









第四章 编写结构化程序
4.1 回到基础
1 赋值
学过C,习惯了Java再过来学Python,感觉完全像《罗马假日》里安妮公主穿便装去城里撒欢一样。不需要声明,不需要初始化,随便用,太随意了。但是很快我就发现,自由对于理性不足的人来说是充满陷阱的。过于自由的语法提高了对经验的要求,新手很容易出现问题。所以还是决定,继续沿用MVC的模式和华为的Java编程规范来写Python。也许等多写写后可以去看看Python的经验贴,学学新的风格。
既然到了这一步那就换一个IDE吧,参考Eclipse和PyDev搭建完美Python开发环境(Windows篇)和 解决 Eclipse+pydev安装配置找不到pydev的问题,这都是前人惨痛教训下积累的经验,得好好借鉴,避免不必要的时间和精力的浪费。本人的机器上使用的是win32下的Eclipse,Python2.7,安装PyDev for Eclipse 2.7.0.2012100419,亲测可用。
2 等式
is比==更加严格,就是不只是要相等,而且就是要使一个对象。A和B是双胞胎,所以A==B,但是A is B是False。Id函数应该就是查看作为对象的id,就像查看A和B的身份证,证明了他们不是一个。
3条件语句
if element和if len(element) >0据说是等价的,还记得在Java里为了判断字符串是否为空,常常使用if(element==null||element.equals("")),先判断是不是对象,如果是,再判断是不是空字符串。
4.2 序列
1 序列概述
Python的元组相当于Java的数组,Python的字典类似于Java的Hashmap。
这些序列类型之间可以相互转换, tuple(s) 将任何种类的序列转换成一个元组, list(s)将任何种类的序列转换成一个链表,join() 函数将一个字符串链表转换成单独的字符串。
详细函数p136
2 合并不同类型的序列
#下划线约定可以用下划线表示我们不会使用其值的变量。
至于链表和数组的使用,我的习惯都是链表里的结构化数据用数组,以每个文档当对象考虑的时候,可以将词存储为一个数组(当然很多时候是Hashmap,看需要)。
3产生器表达式
max(w.lower() for w innltk.word_tokenize(text))比max([w.lower() for w in nltk.word_tokenize(text)])更高效,类似于后者先计算得到[w.lower() for w in nltk.word_tokenize(text)]存在内存里,然后再进行排序比较,而前者是对数据流进行处理。所以尽量使用前一个,因为后者对内存的开销更大。
怎么说呢,一个编程语言的语法就那么多,但程序员的水平却可以相差很多,经验和技巧的重要性不言而喻。就像大家都学了英语,能说点,会写点,但是绝大部分的水平跟林语堂那样的大师是没法比的。当然,大师是少数的,但是剩下的人还是可以分成高级,专业和业余的几个层次来。高级程序员得靠猎头去挖的,所以很多招工的广告都是针对有几年经验,有经验的可以叫做专业人士的那批人。对于我这样的业余选手,还是好好的多学习,多写代码,先混个“手熟”吧。
