








ID3 是一种用来构建决策树的算法,它根据信息增益来进行属性选择。
关于决策树,请参见:http://blog.csdn.net/bone_ace/article/details/46299681
此处主要介绍 ID3 算法如何利用信息增益选择属性。
信息增益的计算:
信息熵:
信息熵,简称“熵”。假定训练集中目标属性为
C
,
例3-2:现有weather数据集如下,求数据集关于目标属性 play ball 的信息熵?
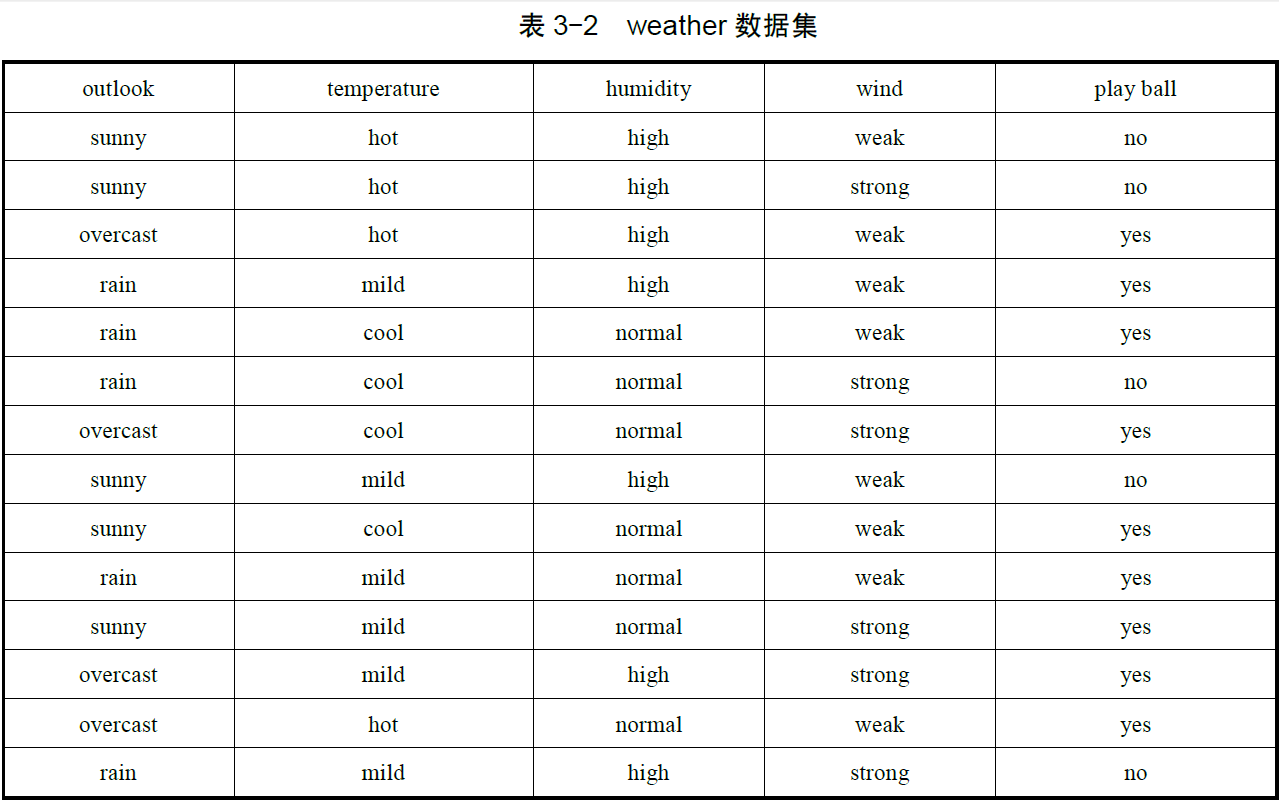
解:把weather数据集记为S,目标属性 play ball 有“
yes
”和“
no
”两个取值。其中“
yes
”占的比例为9/14,“
no
”占的比例为5/14。所以数据集关于目标属性的信息熵为:
信息增益:
信息增益记为
Gain(S,A)
,公式为:
其中
EntropyA(S)
表示按属性A划分S后的样本子集的熵。
假定属性 A 有 k 个不同的取值,从而将 S 划分为 k 个样本子集
S1,S2,…,Sk
,则有:
其中, |Si| (i,=1,2,…,k)为样本子集 Si 中包含的样本数, |S| 为样本集 S 中包含的样本数。
例3-3:依据上表weather数据集中的数据,设该数据集为S,假定用wind来划分S,求S对属性wind的信息增益。
解:属性wind有“weak”和“strong”两个取值,将数据集S划分为两部分,记为S1和S2。其中S1有8个样本,S2有6个样本。
对样本子集
对样本子集 S2 ,play ball=yes 的有3个样本,play ball=no 的有3个样本,则:
属性 wind 划分 S 后的熵为:
所以,属性 wind 划分数据集 S 所得的信息增益为:
以上是求信息增益的步骤。其实 ID3 主要的难点就是求信息增益了。
树的构建:
对于决策树的构建,就如普通树的构建一样,利用递归建立节点就行。而 ID3 的特别之处就在于:在节点选择属性的时候,它总是选择信息增益最大的那个属性作为决策节点。
