






刚写了一篇点完发表居然没了,真是欲哭无泪了,只能重新写一遍,但愿不会又没了。
这里是一些斯坦福自然语言处理课程的笔记,主要还是用英文记,搞不清楚的概念或者个人的理解用中文标,毕竟翻译一遍挺没意思的。
课程地址https://class.coursera.org/nlp/lecture。
Course Introduction
Purpose of NLP
- Question Answering
- Information Extration - 从一段话中找到时间、地点等特定信息
- Sentiment Analysis - 对文章的主题进行分类,情感正面负面分类
- Machine Translation
Making Good Progress
- Sentiment Analysis
- Coreference Resolution - 指代关系
- Word Sense Disambiguation
- Parsing - 语法解析
- Machine Translation
- Information Extraction
Still Hard Part
- Question Answering
- Paraphrase - 句子的重写,需要对句子结构的分析
- Summarization
- Dialog
Why NLP Is Hard?
- Ambiguity - 同样一句话,从不同的地方断句,可以有不同的解释
- Non-standard English - “R U OK?”
- Segmentation Issues - 几个名词放在一起,哪几个是一组的?
- Idioms - 成语,习语
- Neologisms - 方言
- World Knowledge - 人知道,但机器不知道的常识
- Tricky Entity Names - 电影名
Tool
- Knowledge about language
- Knowledge about world A way to combine
- knowledge Sources
How
- Probabilistics models built from language data
Basic Text Process
Regular Expressions
i.e. Woodchuck, woodchuck, Woodchucks, woodchuck - 同样的意思,不同的表达
sample website: regexpal.com
| Symbol | Explaination |
|---|---|
| [Ww] | ether one is legal - [A-Za-z], [0-9] |
| [^Ss] | none of the char is legal - [^A-Z] not an upper case letter |
| | | [abc] = a|b|c |
| ? | previous char is optional |
| * | 0 or more of previous char |
| + | 1 or more of previous char |
| . | any char |
| ^ | [A-Z] the char is a upper case letter, and it is at the beginning of the line |
| .$ | “.” is at the end of the line |
| .$ | any char at the end of line |
Errors
- False positives (Type I) - 不该标的标出来了
- False negatives (Type II) - 该找的没标出来
- Increasing accuracy or precision - minimizing false positives
- Increasing coverage or recall - minimizing false negatives
Word Tokenization- How many word in a sentence?
Lemma: same stem part of speech, rough word sense相同或类似的意思的词可以认为是一个词
Wordform: the full inflected surface form
- cat <> cats –> same lemma, different wordforms
Type V(Vocabulary): an element of vocabulary同一个词,同一个lemma都可以作为一个type,两个相连的词也是一个type
Token N: an instance of that type in running text两个相连的词可以认为是一个token
- 1 million types in English
Word Segmentation Algorithm
1. Start a pointer at the beginning of the string
2. Find the logest word in dictionary that matches the string starting at the pointer
3. Move the pointer over the word in string
4. go to 2
i.e. thetabledowmthere -> theta|bled|own|there
English has long words and short words, so the algorithm is not suitable, but Chinese does not
Normalization and Stemming
Lemmatization
- am are is -> be
- car cars car’s -> car
- have to find corrent dicrtionary head word form
Morphology
- Morphemes: the small meaningful units that make up words
- Stems: the core meaning-bearing units
- Affixes: Bits and pieces that adhere to stems - often with grammatical functions
i.e: Stems: Stem是stem,s是affixes。 Bits: Bit是stem,s是affixes
Stemming:找词根
Porter’s Algorithm for English Stemmer
Step 1a
- sses -> ss
- ies -> i
- ss -> s
- s -> nothing
Setp 1b
- (v)ing -> nothing i.e. walking - walk sing - sing在ing前的词里含有至少一个元音
- (v)ed -> nothing
Step 2
- ational -> ate
- izer -> ize
- ator -> ate
Step3
- al -> nothing
- able -> nothing
- ate -> nothing
Sentence Segmentation
Decision Tree of determining if a word is EOS
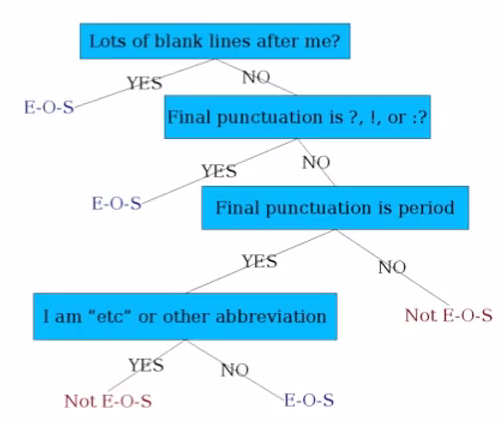
Setting up the structure is often too hard to do by hand. Use Machine Learning to set up. LR, SVM, Neural Nets, etc.
Numeric Features
-Length of word with “.”
-Probablity(word with “.” occurs at end of sentence
-Probabliey(word after “.” occurs at beginning of sentence














 1748
1748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