4.3 风格的问题
对于书里推荐的Donald Knuth的《计算机程序设计艺术》,我会想说“呵呵”,这套书摆在图书馆里就像耶稣受难像摆在教堂里一样,没什么人敢去动的。微博里有人吐槽说看到这套传世巨作的感受时说“突然产生的敬畏感让人翻一下的勇气都没有了”。这是真的,要不看看。

1 Python 代码风格
代码布局中每个缩进级别应使用 4 个空格。你应该确保当你在一个文件中写 Python 代码时,避免使用 tab 缩进,因为它可能由于不同的文本编辑器的不同解释而产生混乱。每行应少于 80 个字符长,如果必要的话,你可以在圆括号、方括号或花括号内换行,因为 Pyth
on 能够探测到该行与下一行是连续的。
2 过程风格与声明风格
每行代码执行一个完整的、有意义的工作,避免在没有必要的时候使用临时变量。
3 计数器的一些合理用途
pprint模块中使用的格式化可以按照一种格式正确的显示数据, 这种格式即可被解析器解析, 又很易读. 输出保存在一个单行内, 但如果有必要, 在分割多行数据时也可使用缩进表示。
学习C的经历让我很喜欢使用I,j,k,m,n这些字母写一个套一个的计数的for循环,搞得缩进混乱,效率不高,看来到了python里面改改这个毛病。
4.4 函数:结构化编程的基础
1 函数的输入和输出
感觉Python可以是面向过程的,也可以是面向对象的。面向对象编程时,记得声明加self。
2 参数传递
能由外部传递的参数尽量使用传递,需要设定的固定参数尽量在类外单独声明,或者读配置文件,避免一切“神仙数”,否则后患无穷,会成为调试者和维护者的噩梦。
3 变量的作用域
当你在一个函数体内部使用一个现有的名字时,Python 解释器先尝试按照函数本地的名字来解释。如果没有发现,解释器检查它是否是一个模块内的全局名称。如果没有成功,最后,解释器会检查是否是 Python 内置的名字。这就是所谓的名称解析的 LGB 规则:本地(local),全局(global),然后内置(built-in)。Python太随意了,更要保持一个好的变量命名和使用规则,避免没有bug给自己创造bug。
4参数类型检查
Python 不会强迫我们声明变量的类型,这允许我们定义参数类型灵活的函数。但是必须对不同时刻调用的变量时什么类型有掌握,python提供的assert函数还是很好的,打印错误还可以让它写入错误日志,维护会方便一些。
5功能分解
结构良好的程序通常都广泛使用函数。当一个程序代码块增长到超过 10-20 行,如果将代码分成一个或多个函数,每一个有明确的目的,这将对可读性有很大的帮助。这类似于好文章被划分成段,每段话表示一个主要思想。
6文档说明函数
还是写吧,为以后的人方便。
4.5 更多关于函数
努力多尝试。
4.6程序开发
开源好用,但要注意版本还要保持一颗怀疑的心,有的时候并不是自己的问题是开源的包里有问题。实验室就出过类似的事,后来定位到bug给维护组发了邮件。
1 误差源头
