







一、前言
Dom即文件对象模型(Document Object Model),是W3C组织推荐的使用可扩展标记性语言的标准接口, 它主要用于读写xml文档,使用起来还是非常不错的。 另外Dom将整个xml文件映射成一个有层次的节点的结构,分别1级、2级到多级,这样子使整个繁琐的文档数量大但是依然很清晰,然后就可以非常方便的方便读写xml文档了。
二、准备条件
因为Dom是jdk自带的解析方式,所以不用添加jar包引用。
三、使用Dom实战
1、解析xml文档
实现思路:
<1>根据读取的xml路径,传递给DocumentBuilder之后 返回一个Document文档对象;
<2>然后操作这个Document对象,获取它下面的节点以及子节点的信息;
具体代码如下:
- import java.io.File;
- import java.io.FileInputStream;
- import java.io.FileNotFoundException;
- import java.io.FileOutputStream;
- import java.io.IOException;
- import java.io.InputStream;
- import java.io.PrintWriter;
- import javax.xml.parsers.DocumentBuilder;
- import javax.xml.parsers.DocumentBuilderFactory;
- import javax.xml.parsers.ParserConfigurationException;
- import javax.xml.transform.Transformer;
- import javax.xml.transform.TransformerConfigurationException;
- import javax.xml.transform.TransformerException;
- import javax.xml.transform.TransformerFactory;
- import javax.xml.transform.dom.DOMSource;
- import javax.xml.transform.stream.StreamResult;
- import org.w3c.dom.Document;
- import org.w3c.dom.Element;
- import org.w3c.dom.NamedNodeMap;
- import org.w3c.dom.Node;
- import org.w3c.dom.NodeList;
- import org.xml.sax.InputSource;
- import org.xml.sax.SAXException;
- /**
- * 使用dom解析和生成xml文档
- * @author Administrator
- *
- */
- public class DomOperateXmlDemo {
- public void parseXml01(){
- try {
- //创建DocumentBuilder工厂实例
- DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
- //new一个新的DocumentBuilder
- DocumentBuilder db = dbf.newDocumentBuilder();
- String xmlPath = "D:\\project\\dynamicWeb\\src\\resource\\server01.xml";
- String xmlName = xmlPath.substring(xmlPath.lastIndexOf("\\"));
- //解析xml转换为document文档对象,该方法支持重载
- //1、直接指定xml的绝对路径可以完成
- //Document document = db.parse(xmlPath);
- //2、使用InputStream输入流读取xml文件,然后把这个输入流传递进去
- InputStream inputStream = this.getClass().getResourceAsStream(xmlName);
- //3、也可以指定路径完成InputStream输入流的实例化操作
- //InputStream inputStream = new FileInputStream(new File(xmlPath));
- //4、使用InputSource输入源作为参数也可以转换xml
- //InputSource inputSource = new InputSource(inputStream);
- //Document document = db.parse(inputSource);
- Document document = db.parse(inputStream);
- //获取当前对象的子节点列表,返回的是一个根节点集合
- NodeList nodeList = document.getChildNodes();
- //获取根节点可以用NodeList集合返回它的第一个元素,并且它的类型是org.w3c.dom.Node的
- //Node rootNode = nodeList.item(0);
- Element rootNode = document.getDocumentElement();
- //上面的返回类型是Element,也可以使用 Node接收,因为Element接口继承Node接口,使用Node只不过方法没有Element多,可以自己尝试一下就知道了
- System.out.println("根节点的节点名称:" + rootNode.getNodeName());
- System.out.println("根节点的标签名称:" + rootNode.getTagName());
- System.out.println("根节点的节点类型:" + rootNode.getNodeType());
- System.out.println("根节点的节点值:" + rootNode.getFirstChild().getNodeValue());//rootNode.getNodeValue();返回的一直是null,因为程序不知道你到底要获取的哪个节点的value,所以只能获取子节点的value
- System.out.println("根节点的节点文本内容:" + rootNode.getTextContent());//返回当前节点下所有子标签的文本内容,并且换行是因为xml中有换行符
- System.out.println("根节点的指定属性的值:" + rootNode.getAttribute("port"));
- //直接获取所有属性的集合
- NamedNodeMap nameNodeMap = rootNode.getAttributes();
- for (int i = 0; i < nameNodeMap.getLength(); i++) {
