






引言:朴素贝叶斯分类器作为基础的分类算法,早在基础数学时期就已经被使用,目前在各行各业中更是被广泛使用。近几年车厘子在中国地区卖得火热,面对车厘子和樱桃,很多老百姓很难分清楚,那么算法能帮我们区分吗?
本文选自《大数据时代的算法:机器学习、人工智能及其典型实例》。
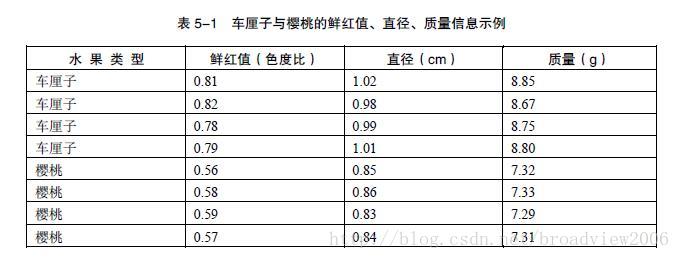
车厘子是樱桃吗?它们有区别是什么呢?通过在水果市场采集,获得了一些关于车厘子和樱桃的相关特征数据。
通过现有的车厘子和樱桃的数据,在包含车厘子和樱桃的混合水果中,随机给一个车厘子或者樱桃,识别它是樱桃或者车厘子的可能性哪个大? 本文我们将用朴素贝叶斯(Naive Beyesian)来解决这个问题,但在开始之前我们来简单了解下一些相关知识。

贝叶斯定理
朴素贝叶斯是以贝叶斯定理为基础的概率分类模型。贝叶斯定理是概率论中的一个定理,它跟随机变量的条件概率及边缘概率分布有关。在有些关于概率的解说中,贝叶斯定理能够告知我们如何利用新证据修改已有的看法。这个名称来自于托马斯·贝叶斯。
通常,事件A在事件B(发生)的条件下的概率与事件B在事件A的条件下的概率是不一样的;然而,这两者有着确定的关系,贝叶斯定理就是对这种关系的表示。贝叶斯公式定义在事件B出现的前提下,事件A出现的概率等于事件A出现的前提下事件B发生的概率乘以时间A出现的概率再除以时间B出现的概率。通过联系事件A与事件B,计算从一个事件产生另一事件的概率,即从结果上溯原。因此,贝叶斯定理公式如下所示:
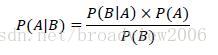
在理解贝叶斯定理的基础上,可以较好地理解基于朴素贝叶斯的分类模型。信息分类是信息处理中最基本的模块,每一段信息无论长或短,都由若干特征组成,因此可以将所有特征视为一个向量集W=(w1,w2,w3,…,wn),其中wi即表示其中第i个特征。而信息的分类也可以视为一个分类标记的集合C={c1,c2,c3,…,cm}。在进行特征学习之前,特征wi与分类标记cj的关系不是确定值,因此需要提前计算P(C|W),也就是在特征wi出现的情况下,信息属于分类标记C的概率,可根据贝叶斯计算,公式如下:
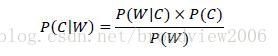
因此,可以从信息分类的角度理解贝叶斯公式,即表示为:在特征wi出现的情况下是否是特征类别cj取决于在特征分类标记cj情况下特征wi出现的概率以及wi在所有特征中出现的概率。P(W)的意义在于如果这个特征在所有信息中出现,那么用特征wi去判定是否属于分类标识cj的概率越低,越不具备代表性。
车厘子与樱桃问题的解决
朴素贝叶斯是一种有监督的学习方式,可以利用伯努利模型(Bernoulli Model)以文件为粒度进行文本分类。
(有监督学习是有监督分类的实质,有监督分类是指根据已有的训练集提供的样本,通过不断计算,从样本中学习选择特征参数,对分类器建立判别函数以对被识别的样本进行分类。有监督分类方式可以有效利用先验数据,对后验数据进行校验,但是缺点也比较明显。首先,训练数据是人为收集,具有一定的主观性,并且人为收集数据也会导致花费一定的人力成本;其次,最终分类器分类的结果中,分类结果只可能是训练数据中的分类类型,不会产生新的类型。)
假设训练集样本的特征满足高斯分布,得到下表。
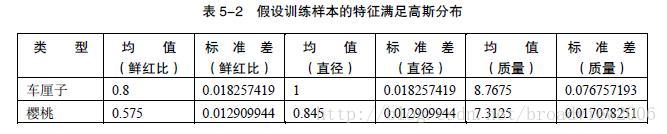
我们认为两种类别是等概率的,也就是P(车厘子)=P(樱桃)=0.5。概率密度函数如下:
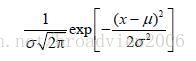
验证过程先给出一个待确定属于车厘子还是樱桃的测试样本,见下表。

验证的标准则是:得到的样本属于樱桃还是车厘子的后验概率大者。

上述式子用于求取车厘子的后验概率,
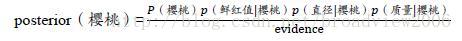
上式用于求取樱桃的后验概率。证据因子evidence(通常是常数)用来对各类的后验概率之和进行归一化。
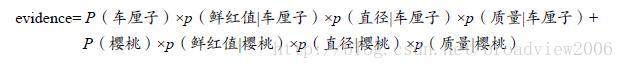
证据因子是一个常数(在高斯分布中通常是一个常数),所以可以忽略,只需计算后验概率式子中的分子即可。接下来通过样本的特征值来判别样本所属的类别。
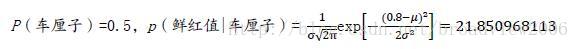
其中,μ=0.8,α=0.018257419,二者均为训练集样本的高斯分布参数。注意,这里计算的是概率密度而不是概率。

通过上述计算可以看出,车厘子的后验概率分子较大,由此可以预计这个样本属于车厘子的可能性较大。
本文选自《大数据时代的算法:机器学习、人工智能及其典型实例》,点此链接可在博文视点官网查看此书。

















 4642
4642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