繁琐浮躁不谈,调试代码是很难的,因为有那么多的方式出现故障。我们对输入数据、算法甚至编程语言的理解可能是错误的。
(1)输入的数据可能包含一些意想不到的字符。
(2)提供的函数可能不会像预期的那样运作。
(3) 对 Python 语义的理解可能出错。
2调试技术
由于大多数代码错误是因为程序员的不正确的假设,你检测 bug 要做的第一件事是检查你的假设。通过给程序添加 print 语句定位问题,显示重要的变量的值,并显示程序的进展
程度。
Python 提供了一个调试器,它允许你监视程序的执行,指定程序暂停运行的行号(即断点) ,逐步调试代码段和检查变量的值。你可以如下方式在你的代码中调用调试器:
>>>import pdb
>>>import mymodule
>>>pdb.run('mymodule.myfunction()')
它会给出一个提示(Pdb),你可以在那里输入指令给调试器。输入 help 来查看命令的完整列表。输入 step(或只输入 s ) 将执行当前行然后停止。如果当前行调用一个函数,它将进入这个函数并停止在第一行。输入 next(或只输入 n) 是类似的,但它会在当前函数中的下一行停止执行。break(或 b)命令可用于创建或列出断点。输入 continue(或 c)会继续
执行直到遇到下一个断点。输入任何变量的名称可以检查它的值。
3防御性编程
防御性编程是一种细致、谨慎的编程方法。为了开发可靠的软件,我们要设计系统中的每个组件,以使其尽可能地“保护”自己。防御性编程是一种编程习惯,是指预见在什么地方可能会出现问题,然后创建一个环境来测试错误,当预见的问题出现的时候通知你,并执行一个你指定的损害控制动作,如停止程序执行,将用户重指向到一个备份的服务器,或者开启一个你可以用来诊断问题的调试信息。这些防御性编程环境通常的构造方法有:添加声明到代码中,执行按契约进行设计,开发软件防御防火墙,或者简单添加用来验证用户输入的代码。
当然,防御性编程并不能排除所有的程序错误。但是问题所带来的麻烦将会减少,并易于修改。防御性程序员只是抓住飘落的雪花,而不是被埋葬在错误的雪崩中。防御性编程是一种防卫方式,而不是一种补救形式。我们可以将其与在错误发生之后再来改正错误的调试比较一下。调试就是如何来找到补救的办法。
以我当年学电路分析处理的经历来说,防御性编程就像做电路板,对于每一个模块,必须保证它本身的抗干扰性足够好,否则组装起来能正常工作简直不可能。要对每一个模块的输入输出有把我,设计测试实验,在不同的输入模式下检查输出的可靠性,足够可靠以后再进行整体联调。
4.7算法设计
1 分而治之
自上而下的设计思路,典型的美式思维,简单粗暴但是有效。
2递归
不管书上怎么说,总是觉得递归这种东西能不用就不用的好。而且正如书上说的,尽管递归编程结构简单,它是有代价的。每次函数调用时,一些状态信息需要推入堆栈,这样一旦函数执行完成可以从离开的地方继续执行。出于这个原因,迭代的解决方案往往比递归解决方案的更高效。
3权衡空间与时间
科研可以不怎么考虑时间,但是做产品的话延迟对用户体验的损害就是致命的。
4动态规划