- System.out.println("根节点属性" + nameNodeMap.item(i).getNodeName() + ":" + rootNode.getAttribute(nameNodeMap.item(i).getNodeName()));
- }
- //获取根节点的子节点集合信息
- NodeList subNodeList = rootNode.getChildNodes();
- for (int i = 0; i < subNodeList.getLength(); i++) {
- System.out.println("子节点的节点名称:" + subNodeList.item(i).getNodeName());
- System.out.println("子节点的节点文本内容:" + subNodeList.item(i).getTextContent());
- }
- } catch (ParserConfigurationException e) {
- e.printStackTrace();
- } catch (SAXException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- public static void main(String[] args) {
- DomOperateXmlDemo demo = new DomOperateXmlDemo();
- demo.parseXml01();
- }
- }
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.PrintWriter;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
/**
* 使用dom解析和生成xml文档
* @author Administrator
*
*/
public class DomOperateXmlDemo {
public void parseXml01(){
try {
//创建DocumentBuilder工厂实例
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
//new一个新的DocumentBuilder
DocumentBuilder db = dbf.newDocumentBuilder();
String xmlPath = "D:\\project\\dynamicWeb\\src\\resource\\server01.xml";
String xmlName = xmlPath.substring(xmlPath.lastIndexOf("\\"));
//解析xml转换为document文档对象,该方法支持重载
//1、直接指定xml的绝对路径可以完成
//Document document = db.parse(xmlPath);
//2、使用InputStream输入流读取xml文件,然后把这个输入流传递进去
InputStream inputStream = this.getClass().getResourceAsStream(xmlName);
//3、也可以指定路径完成InputStream输入流的实例化操作
//InputStream inputStream = new FileInputStream(new File(xmlPath));
//4、使用InputSource输入源作为参数也可以转换xml
//InputSource inputSource = new InputSource(inputStream);
//Document document = db.parse(inputSource);
Document document = db.parse(inputStream);
//获取当前对象的子节点列表,返回的是一个根节点集合
NodeList nodeList = document.getChildNodes();
//获取根节点可以用NodeList集合返回它的第一个元素,并且它的类型是org.w3c.dom.Node的
//Node rootNode = nodeList.item(0);
Element rootNode = document.getDocumentElement();
//上面的返回类型是Element,也可以使用 Node接收,因为Element接口继承Node接口,使用Node只不过方法没有Element多,可以自己尝试一下就知道了
System.out.println("根节点的节点名称:" + rootNode.getNodeName());
System.out.println("根节点的标签名称:" + rootNode.getTagName());
System.out.println("根节点的节点类型:" + rootNode.getNodeType());
System.out.println("根节点的节点值:" + rootNode.getFirstChild().getNodeValue());//rootNode.getNodeValue();返回的一直是null,因为程序不知道你到底要获取的哪个节点的value,所以只能获取子节点的value
System.out.println("根节点的节点文本内容:" + rootNode.getTextContent());//返回当前节点下所有子标签的文本内容,并且换行是因为xml中有换行符
System.out.println("根节点的指定属性的值:" + rootNode.getAttribute("port"));
//直接获取所有属性的集合
NamedNodeMap nameNodeMap = rootNode.getAttributes();
for (int i = 0; i < nameNodeMap.getLength(); i++) {
System.out.println("根节点属性" + nameNodeMap.item(i).getNodeName() + ":" + rootNode.getAttribute(nameNodeMap.item(i).getNodeName()));
}
//获取根节点的子节点集合信息
NodeList subNodeList = rootNode.getChildNodes();
for (int i = 0; i < subNodeList.getLength(); i++) {
System.out.println("子节点的节点名称:" + subNodeList.item(i).getNodeName());
System.out.println("子节点的节点文本内容:" + subNodeList.item(i).getTextContent());
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
DomOperateXmlDemo demo = new DomOperateXmlDemo();
