







第三章 加工原料文本
3.1 从网络和硬盘访问文本
1 电子书
古腾堡项目的其它文本可以在线获得,
整个过程大概需要几十秒(实验室网络不行是硬伤)

使用raw()可以得到原始的字符串。但是raw得到的数据绝对不是我们能直接拿去分析的,还要经过一些预处理。我们要将字符串分解为词和标点符号,正如我们在第 1 章中所看到的。这一步被称为分词, 它产生我们所熟悉的结构,一个词汇和标点符号的链表。
2处理的 HTML
好像很多公测语料都是html或者xml发布的,这个应该可以处理类似的数据。但书里说其中仍然含有不需要的内容,包括网站导航及有关报道等,通过一些尝试和出错你可以找到内容索引的开始和结尾,并选择你感兴趣的标识符,按照前面讲的那样初始化一个文本。
这里面的“尝试和出错”有点不合适吧。难道不能按标签去找吗,写一个网页模版然后去抽取某基础标签的内容,之前都是这么干的。

3处理搜索引擎的结果
网络可以被看作未经标注的巨大的语料库。网络搜索引擎提供了一个有效的手段,搜索大量文本作为有关的语言学的例子。搜索引擎的主要优势是规模:因为你正在寻找这样庞大的一个文件集,会更容易找到你感兴趣语言模式。而且,你可以使用非常具体的模式,仅在较小的范围匹配一两个例子,但在网络上可能匹配成千上万的例子。网络搜索引擎的第个优势是非常容易使用。因此, 它是一个非常方便的工具, 可以快速检查一个理论是否合理。
不幸的是,搜索引擎有一些显著的缺点。首先,允许的搜索方式的范围受到严格限制。不同于本地驱动器中的语料库,你可以编写程序来搜索任意复杂的模式,搜索引擎一般只允许你搜索单个词或词串,有时也允许使用通配符。其次,搜索引擎给出的结果不一致,并且在不同的时间或在不同的地理区域会给出非常不同的结果。当内容在多个站点重复时,搜索结果会增加。最后, 搜索引擎返回的结果中的标记可能会不可预料的改变, 基于模式方法定位特定的内容将无法使用(通过使用搜索引擎 APIs 可以改善这个问题)。
4 处理处理 RSS 订阅
我觉得这个部分可以使用爬虫和html处理来解决,更加方便。
5 读取本地文件
只需要注意一点,使用”\\”就没问题的。path2='D:\\PythonSource\\fileTest.txt'

6从 PDF、MS Word 及其他二进制格式中提取文本
ASCII 码文本和 HTML 文本是人可读的格式。文字常常以二进制格式出现,如 PDF 和MSWord,只能使用专门的软件打开。第三方函数库如 pypdf 和 pywin32 提供了对这些格式的访问。从多列文档中提取文本是特别具有挑战性的。一次性转换几个文件,会比较简单些, 用一个合适的应用程序打开文件, 以文本格式保存到本地驱动器, 然后以如下所述的方式访问它。如果该文档已经在网络上,你可以在 Google 的搜索框输入它的 URL。搜索结果通常包括这个文档的 HTML 版本的链接,你可以将它保存为文本。
7捕获用户输入
Python2.X的版本是s =raw_input("Enter some text: "),到了3.X好像是用input代替了raw_input,更加好记了。
8 NLP 的流程
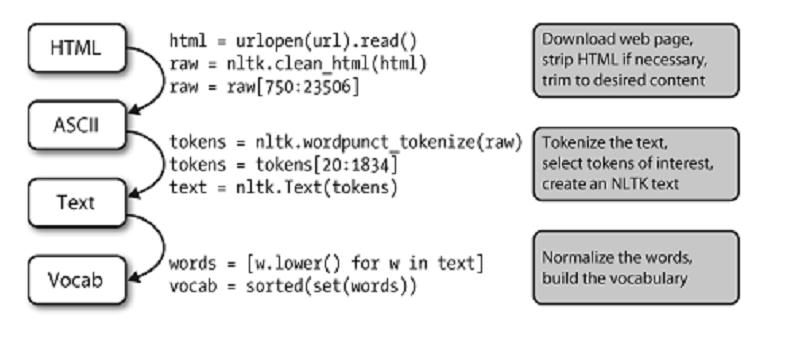
这个图表示的很清楚,我觉得预处理的任务就是将非结构化的数据尽量结构化,以便进一步处理。
#!/usr/python/bin
#Filename:NltkTest8 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