不知道理解的对不对,DP感觉就是在用空间换时间,尽量不重复求解,从较小问题解逐步决策,构造较大问题的解。比较好的方式是采用自上而下的结合递归的动态规划。
备注一下,得编一个试一下效果才行了。
4.8 Python 库的样例
1 Matplotlib 绘图工具
代码参看NltkTest136. MatplotlibTest(self,categories, words, counts):
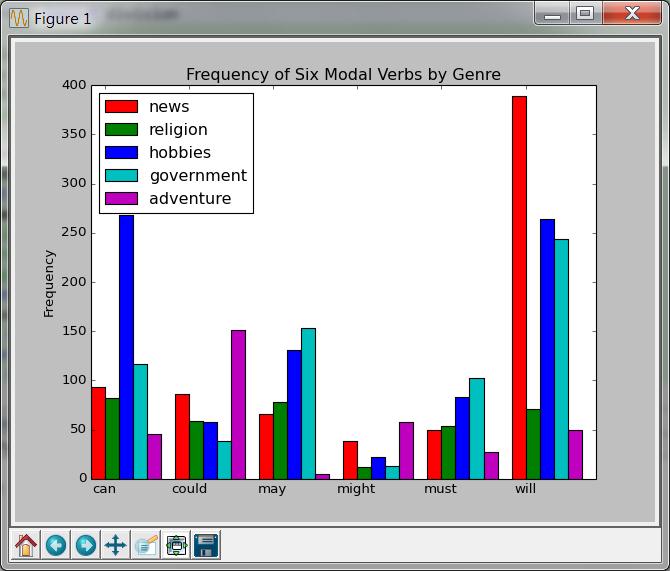
这和书上的图一样,对我来说这并没有什么意义。有意义的是我最开始的得到的是这样的图
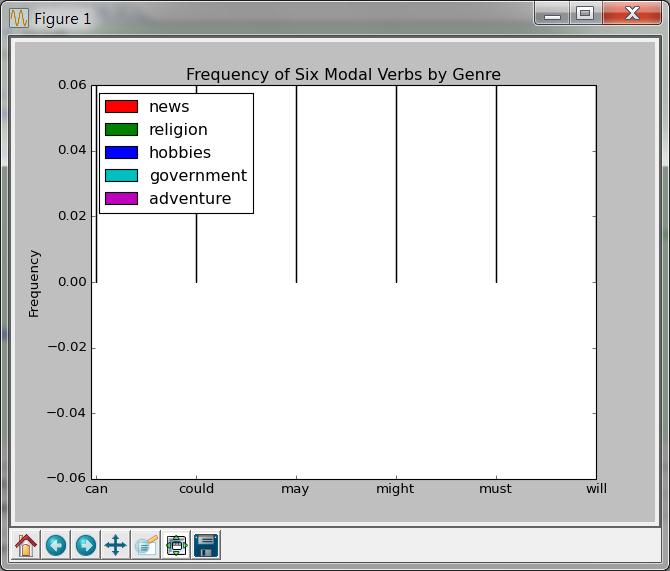
很明显是有问题的,所以我去研究了一下代码,逻辑没有啥问题,不过在print c*width我得到的都是0,这让我觉得很可疑,因为如果都是0就没有意义了,再往上看,又一个除法运算,好吧,问题就出在这里,它没有得到一个大于1的数,所以都是0,那么就是没有进行浮点运算,额,没有from __future__import division,问题解决。虽然问题不大,但是解决问题了总归是有意义的。
2 NetworkX
运行书上的代码,报错
ImportError:('requires pygraphviz ', 'http://networkx.lanl.gov/pygraphviz ', '(notavailable for Python3)')
看来是个版本的问题,但是我装的2.7,怎么会提示这个呢,缺少pygraphviz,去目录下使用easy_install装一个不就行了,于是我便去了。在C:\Python27\Scripts\下使用命令窗口,输入指令easy_install pygraphviz,执行结果是悲惨的这个
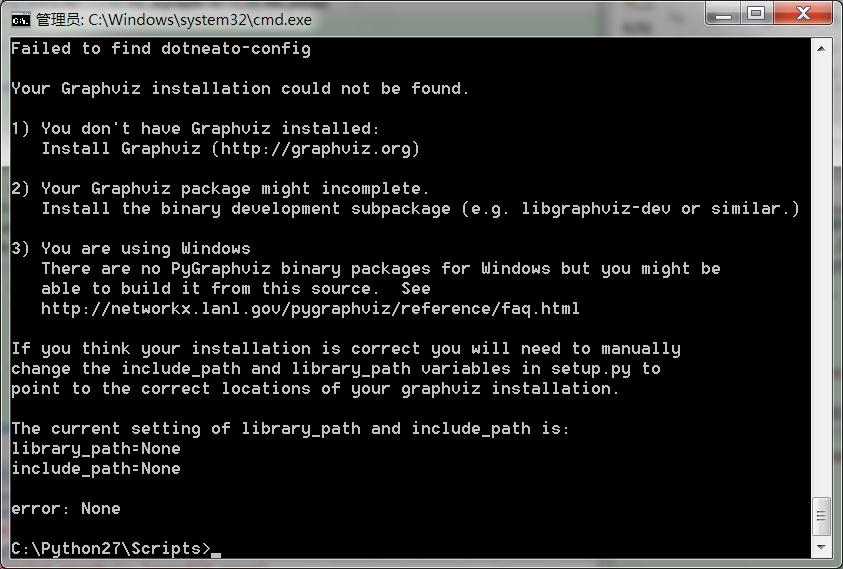
看到(3),不得不再次吐槽一下,windows和Python真的不亲啊。
好吧,去官网(http://pygraphviz.github.io/documentation/development/install.html#quick-install)
下source code再安装。网站提示
(1) Clone the pygraphviz repostitory gitclone https://github.com/pygraphviz/pygraphviz.git
(2) Change directory to “pygraphviz”
(3) Run “python setup.py install” to buildand install
(4) (optional) Run “python setup_egg.pynosetests” to execute the tests
下载以后,依次行事,走到激动的第(4)步
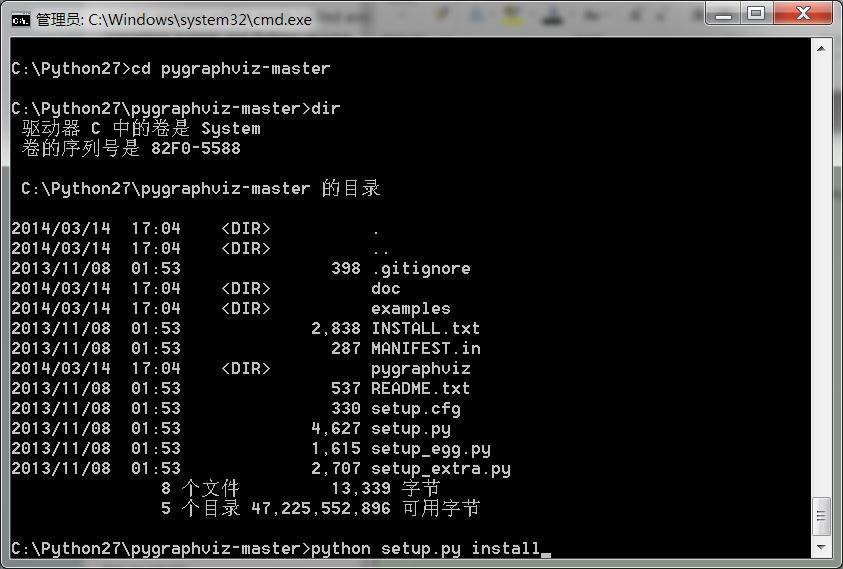
依旧被报错C1083无法打开包括文件:graphviz/cgraph
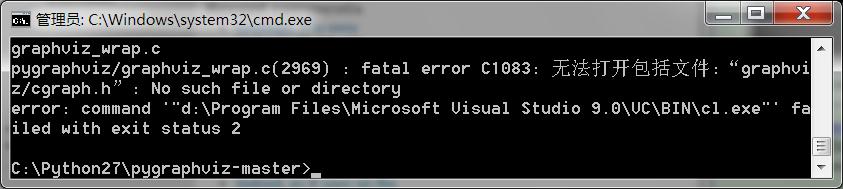