demo.parseXml01();
}
}- <?xml version="1.0" encoding="UTF-8"?>
- <Server port="8005" id="server">
- Server标签内的内容
- <ServerName>服务名称内容</ServerName>
- </Server>
<?xml version="1.0" encoding="UTF-8"?>
<Server port="8005" id="server">
Server标签内的内容
<ServerName>服务名称内容</ServerName>
</Server>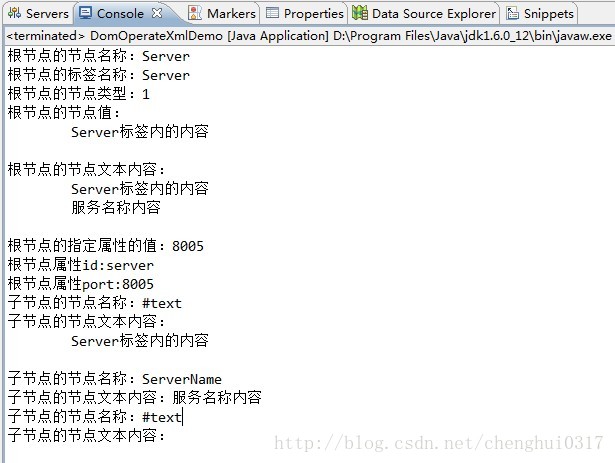
由此可知:
<1>根据控制台显示可知,根节点获取的子节点集合也包含文本内容,返回的标签节点名称是#text这样;
<2>另外getTextContent()获取的是该节点下所有的子节点的文本信息,而getNodeValue()只是获取当前节点的文本信息,如果是标签则返回null。
上面只是简单的获取了xml的根目录的元素,接下来使用Document自带的方法检索节点以及修改节点内的内容。
具体代码如下:
- public void parseXml02(){
- try{
- //创建DocumentBuilder工厂实例
- DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
- //new一个新的DocumentBuilder
- DocumentBuilder db = dbf.newDocumentBuilder();
- InputStream inputStream = this.getClass().getResourceAsStream("server02.xml");
- Document document = db.parse(inputStream);
- //根据节点名称获取节点集合
- NodeList nodeList = document.getElementsByTagName("Service");
- for (int i = 0; i < nodeList.getLength(); i++) {
- System.out.println("节点" + nodeList.item(i).getNodeName() + ":" + nodeList.item(i).getTextContent() + ",它的"
- + nodeList.item(i).getAttributes().item(0).getNodeName() + "属性值是:" + nodeList.item(i).getAttributes().item(0).getTextContent());
- }
- Element element = document.getElementById("server"); //不知道为什么总是返回null,费解
- System.out.println(element);
- //修改子元素的标签名称以及标签内容
- Node node = nodeList.item(0);
- node.getFirstChild().setNodeValue("这个是修改之后的内容..");
- //输出一下查看效果
- System.out.println("修改之后的Node的nodeValue:" + node.getFirstChild().getNodeValue());
- } catch (ParserConfigurationException e) {
- e.printStackTrace();
- } catch (SAXException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
public void parseXml02(){
try{
//创建DocumentBuilder工厂实例
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
//new一个新的DocumentBuilder
DocumentBuilder db = dbf.newDocumentBuilder();
InputStream inputStream = this.getClass().getResourceAsStream("server02.xml");
Document document = db.parse(inputStream);
//根据节点名称获取节点集合
NodeList nodeList = document.getElementsByTagName("Service");
for (int i = 0; i < nodeList.getLength(); i++) {
System.out.println("节点" + nodeList.item(i).getNodeName() + ":" + nodeList.item(i).getTextContent() + ",它的"
+ nodeList.item(i).getAttributes().item(0).getNodeName() + "属性值是:" + nodeList.item(i).getAttributes().item(0).getTextContent());
}
Element element = document.getElementById("server"); //不知道为什么总是返回null,费解
System.out.println(element);
//修改子元素的标签名称以及标签内容
Node node = nodeList.item(0);
node.getFirstChild().setNodeValue("这个是修改之后的内容..");
//输出一下查看效果
System.out.println("修改之后的Node的nodeValue:" + node.getFirstChild().getNodeValue());
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}- <?xml version="1.0" encoding="UTF-8"?>
- <Server port="8005" shutdown="SHUTDOWN" id="server">
- <Service name="Catalina" id="aa">第一个服务配置</Service>
- <Service name="Catalina01">第二个服务配置</Service>
- </Server>
<?xml version="1.0" encoding="UTF-8"?>
<Server port="8005" shutdown="SHUTDOWN" id="server">
<Service name="Catalina" id="aa">第一个服务配置</Service>
