







一、索引的基本使用
1、建立索引
数据库会按照索引对数据进行一个排序,存储在一个地方,查询时先到这个地方进行定位,然后再去取真实数据。而MongoDB对不会采用任何索引的查询都会进行“全表扫描”,即查询整个集合。
在shell中为某个key建立索引的方法为调用集合的ensureIndex函数来构建索引,即索引是建立在集合之上的:db.集合名.ensureIndex({key:1}),其中的key表示为哪个key建立索引,1(大于0)表示升序建立索引数据,而-1(小于0)表示降序建立索引数据,如下图:为age这个键升序建立索引。

还可以通过点表示法为内嵌文档建立索引,如下图:

2、在shell中查看数据库已建立的索引
索引的描述信息存储在集合system.indexes中,这是系统提供的保留集合(创建数据库时),不能对其进行插入或删除操作。操作这个集合只能通过ensureIndex插入索引,dropIndex删除索引两个函数。
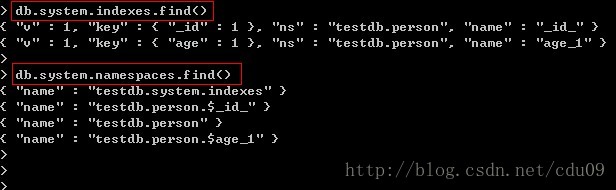
在system.indexes和system.namespaces集合中都能看到数据库已建立的索引,如下图:之前有说过,当插入一条文档到集合中时,如果该文档没有“_id”键时,系统会默认为文档加上该键,而从下图结果中可以发现,系统还会默认为“_id”键建立唯一索引。其中键“ns”是“数据库名.集合名”
3、索引名称
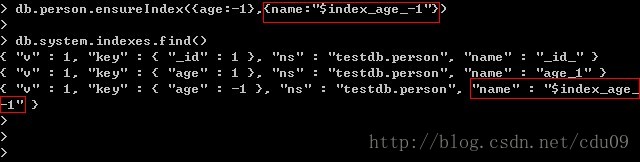
集合中每个索引都会有一个字符串名字,来唯一标识这个索引,且MongoDB通过这个名称来操作索引。默认索引的名称规则为:keyname1_dir1_keyname2_dir2.....,keyname是构建索引的键名称,dir是代表其方向的数字。如创建索引{"a":1,"b":1},其的默认名称是"a_1_b_1"。也可以在建立索引时指定索引的名称,使用方式是使用ensureIndex函数的第二个参数指定name键,如下图:为age键建立倒序索引,并指定名称为“$index_age_-1”。
4、唯一索引
建立唯一索引是使用ensureIndex函数的第二个参数,指定unique键为true,如下图:为name键建立升序的唯一索引,并指定索引名字。
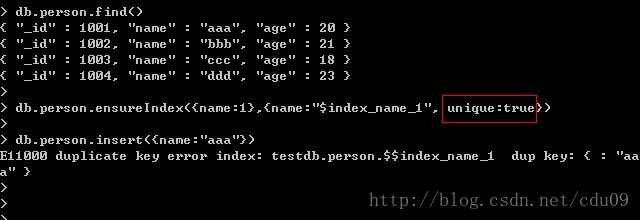
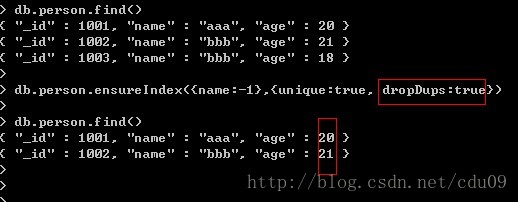
这样建立唯一索引后,当再次插入一条文档,而该文档的name键的值已存在了就不能插入该文档了。但是如果在为某个key建立唯一索引之前,该集合的所有文档中这个key的值已经存在重复的情况了,如果是在这种情况下为该key建立唯一索引,则要使用ensureIndex函数的第二个参数,指定dropDups键为true,如下图:指定了dropDups键为true后,它会删除在这个要建立索引的key上重复的数据,保留这个键第一次出现某个值的文档,再次出现这个值的文档会直接被删掉
注意:
- 如果一个文档中没有唯一性索引对应的键,则这个文档默认该键的值为null,如果插入多条这种文档,后面的文档因为值同为null,会因为违反了唯一性约束而插入失败。
-
如果创建的是复合唯一索引,则要求复合索引所有键的值不能同时重复,单个键可以重复。
5、hint:在查询时强制使用指定的索引(前提是指定使用的索引必须是已经成功创建了的)
hint函数可以作为操作游标的函数调用,它会继续返回一个游标,一般情况下没有必要通过hint去强制使用某个索引,MongoDB的查询优化器能帮助使用最佳的索引去进行查询。如下图:

二、地理空间索引(2D索引)
MongoDB为坐标平面查询提供了专门的索引,即称作地理空间索引。建立地理空间索引的键的值必须是一对值:一个包含两个数值的数组或包含两个键的内嵌文档(内嵌文档的键的名称无所谓),如:{"gis":[10,10]},{"gis":{“x”:10,“y”:10}}。地理空间索引的值固定为"2d"(不再是1或-1)。
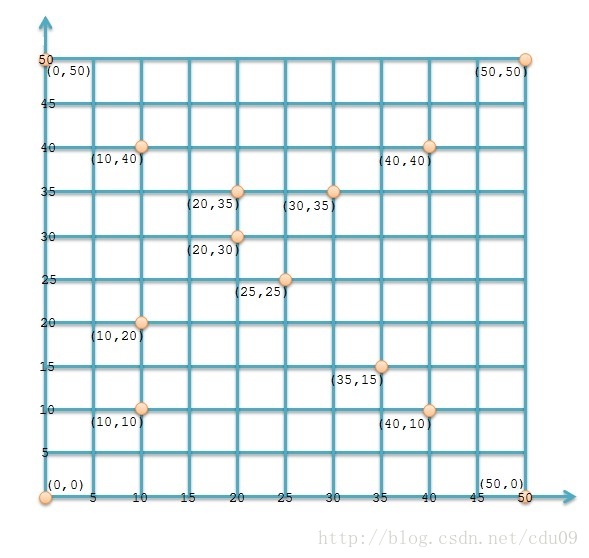
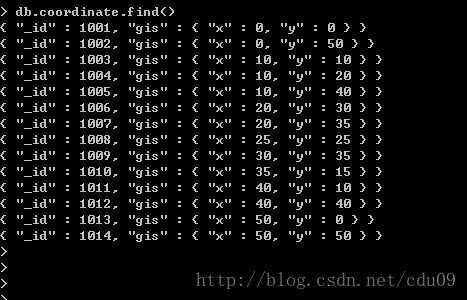
1、有如下一个坐标系,其中有14个点,将每一个点(x,y)存入MongoDB数据库中成为一个文档。
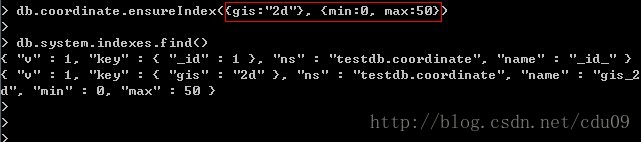
2、为以上建立的coordinate集合中的gis键建立空间索引,如下图:如果不写第二个参数,则默认会建立一个[-180, 180]之间的空间索引。
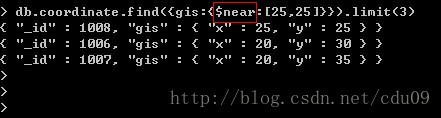
3、在以上的基础上,查询离点(25,25)最近的三个点(包含本身),如下图:如果没有在游标上使用limit函数,默认会返回100条文档
还可以使用数据库命令完成上述查询,如下图:其中键"geoNear"指明查询的集合,键"near"指明查询的基准坐标值,键"num"指定返回的结果数量。该命令同时还会返回每个返回文档距查询点的距离(dis),这个距离的数据单位就是用户自己设定的数据的单位
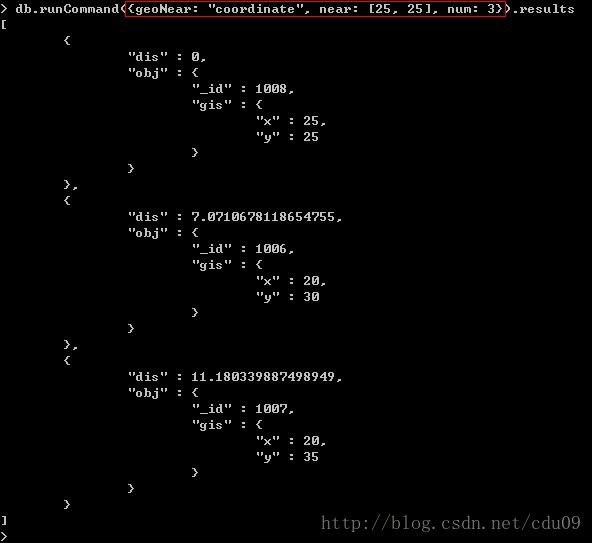
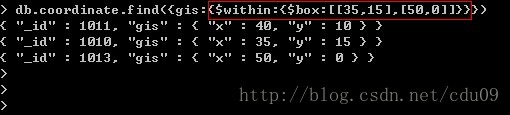
4、查询以点(35,15)和点(50,0)为对角线(左下角和右上角坐标)的矩形中所有的点,如下图:
5、查询以点(40,10)为圆心,半径为10的圆中的点,如下图:

6、地理空间索引也可以与其他普通索引一起创建复合地理空间索引,如下图:

三、索引管理
1、删除索引
在删除索引时可以指定要删除的索引的名字而执行精确删除,还可以使用*号来进行批量删除,shell命令为:db.runCommand({dropIndexes:"集合名", index:"索引名或*号"}),如下图:从结果中发现不能删除默认给_id键生成的索引。
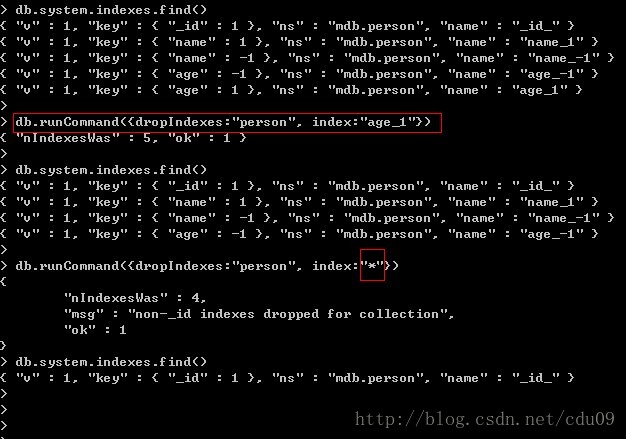
除了这种使用命令的方式外,还可以直接使用在集合上:db.集合名.dropIndexes(),它会直接将该集合所有的索引全部删掉。
还可以使用集合函数:db.集合名.dropIndex("索引名"),它会删除该集合上指定名字的索引,注意使用这个函数的正确步骤应该是先通过查询system.indexes确认索引的名称,然后再删除,因为不是所有语言的数据库驱动都是按照前面介绍的方式去生成索引名称。
除此之外,还有一种删除索引的方式是将集合删掉,这样所有索引(包括键“_id”的唯一索引)、文档都会被删除。而上面介绍的的删除所有索引的方式都不会删除系统为键“_id”创建的唯一索引,且调用集合的remove函数,即使删除所有文档,也不会删除索引,当往集合中添加数据时,该索引还会起作用。
2、索引的构建是一个耗时耗资源的过程,并且在构建过程中会暂时锁表,数据库会阻塞所有的访问请求。为了不影响查询可以让索引的创建过程在后台执行,即指定ensureIndex函数的第二个参数的background键为true即可,表明在数据库服务空闲时来构建索引,如下:对于一个大数量的集合添加索引时应该启用这个参数,且即时启用了这个参数,构建索引仍会影响正常服务,但不会彻底阻塞数据库服务。