于是我又做了一个艰难的决定去装一下graphviz。为此我去了
http://www.graphviz.org/Download_windows.php
此刻,我怀着忐忑的心情等待着这个30多M的安装包下完,在我心中暗暗又做了一个决定,如果Windows下真的容不下Python,还是换Linux吧,太虐心了。
还是不行啊!!!
晚上换Ubuntu!
3 CSV
语言分析工作往往涉及数据统计表,包括有关词项的信息、试验研究的参与者名单或从
语料库提取的语言特征。
4 NumPy
NumPy 包(基本的数值运算包)对 Python 中的数值处理提供了大量的支持。
#-*- coding: utf-8-*-
'''
Created on 2014-3-14
@attention: Test about Python coding style
@author: liTC
'''
from __future__ import division
import nltk
import matplotlib
import numpy
import pylab
import networkx as nx
from nltk.corpus import wordnet as wn
colors = 'rgbcmyk' # red, green, blue, cyan, magenta, yellow, black
class NltkTest136:
def __init__(self):
print 'Initing...'
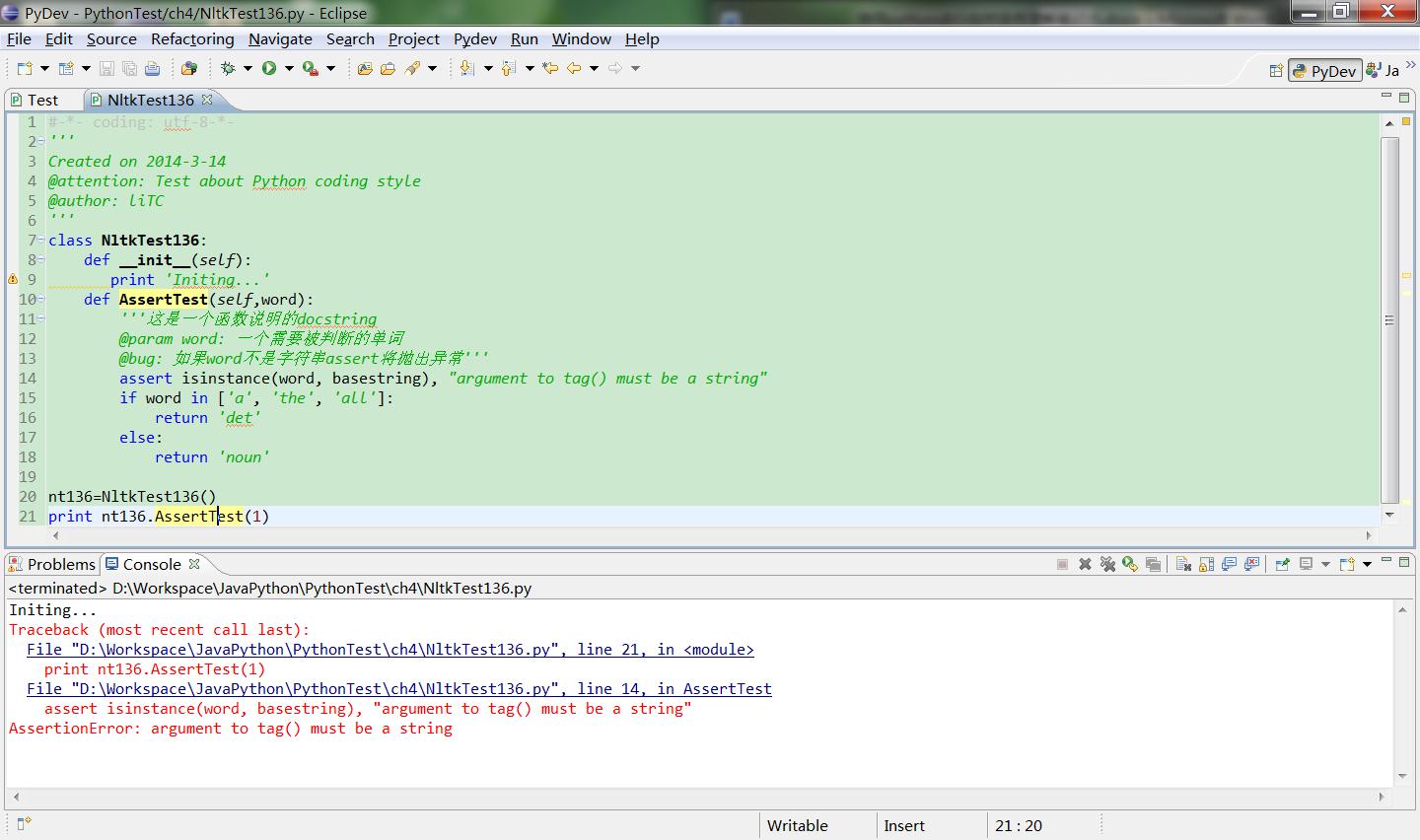
def AssertTest(self,word):
'''这是一个函数说明的docstring
@param word: 一个需要被判断的单词
@bug: 如果word不是字符串assert将抛出异常'''
assert isinstance(word, basestring), "argument to tag() must be a string"
if word in ['a', 'the', 'all']:
return 'det'
else:
return 'noun'
def MatplotlibTest(self,categories, words, counts):
print "Plot a bar chart showing counts for each word by category"
ind=pylab.arange(len(words))
width=1/(len(categories) + 1)
bar_groups=[]
for c in range(len(categories)):
print c*width
bars = pylab.bar(ind+c*width, counts[categories[c]], width,color=colors[c % len(colors)])
bar_groups.append(bars)
pylab.xticks(ind+width, words)
