







1、模型的三要素:
a) 表示(假设空间):目前很多书籍对模型的分类都是基于假设空间的
b) 评价(损失函数):是一个评价标准
c) 优化(优化算法):一个搜索算法,能够在假设空间中找到评价函数得分最高的假设
2、泛化:
训练集要和测试集分开
3、模型选择:
根据数据之间的关系和模型的表示(这里指的是假设)来选择模型;实际在进行模型选择的时候都是通过评测来实现的。
4、过拟合:
a) 表现:训练误差很小,测试误差很大
b) 解决的方案:对评测函数增加一个正则项;交叉验证选择模型参数
c) 过拟合,方差(variance);欠拟合,偏执(bias)。过拟合的表现是高方差,欠拟合的表现就是高偏执
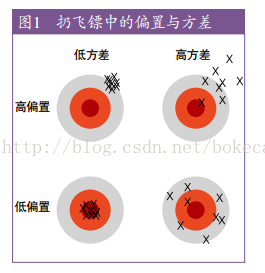
5、高维空间
a) 维度越高越难泛化,因为维度越高(特征多)输入空间越大
b) 可以通过降维来提高效果
6、特征工程
a) 自动化的特征选择:选收集全量的特征,然后计算每个特征与分类的信息增益来选择特征
b) 特征工程是和领域相关的,也是最花时间的部分
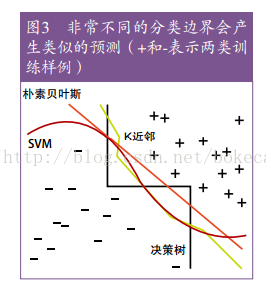
7、更多的数据胜过更聪明的算法
a) 包括更多的样例和更多的特征
b) 非常不同的算法会产生类似的边界
8、模型集成:
a) 通过重采样随机生成若干个不同的训练集,在每个集合上生成一个分类器,然后用投票的方式讲结果合并。此方法比较有效,原因是在轻度增加偏置的同时极大的降低了方差(类似于 boosting 的思想)。














 1172
1172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