例如对于上文中的例子,基于 ID3 算法应该选用哪个属性作为第一个决策节点?
解:求各个属性对于目标属性的信息增益:
Gain(S,outlook)=0.246,Gain(S,temperature)=0.029,Gain(S,humidity)=0.152,Gain(S,wind)=0.049
其中
Gain(S,outlook)
最大,所以选择
outlook
属性作为根节点。
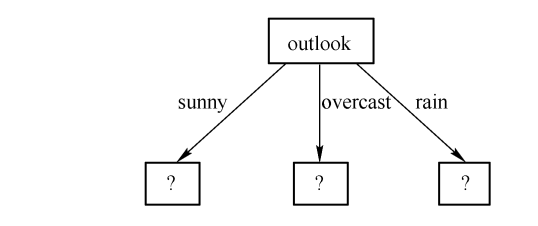
接下来对
sunny
分枝求哪个属性作为子节点?
需要注意的是:此时用的数据集是子集
Ssunny
,而不是最初的那个
weather
数据集。
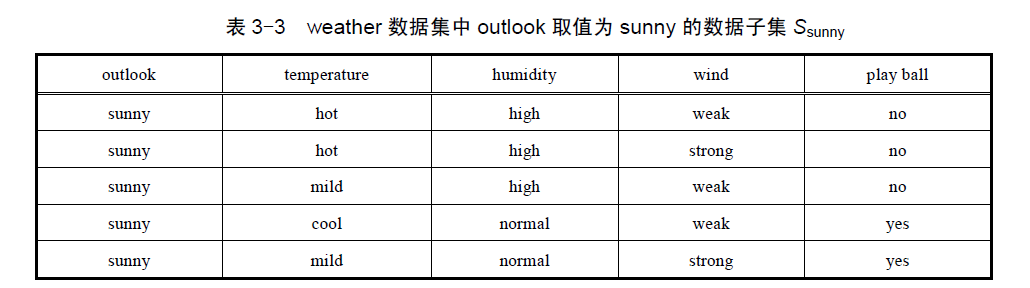
分别求temperature、humidity、wind对于目标属性 play ball 的信息增益,然后取最大值作为子节点。
……
……
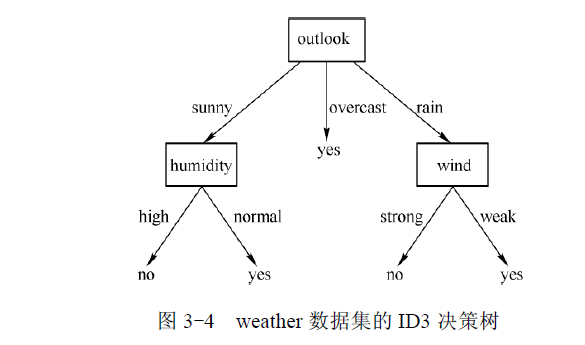
最终构建成的决策树如下:
ID3的优缺点:
优点:
ID3的主要思想是:在决策树的非叶子结点进行属性选择的时候,用信息增益作为选择的标准,每一个非叶子结点都选择当前的候选属性中信息增益最大的那个属性。这是贪心算法的思想,使得每一个非叶子结点在进行测试时都能获得关于被测数据的最大类别信息,从而把整个决策树的熵值降到最小。
缺点:
- ID3只能处理离散型数据,无法处理连续性数据。例如上文中的wind属性只有“strong”和“weak”两个取值,是离散型的。如果换成用0~100的实数代表wind的强度,ID3 将无法处理。
- 如果某个属性的数据含有缺失值,ID3 将无法处理。
- 信息增益的缺陷:信息增益在类别多的属性上计算结果会大于类别少的属性上的计算结果,这会导致 ID3 算法偏向选择具有较多分枝的属性,而分枝多的属性不一定是最优的选择。














 2968
2968











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









