







从50多分钟到3分钟的优化
某推荐系统需要基于Spark用ALS算法对近一天的数据进行实时训练, 然后进行推荐. 输入的数据有114G, 但训练时间加上预测的时间需要50多分钟, 而业务的要求是在15分钟左右, 远远达不到实时推荐的要求, 因此, 我们与业务侧一起对Spark应用进行了优化.
另外提一下, 该文最好与之前我写的另一篇blog < Spark + Kafka 流计算优化 > 一起看, 因为一些细节我不会再在该文中描述.
优化分析
从数据分析, 虽然数据有114G, 但ALS的模型训练时间并不长, 反而是数据加载和ALS预测所占用的时间较长. 因此我们把重点放在这两点的优化中.
从Spark的Web UI可以看到, 数据加载的job中task的数量较多, 较小. 模型预测的job也是有这样的问题, 因此, 可以猜测并行度过大造成了集群的协调负荷过重.
仅降低并行度和优化JVM 参数
我们用常见的”rdd.repartitionBy”把并行度降低后, 作业计算耗时减少并不明显, 且在模型预测的job中会有executor死掉的现象. 进而查看日志, 发现是内存占用过多, yarn把Spark应用给kill了.
为解决该现象, 加入这些JVM参数: “ -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:MaxTenuringThreshold=72 -XX:NewRatio=2 -XX:SurvivorRatio=6 -XX:+CMSParallelRemarkEnabled -XX:+ParallelRefProcEnabled -XX:+CMSPermGenSweepingEnabled -XX:+CMSClassUnloadingEnabled -XX:MaxTenuringThreshold=31 -XX:SurvivorRatio=8 -XX:+ExplicitGCInvokesConcurrent -XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses -XX:+AlwaysPreTouch -XX:-OmitStackTraceInFastThrow -XX:+UseCompressedStrings -XX:+UseStringCache -XX:+OptimizeStringConcat -XX:+UseCompressedOops -XX:+CMSScavengeBeforeRemark -XX:+UseBiasedLocking -XX:+AggressiveOpts " 具体说明和原因请参考本人的另一篇blog < Spark + Kafka 流计算优化 >.
笛卡尔积操作中的预先分块
作了上述例行优化后, ALS预测步骤的耗时减少依然不明显, 为发掘原因, 我们看了下源码, 惊奇的发现在ALS预测中竟然是用了笛卡尔积操作, 114G的数据少说也有几千万行记录, 几千万行记录进行笛卡尔积, 不慢才怪吧.
还好, 我们有扩展版的ALS预测方法, 可以将数据预先分块, 而不必一行行的进行笛卡尔积, 加快了笛卡尔积的速度.
val recommendations = ExtMatrixFactorizationModelHelper.recommendProductsForUsers( model.get, numRecommendations, 420000, StorageLevel.MEMORY_AND_DISK_SER )
该方法会对model中的userFeatures和itemFeatures矩阵进行预先分块, 减少网络包的传输量和笛卡尔积的计算量.
这里的第三个参数是每一个块所包含的行数, 此处的420000表示当我们对userFeatures或itemFeatures进行分块时, 每一个块包含了矩阵的420000行.
如何计算这里的一个块要包含多少行呢, 举例如下:
由于ALS算法中设置的rank是10, 因此生成的userFeatures和itemFeatures的个数是10, 它们的每一行是(Int,Array[Double]), 其中Array.size是10.
因此可根据如下计算每行所占的空间大小:
空Array[10]的大小=16+8*10=96Byte. 数组中的元素是Double, 十个Double对象的大小是 16*10=160Byte. 作为key的Integer的大小是16Byte. 因此每行占空间96+160+16=212Byte.
另外,要计算带宽: 由于是千兆网卡,因此带宽为1Gbit,转换为Byte也就是128MByte的带宽.
考虑到” spark.akka.frameSize=100”以及网络包包头需要占的空间, 和Java的各种封装要占的空间, 我们计划让1个block就几乎占满带宽, 也就是一个block会在100MByte左右.
因此, 一个block要占 60*1024*1024/212=296766行, 因此blocksize=494611, 考虑到各个object也占内存, 因此行数定为420000左右.
在分块后ExtMatrixFactorizationModelHelper.recommendProductsForUsers中会对块进行重新分区, 以达到基于块的均匀分布.
提高文件加载速度
以前都是加载小文件, 每个文件才几M大小, 远远低于Hadoop的块大小, 使得IO频繁, 文件也频繁打开关闭, 加载速度自然就慢. 为解决该问题, 我们使用sc.wholeTextFiles(dirstr,inputSplitNum)来加载HDFS的文件到Spark中. 该方法使用Hadoop的CombineFileInputFormat把多个小文件合并成一个Split再加载到Spark中.
但其实, 加载速度对整个Job的运行效率影响不大, 效果有限.

