定的IP地址,并对应到相应的hostname
编辑/etc/network/interfaces,以master为例,追加以下内容:
# The primary network interface
auto eth0
iface eth0 inet static
address 192.168.32.130
netmask 255.255.255.0
gateway 192.168.32.2
dns-nameservers 192.168.32.2输入以下命令使改动生效
sudo ifconfig eth0 down
sudo ifconfig eth0 upslave主机修改的内容相似,只需把address改为192.168.32.131,192.168.32.132
2.2 hosts配置
编辑/etc/hosts,追加如下:
# spark hosts
192.168.32.130 master
192.168.32.131 slave1
192.168.32.132 slave2输入以下命令测试修改是否生效
spark@master:~$ ping slave1
PING slave1 (192.168.32.131) 56(84) bytes of data.3. ssh配置
检查ssh服务是否启动
ps -e | grep sshd若没有启动,则需要先启动ssh服务
sudo service ssh start
# 若没有安装ssh服务器
sudo apt-get install openssh-server生成ssh公钥密钥,密码为空,将会在/home/spark/.ssh文件夹下生成id_dsa(密钥), id_dsa.pub(公钥), authorized_keys
ssh-keygen -t dsa
# 密码留空将master主机的id_dsa.pub内容追加到所有slave主机的authorized_keys文件内,通过以下命令测试master能否ssh无密码登陆所有slave
spark@master:~$ ssh slave1
Welcome to Ubuntu 14.04.1 LTS (GNU/Linux 3.13.0-32-generic x86_64)
* Documentation: https://help.ubuntu.com/
399 packages can be updated.
173 updates are security updates.
Last login: Sun May 10 07:09:45 2015 from master
spark@slave1:~$ 4. spark安装
登陆 https://spark.apache.org/downloads.html 下载对应的spark版本, 我们选择下载预编译版本spark-1.3.1-bin-hadoop2.6.tgz,解压到任意不含空格的目录,需保证每台主机都采用相同的目录
配置master主机的$SPARK_HOME/conf/slaves文件,写入所有slave node的hostname
slave1
slave2配置所有主机的$SPARK_HOME/conf/spark-env.sh,写入$JAVA_HOME2和$SPARK_MASTER_IP3
export JAVA_HOME=/home/spark/jdk1.7.0_75
export SPARK_MASTER_IP=192.168.32.1305. 启动spark
$SPARK_HOME/sbin/start-all.sh查看master主机$SPARK_HOME/logs/spark-spark-org.apache.spark.deploy.master.Master-1-master.out
Spark Command: /home/spark/jdk1.7.0_75/bin/java -cp /home/spark/spark-1.3.1-bin-hadoop2.6/sbin/../conf:/home/spark/spark-1.3.1-bin-hadoop2.6/lib/spark-assembly-1.3.1-hadoop2.6.0.jar:/home/spark/spark-1.3.1-bin-hadoop2.6/lib/datanucleus-core-3.2.10.jar:/home/spark/spark-1.3.1-bin-hadoop2.6/lib/datanucleus-rdbms-3.2.9.jar:/home/spark/spark-1.3.1-bin-hadoop2.6/lib/datanucleus-api-jdo-3.2.6.jar -XX:MaxPermSize=128m -Dspark.akka.logLifecycleEvents=true -Xms512m -Xmx512m org.apache.spark.deploy.master.Master --ip 192.168.32.130 --port 7077 --webui-port 8080
========================================
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/05/11 05:45:58 INFO Master: Registered signal handlers for [TERM, HUP, INT]
15/05/11 05:45:58 WARN Utils: Your hostname, master resolves to a loopback address: 127.0.1.1; using 192.168.32.130 instead (on interface eth0)
15/05/11 05:45:58 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
15/05/11 05:46:04 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/05/11 05:46:07 INFO SecurityManager: Changing view acls to: spark
15/05/11 05:46:07 INFO SecurityManager: Changing modify acls to: spark
15/05/11 05:46:07 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(spark); users with modify permissions: Set(spark)
15/05/11 05:46:15 INFO Slf4jLogger: Slf4jLogger started
15/05/11 05:46:18 INFO Remoting: Starting remoting
15/05/11 05:46:22 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkMaster@192.168.32.130:7077]
15/05/11 05:46:22 INFO Remoting: Remoting now listens on addresses: [akka.tcp://sparkMaster@192.168.32.130:7077]
15/05/11 05:46:23 INFO Utils: Successfully started service 'sparkMaster' on port 7077.