<Service name="Catalina01">第二个服务配置</Service>
</Server>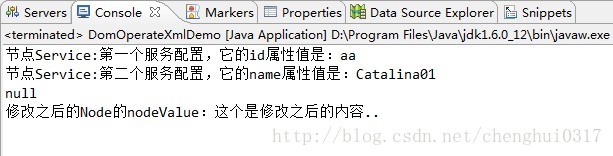
由此可知:
但是上面只是简单的获取了子节点元素,但是如果xml规则比较复杂,比如接下来要测试的server03.xml,具体如下:
- <?xml version="1.0" encoding="UTF-8"?>
- <Server port="8005" shutdown="SHUTDOWN">
- <Service name="Catalina">
- <Connector>第一个连接器</Connector>
- <Connector>第二个连接器
- <open>开启服务</open>
- <init>初始化一下</init>
- <service>执行请求服务</service>
- <destory>销毁一下</destory>
- <close>关闭服务</close>
- </Connector>
- </Service>
- </Server>
<?xml version="1.0" encoding="UTF-8"?>
<Server port="8005" shutdown="SHUTDOWN">
<Service name="Catalina">
<Connector>第一个连接器</Connector>
<Connector>第二个连接器
<open>开启服务</open>
<init>初始化一下</init>
<service>执行请求服务</service>
<destory>销毁一下</destory>
<close>关闭服务</close>
</Connector>
</Service>
</Server>- public void parseXml03(){
- try{
- //创建DocumentBuilder工厂实例
- DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
- //new一个新的DocumentBuilder
- DocumentBuilder db = dbf.newDocumentBuilder();
- InputStream inputStream = this.getClass().getResourceAsStream("server03.xml");
- Document document = db.parse(inputStream);
- //根据节点名称获取节点集合
- NodeList nodeList = document.getDocumentElement().getChildNodes();
- for (int i = 0; i < nodeList.getLength(); i++) {
- Node node = nodeList.item(i);
- if(!"#text".equals(node.getNodeName())){
- System.out.println("【1】" + node.getNodeName() + ":" + node.getFirstChild().getNodeValue());
- }
- NodeList subNodeList = node.getChildNodes();
- for (int j = 0; j < subNodeList.getLength(); j++) {
- Node subNode = subNodeList.item(j);
- if(!"#text".equals(subNode.getNodeName())){
- System.out.println(" 【2】" + subNode.getNodeName() + ":" + subNode.getFirstChild().getNodeValue());
- }
- NodeList subSubNodeList = subNode.getChildNodes();
- for (int k = 0; k < subSubNodeList.getLength(); k++) {
- Node subSubNode = subSubNodeList.item(k);
- if(!"#text".equals(subSubNode.getNodeName())){
- System.out.println(" 【3】" + subSubNode.getNodeName() + ":" + subSubNode.getFirstChild().getNodeValue());
- }
- }
- }
- }
- } catch (ParserConfigurationException e) {
- e.printStackTrace();
- } catch (SAXException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
public void parseXml03(){
try{
//创建DocumentBuilder工厂实例
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
//new一个新的DocumentBuilder
DocumentBuilder db = dbf.newDocumentBuilder();
InputStream inputStream = this.getClass().getResourceAsStream("server03.xml");
Document document = db.parse(inputStream);
//根据节点名称获取节点集合
NodeList nodeList = document.getDocumentElement().getChildNodes();
for (int i = 0; i < nodeList.getLength(); i++) {
Node node = nodeList.item(i);
if(!"#text".equals(node.getNodeName())){
System.out.println("【1】" + node.getNodeName() + ":" + node.getFirstChild().getNodeValue());
}
NodeList subNodeList = node.getChildNodes();
for (int j = 0; j < subNodeList.getLength(); j++) {
Node subNode = subNodeList.item(j);
if(!"#text".equals(subNode.getNodeName())){
System.out.println(" 【2】" + subNode.getNodeName() + ":" + subNode.getFirstChild().getNodeValue());
}
NodeList subSubNodeList = subNode.getChildNodes();