上图,是val inputData = sc.wholeTextFiles(dirstr,80) 和RangePartition.
貌似加载速度也好不到哪儿去.第一个job用了11min
'
上图, 用的是val inputData = sc.textFile(dirstr)和RangeRepartition,同等情况下,加载也需要11min. (见job6)

上图,是val inputData = sc.wholeTextFiles(dirstr,120) 和RangePartition.
貌似提高了wholeTextFiles()的split数量可以提升性能, 从8.4min多(此时split为80左右)到现在的8.1min

上图,是val inputData = sc.wholeTextFiles(dirstr,220) 和RangePartition. 第一次加载提升到6.0min.
其它job由于loclity的问题,时间有所拉长, 影响不大.

上图,是val inputData = sc.wholeTextFiles(dirstr,512) 和RangePartition. 第一次加载要7.1min. 估计220个split应该是个比较好的值了. 按比例就是 220(file split数) / 27000(小文件数) = 0.8% , 该场景中每个小文件10M左右. 也就是每个file split包含123个小文件, 每个file split 1230M, 也就是约1G左右.
减少笛卡尔积计算量
回到对笛卡尔积计算的优化, 因为50分钟的计算量基本上都是耗在笛卡尔积的计算上的.
我们先看一下task的分布图, 由图看到, 数据并不是十分散列:
 猜测原因肯是通过
Array.mkString.hashCode
作为
key
并不能保证数据的均匀散列
.
因此
,
我们
disable
掉了在笛卡尔积计算前的预分块时的再分区
,
而是把再分区提到分块之前
.
猜测原因肯是通过
Array.mkString.hashCode
作为
key
并不能保证数据的均匀散列
.
因此
,
我们
disable
掉了在笛卡尔积计算前的预分块时的再分区
,
而是把再分区提到分块之前
.
这样一来, task分布稍微均衡了一些, 但依然不甚理想. 为了合理的降低task数量和均匀task的分布, 我们进一步使用了Spark扩展版本的自动分区功能.
val userFactors = ExtSparkHelper.repartionPairRDDBySize(oldUsrFact, ThreeM)
这个方法有两个参数, 第一个是需要分区的RDD, 第二个是我们期望的每一个task的input data的大小. 一般来说, input data与计算产生的data的大小相差不大, 但笛卡尔积却不同, 有可能产生上百倍的中间数据量. 因此, 我这里设置的每个task的input data是3M, 计算产生的中间数据刚好在1G左右, 一个executor可以同时跑3个task, 也算是比较理想的.
优化后的task分布图也比较理想, 十分均匀且没有任何浪费, 如下:

因此, 这一步优化后, 原笛卡尔积的运行速度从几十分钟变为十几秒.
整个ALS应用原来跑114G数据需要20多分钟,如下图现在只需要不到4min:
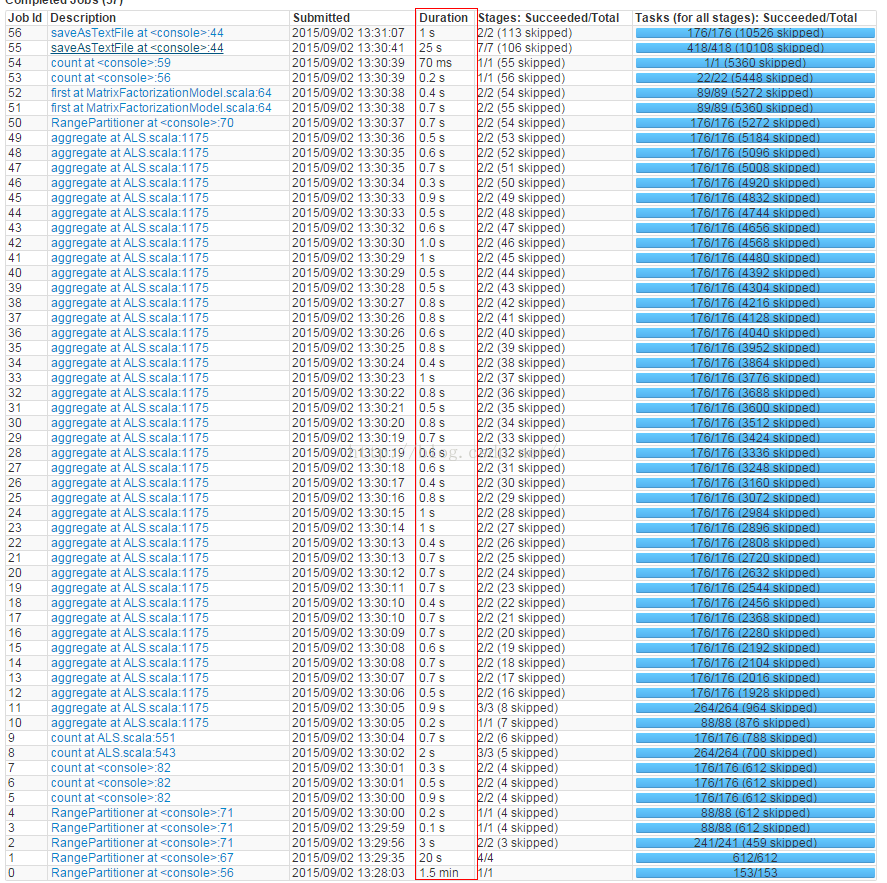
试了一下跑一天的全量数据, 共231.9G, 则原来需要1个多小时,现在只要不到6分钟, 如下图:
















 8461
8461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