15/05/11 05:46:34 INFO Server: jetty-8.y.z-SNAPSHOT
15/05/11 05:46:36 INFO AbstractConnector: Started SelectChannelConnector@master:6066
15/05/11 05:46:36 INFO Utils: Successfully started service on port 6066.
15/05/11 05:46:36 INFO StandaloneRestServer: Started REST server for submitting applications on port 6066
15/05/11 05:46:36 INFO Master: Starting Spark master at spark://192.168.32.130:7077
15/05/11 05:46:36 INFO Master: Running Spark version 1.3.1
15/05/11 05:46:37 INFO Server: jetty-8.y.z-SNAPSHOT
15/05/11 05:46:37 INFO AbstractConnector: Started SelectChannelConnector@0.0.0.0:8080
15/05/11 05:46:37 INFO Utils: Successfully started service 'MasterUI' on port 8080.
15/05/11 05:46:37 INFO MasterWebUI: Started MasterWebUI at http://master:8080
15/05/11 05:46:53 INFO Master: Registering worker slave2:60027 with 1 cores, 512.0 MB RAM
15/05/11 05:46:53 INFO Master: Registering worker slave1:59125 with 1 cores, 512.0 MB RAM查看slave主机$SPARK_HOME/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-slave1.out
Spark Command: /home/spark/jdk1.7.0_75/bin/java -cp /home/spark/spark-1.3.1-bin-hadoop2.6/sbin/../conf:/home/spark/spark-1.3.1-bin-hadoop2.6/lib/spark-assembly-1.3.1-hadoop2.6.0.jar:/home/spark/spark-1.3.1-bin-hadoop2.6/lib/datanucleus-core-3.2.10.jar:/home/spark/spark-1.3.1-bin-hadoop2.6/lib/datanucleus-api-jdo-3.2.6.jar:/home/spark/spark-1.3.1-bin-hadoop2.6/lib/datanucleus-rdbms-3.2.9.jar -XX:MaxPermSize=128m -Dspark.akka.logLifecycleEvents=true -Xms512m -Xmx512m org.apache.spark.deploy.worker.Worker spark://192.168.32.130:7077
========================================
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/05/11 08:24:27 INFO Worker: Registered signal handlers for [TERM, HUP, INT]
15/05/11 08:24:27 WARN Utils: Your hostname, slave1 resolves to a loopback address: 127.0.1.1; using 192.168.32.131 instead (on interface eth0)
15/05/11 08:24:27 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
15/05/11 08:24:30 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/05/11 08:24:31 INFO SecurityManager: Changing view acls to: spark
15/05/11 08:24:31 INFO SecurityManager: Changing modify acls to: spark
15/05/11 08:24:31 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(spark); users with modify permissions: Set(spark)
15/05/11 08:24:33 INFO Slf4jLogger: Slf4jLogger started
15/05/11 08:24:33 INFO Remoting: Starting remoting
15/05/11 08:24:34 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkWorker@slave1:51940]
15/05/11 08:24:34 INFO Remoting: Remoting now listens on addresses: [akka.tcp://sparkWorker@slave1:51940]
15/05/11 08:24:34 INFO Utils: Successfully started service 'sparkWorker' on port 51940.
15/05/11 08:24:35 INFO Worker: Starting Spark worker slave1:51940 with 1 cores, 512.0 MB RAM
15/05/11 08:24:35 INFO Worker: Running Spark version 1.3.1
15/05/11 08:24:35 INFO Worker: Spark home: /home/spark/spark-1.3.1-bin-hadoop2.6
15/05/11 08:24:35 INFO Server: jetty-8.y.z-SNAPSHOT
15/05/11 08:24:35 INFO AbstractConnector: Started SelectChannelConnector@0.0.0.0:8081
15/05/11 08:24:35 INFO Utils: Successfully started service 'WorkerUI' on port 8081.
15/05/11 08:24:35 INFO WorkerWebUI: Started WorkerWebUI at http://slave1:8081
15/05/11 08:24:36 INFO Worker: Connecting to master akka.tcp://sparkMaster@192.168.32.130:7077/user/Master...
