







6. 时间都去where了,青春不能等,调度也是
除了上述优化, 我们还注意到一个奇怪的现象:
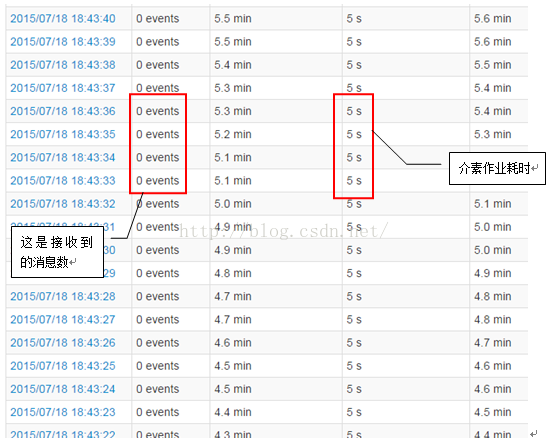
怎么回事, 即使接收不到消息都要花掉5秒?!! 虽然Spark Streaming空转依然会产生空task, 这些空task依然会消耗序列化, 压缩, 调度等时间, 但也不至于那么多吧!!!
我们拿一个Stage看看, 就拿处理Kafka消息的那个Stage作例子吧:

Kafka没有任何消息进来的情况下, 这个Stage竟然耗费我3秒青春, 有无搞错! 时间都去where了?
接着我们看了一下task的时间分布图:

从图中, 我们可以看到Spark总共调度分发了两批次task set, 每个task set的处理(含序列化和压缩之类的工作)都不超过100毫秒, 那么该Stage何来消耗3秒呢? 慢着, 貌似这两批次的task set分发的时间相隔得有点长啊, 隔了2秒多. 为什么会隔这么就才调度一次呢?
此处要引入一个配置项” spark.locality.wait”, 它配置了本地化调度降级所需要的时间. 这里概要补充下Spark本地化调度的知识, Spark的task一般都会分发到它所需数据的那个节点, 这称之为”NODE_LOCAL”, 但在资源不足的情况下, 数据所在节点未必有资源处理task, 因此Spark在等待了” spark.locality.wait”所配置的时间长度后, 会退而求其次, 分发到数据所在节点的同一个机架的其它节点上, 这是”RACK_LOCAL”, 当然, 也有更惨的, 就是再等了一段” spark.locality.wait”的时间长度后, 干脆随便找一台机器去跑task, 这就是”ANY”策略了.
而从上例看到, 即使用最差的”ANY”策略进行调度, task set的处理也只是花了100毫秒, 因此, 没必要非得为了”NODE_LOCAL”策略的生效而去等待那么长的时间, 特别是在流计算这种场景上. 所以把” spark.locality.wait”果断调小, 从1秒到500毫秒, 最后干脆调到100毫秒算了.
调了之后的处理时间是酱紫的:
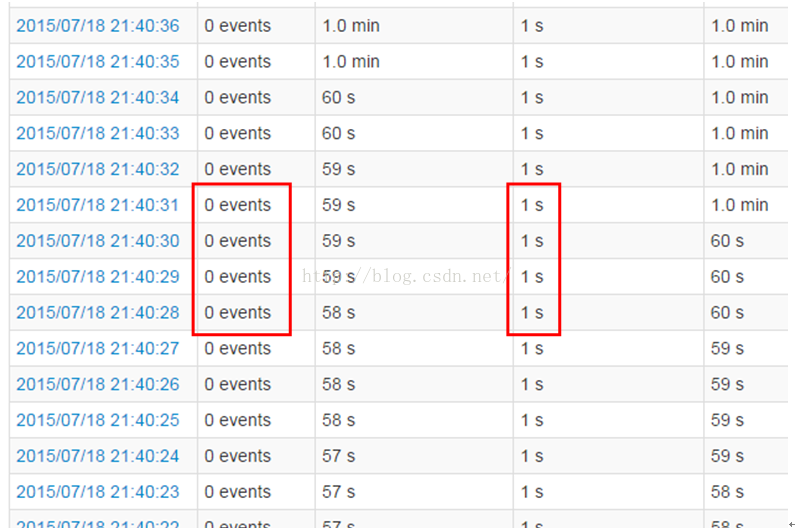
原来两个Stage空转需要5秒, 现在变成1秒了. 调度不能等啊.
7. 进一步减少空转耗时
上一节以处理Kafka消息的那个Stage作为例子, 讲了如何发现时间消耗, 如何减少等待时间, 这里再讲下在没数据处理的情况下如何非侵入式地减少不必要的空转. (呵呵,所谓非侵入式就是不修改Spark源代码啦,否则后期维护很烦人的)
这一节, 我们以进行数据join的Stage作为例子.

该Stage所做的事情就是从HDFS中加载数据, 进行转换处理后, 缓存在内存中, 然后与Kafka过来的数据在本机内存中进行join操作. 空转时的耗时是1秒, 时间分布如下:

调度等待和序列化的耗时还算正常, 但为毛在task set中啥都没有的情况下对task set的处理都需要1秒呢?
通过研究可知, 即使join的双方有一方没数据的情况下, Spark依然会循环另一方的数据, 以按key对value进行汇总.

额, 就是这个循环耗了我们近1秒青春. 而其实在这个场景下, 当Kafka方面没数据输入时, 就根本不要进这个循环, 直接返回空就是了. 因此我们引入了新的SkipableCoGroupedRDD.
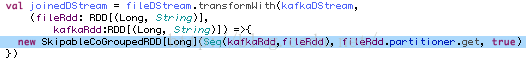
该RDD负责两个不同RDD的join操作, 但与一般的join操作不同的是, 它会把第一个RDD作为是否能够跳过join操作的参照, 若第一个RDD中根本没有数据, 那么整个join操作会被跳过.
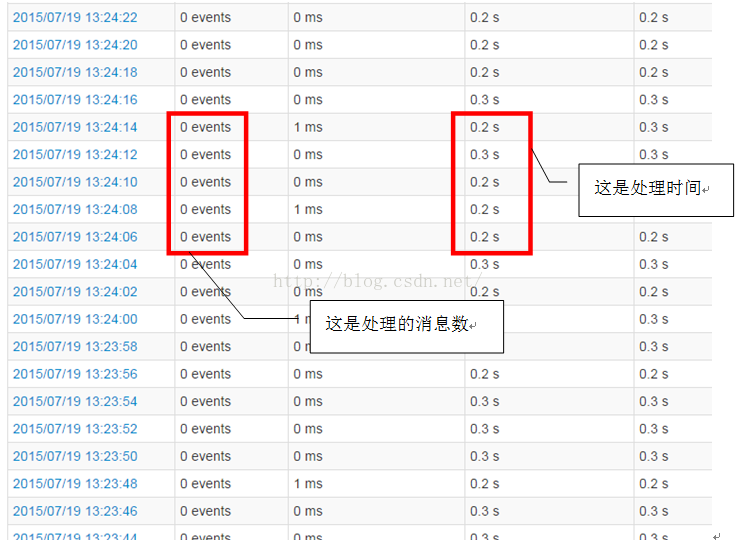
使用了SkipableCoGroupedRDD的处理结果如下:
在空转的情况下, 整个join的Stage的处理时间只需要0.2秒. 空转作业的处理时间进一步降低到0.2~0.3秒.















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