for (int k = 0; k < subSubNodeList.getLength(); k++) {
Node subSubNode = subSubNodeList.item(k);
if(!"#text".equals(subSubNode.getNodeName())){
System.out.println(" 【3】" + subSubNode.getNodeName() + ":" + subSubNode.getFirstChild().getNodeValue());
}
}
}
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}接下来执行该类的main方法,console效果如下:
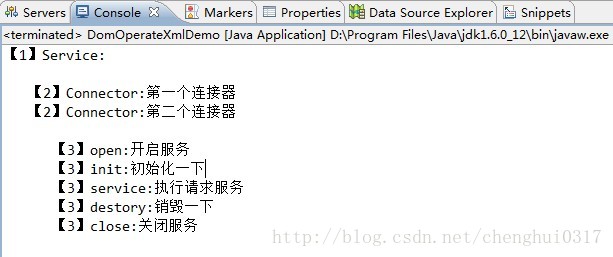
由此可知:
<2>因为标签与标签之前的字符串也算是节点,然后获取node.getFirstChild()肯定返回空,所以可以使用!"#text".equals(node.getNodeName())过滤掉不是标签内容的节点。
<3>根据上面的代码可知 dom取值非常的不方便,很容易空引用,并且每次读取都要全部加载,万一文件很大,就全部都要运行在内存之中,容易造成内存溢出。
2、生成xml文档
dom能够解析xml,同样肯定能生成xml,而且使用起来更加简单方便。
实现思路:
<1>DocumentBuilder提供了创建Document对象的方法;
<2>操作这个Document对象,添加节点以及节点下的文本、名称和属性值;
<3>然后利用PrintWriter写入器把封装的document对象写入到磁盘中;
具体代码如下:- public void buildXml01(){
- try {
- DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
- DocumentBuilder db = dbf.newDocumentBuilder();
- //创建一个新的document文档对象,这里返回的document是 org.w3c.dom.Document
- Document document = db.newDocument();
- //document.setXmlVersion("UTF-8");//默认UTF-8
- Element root = document.createElement("root");
- root.setTextContent("根节点内容");
- root.setAttribute("attr", "nothing");
- document.appendChild(root);//这一步必不可少,绑定父子标签的关联关系
- //TransformerFactory这个工厂专门生产Transformer的实例,Transformer实例就可以把封装好的document变成xml格式的文档了
- TransformerFactory tf = TransformerFactory.newInstance();
- Transformer transformer = tf.newTransformer();
- DOMSource source = new DOMSource(document);
- //文件写入器
- PrintWriter printWriter = new PrintWriter(new FileOutputStream("c:\\server.xml"));
- StreamResult result = new StreamResult(printWriter);
- //执行写入操作
- transformer.transform(source, result);
- System.out.println("生成xml文件成功");
- printWriter.close();
- } catch (ParserConfigurationException e) {
- e.printStackTrace();
- } catch (TransformerConfigurationException e) {
- e.printStackTrace();
- } catch (FileNotFoundException e) {
- e.printStackTrace();
- } catch (TransformerException e) {
- e.printStackTrace();
- }
- }
public void buildXml01(){
try {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
//创建一个新的document文档对象,这里返回的document是 org.w3c.dom.Document
Document document = db.newDocument();
//document.setXmlVersion("UTF-8");//默认UTF-8
Element root = document.createElement("root");
root.setTextContent("根节点内容");
root.setAttribute("attr", "nothing");
document.appendChild(root);//这一步必不可少,绑定父子标签的关联关系
//TransformerFactory这个工厂专门生产Transformer的实例,Transformer实例就可以把封装好的document变成xml格式的文档了
TransformerFactory tf = TransformerFactory.newInstance();
Transformer transformer = tf.newTransformer();
DOMSource source = new DOMSource(document);
//文件写入器
PrintWriter printWriter = new PrintWriter(new FileOutputStream("c:\\server.xml"));
StreamResult result = new StreamResult(printWriter);
//执行写入操作
transformer.transform(source, result);
System.out.println("生成xml文件成功");
printWriter.close();
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (TransformerConfigurationException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (TransformerException e) {
e.printStackTrace();
}
}

结果显示 与自己期望的内容一样。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