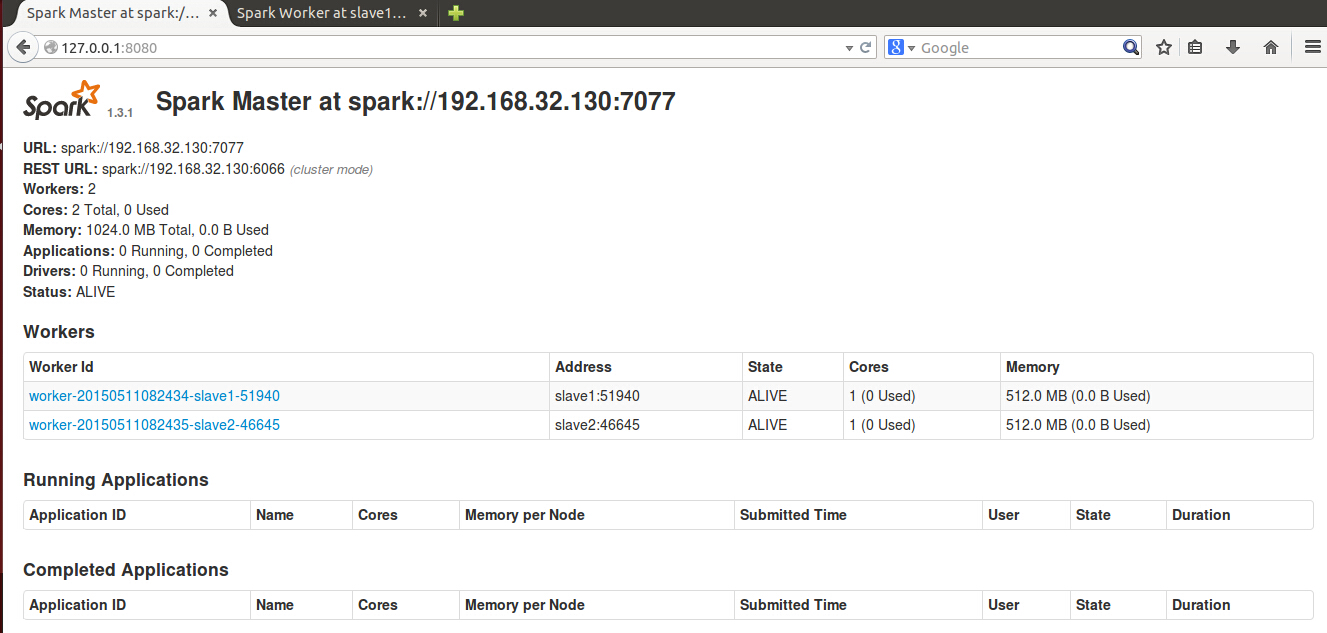
15/05/11 08:24:37 INFO Worker: Successfully registered with master spark://192.168.32.130:7077spark提供了UI用于管理集群,登陆192.168.32.130:8080,我们看到两台slave主机已成功连接
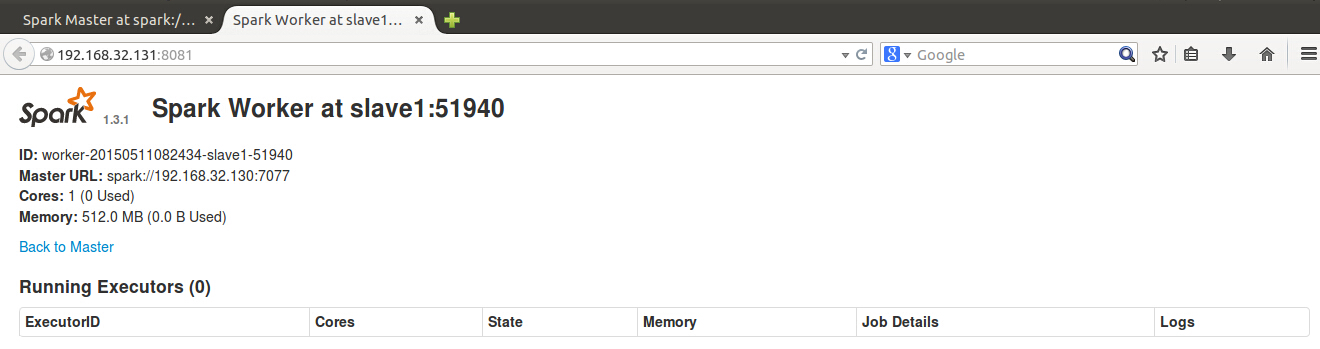
slave主机也有类似的UI用来管理任务,登陆192.168.32.131:8011
至此,威廉给大家展示了如何创建简单的spark集群,当在配置过程中遇到问题时,可以向spark的官方邮件组user@spark.apache.org提问题,或者访问这个较为便捷的网页http://apache-spark-user-list.1001560.n3.nabble.com/,再者就是万能的谷歌,度娘啦















 430
430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