四、其他
1、explain函数
它可以作为操作游标的函数调用,游标调用explain函数会返回一个文档,用于描述当前查询的一些细节信息,可以详细查看本次查询使用的索引和状态信息等,它不同于前面说过的其它游标函数都是返回游标,可组成方法链调用,而它是返回一个文档。其他就是类似于关系型数据库中的查询计划,如下图:
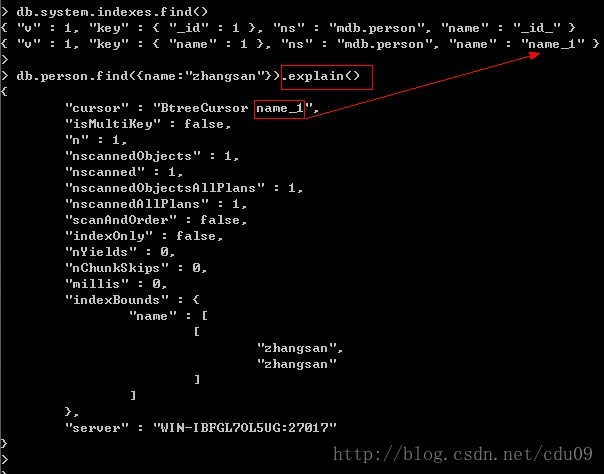
- cursor:因为该查询使用了索引,而MongoDB中索引是存储在B树结构中的,所以这时也使用了BtreeCursor类型的游标。如果没有使用索引,游标的类型会是BasicCursor。然后其中的”name_1“就是使用的索引名称了。
- nscanned/nscannedObjects:表示当次查询一共扫描了集合中多少个文档。
- n:当次查询返回的文档数量。
- millis:当次查询所需时间(毫秒)。
- indexBounds:当次查询具体使用的索引。
如下图所示,集合person上有两个索引{"name":1,"age":1}和{"age":1,"name":1},按照这两个键查询,从explain的返回中可以发现其默认使用了索引"name_1_age_1",并没有按照查询的键的顺序使用索引"age_1_name_1",这就是查询优化器为用户使用的索引。

2、使用索引注意点
- 索引的创建在提高查询性能的同时会降低插入的性能,使用索引后,每次对集合的插入、更新、删除都会因为要更新索引而产生额外的开销,所以对于经常查询而少插入的情况可以考虑使用索引。
- 禁止为每一个键创建索引,这样的集合插入速度会非常慢。MongoDB中规定一个集合最多有64个索引。创建索引使用的键应该有较多的值,过少的值会导致索引不实用,如在一个布尔类型的键(就true、false两种值)上创建索引,按照这个键的查询通常会返回一半以上的数据,使用这种索引反而会降低效率。有个规律,如果查询最后返回的结果的数量>目标集合文档数量的一半,使用索引反而不如“全表扫描”。
- 复合索引应根据实际业务情况注意索引的先后顺序。比如有一个用户集合{"user":值,"state":值,"date":值},每个用户每天都会有几十条状态的更新,建立了这样的一个索引{"user":1,"date":-1}。当这个集合数据量过大时,这个索引作用已经不大了,因为每个用户都会有很多条的陈旧状态信息,这些陈旧的状态信息因为索引首先按用户名排序而排在前面,这会导致查询用户名比较靠后的用户最新状态的索引信息就很耗时,如果将索引改为{"date":-1,"user":1},这样的索引会更适合 “对特定用户最新状态的查询” 这种需求,因为它可以保证索引前面对应的就是常用数据。
- 在做排序时如果是超大数据量也可以考虑加上索引来提高排序的性能。为排序创建索引:当数据量太大时,有时可能单纯是为了查询中排序去做索引,如果在查询中使用没有创建索引的键来排序,MongoDB会将所有的数据取到内存中来排序,因此排序首先限制于内存的大小并且MongoDB本身对无索引排序的数据量也是有要求的,即T级别的数据无法在内存中进行排序,否则MongoDB会报错。因此如果要对超大数据集按某个键排序,就要为这个键构建索引。MongoDB会按照索引顺序提取数据,这样就不会耗尽内存。
- 如果构建含有多个键的索引,不是查询时必须使用构建索引的所有键,这个索引才会生效。但想要这个多键索引生效是有要求的,就是按顺序使用构建索引的一部分键或全部键,索引才会生效。即:假如构建这样一个索引:{"a":1, "b":1, "c":1,"d":1},其时顺带构建了如下3个索引{"a":1},{"a":1, "b":1},{"a":1,"b":1,"c":1}。只要符合这几个索引的查询都会触发这个复合索引。注意,MongoDB的查询优化器会按照索引中键的顺序优化查询。所以对于上述索引,查询条件{"a":值},{"a":值, "b":值},{"a":值,"c":值},{"d":值, "a":值}都会触发索引,但查询条件{"b":值},{"b":值,"c":值}不会使用这个索引。
- MongoDB中,往含有数据的集合上添加索引比向空集合添加索引后插入数据要快一些,这个在进行数据库数据初始化时可以考虑使用。















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