pylab.legend([b[0] for b in bar_groups], categories, loc='upper left')
pylab.ylabel('Frequency')
pylab.title('Frequency of Six Modal Verbs by Genre')
pylab.show()
def traverse(self,graph,start,node):
graph.depth[node.name] = node.shortest_path_distance(start)
for child in node.hyponyms():
graph.add_edge(node.name, child.name)
nt136.traverse(graph, start, child)
def hyponym_graph(self,start):
G = nx.Graph()
G.depth = {}
nt136.traverse(G, start, start)
return G
def graph_draw(self,graph):
nx.draw_graphviz(graph,\
node_size = [16 * graph.degree(n) for n in graph],\
node_color = [graph.depth[n] for n in graph],\
with_labels = False)
#test Assert
nt136=NltkTest136()
#print nt136.AssertTest(1)
#test Matplotlib
genres = ['news', 'religion', 'hobbies', 'government', 'adventure']
modals = ['can', 'could', 'may', 'might', 'must', 'will']
cfdist = nltk.ConditionalFreqDist((genre, word)\
for genre in genres\
for word in nltk.corpus.brown.words(categories=genre)\
if word in modals)
counts = {}
for genre in genres:
counts[genre] = [cfdist[genre][word] for word in modals]
nt136.MatplotlibTest(genres, modals, counts)
#test NetworkX fail,windows下缺少组件不能执行
#dog = wn.synset('dog.n.01')
#graph = nt136.hyponym_graph(dog)
#nt136.graph_draw(graph)














 1122
1122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









