




 本文详细介绍了如何应用AlphaZero算法于中国象棋,结合论文分析了算法的核心部分,如蒙特卡洛树搜索(MCTS)和神经网络。通过自对弈训练,神经网络不断学习并优化棋局策略。文章还提供了项目实现的代码片段,展示了从输入特征设计到训练网络的全过程。
本文详细介绍了如何应用AlphaZero算法于中国象棋,结合论文分析了算法的核心部分,如蒙特卡洛树搜索(MCTS)和神经网络。通过自对弈训练,神经网络不断学习并优化棋局策略。文章还提供了项目实现的代码片段,展示了从输入特征设计到训练网络的全过程。
原创文章,转载请注明出处: AlphaZero实践——中国象棋(附论文翻译)
请安装TensorFlow1.0,Python3.5,uvloop
项目地址: https://github.com/chengstone/cchess-zero
关于AlphaGo和后续的版本AlphaGo Zero等新闻大家都耳熟能详了,今天我们从论文的分析,并结合代码来一起讨论下AlphaZero在中国象棋上的实践。
实际上在GitHub上能够看到有很多关于AlphaGo的实践项目,包括国际象棋、围棋、五子棋、黑白棋等等,我有个好友在实践麻将。
从算法上来说,大家都是基于AlphaGo Zero / AlphaZero的论文来实现的,差别在于不同Game的规则和使用了不同的trick。
论文分析
我们要参考的就是AlphaGo Zero的论文《Mastering the Game of Go without Human Knowledge》和AlphaZero的论文《Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm》。
小弟不才,献丑翻译了这两篇论文,时间仓促,水平有限✧(≖ ◡ ≖✿),您要是看不惯英文,希望这两篇翻译能提供些许帮助。
《Mastering the Game of Go without Human Knowledge》
《Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm》
建议在本地用jupyter notebook打开看,我发现从GitHub上看的话,有些公式没有显示出来,另外图片也没有显示出来。
Mastering the Game of Go without Human Knowledge
先从《Mastering the Game of Go without Human Knowledge》说起,算法根据这篇论文来实现,AlphaZero只有几点不同而已。
总的来说,AlphaGo Zero分为两个部分,一部分是MCTS(蒙特卡洛树搜索),一部分是神经网络。
我们是要抛弃人类棋谱的,学会如何下棋完全是通过自对弈来完成。
过程是这样,首先生成棋谱,然后将棋谱作为输入训练神经网络,训练好的神经网络用来预测落子和胜率。如下图:
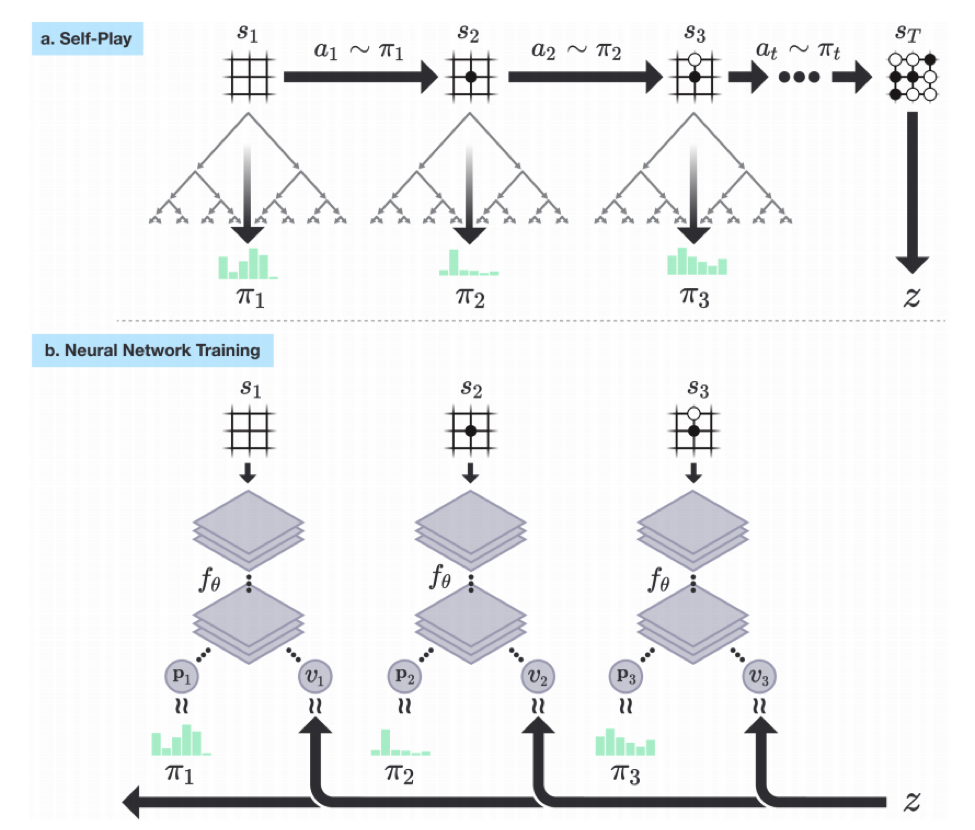
蒙特卡洛树搜索算法
MCTS就是用来自对弈生成棋谱的,结合论文中的图示进行说明:
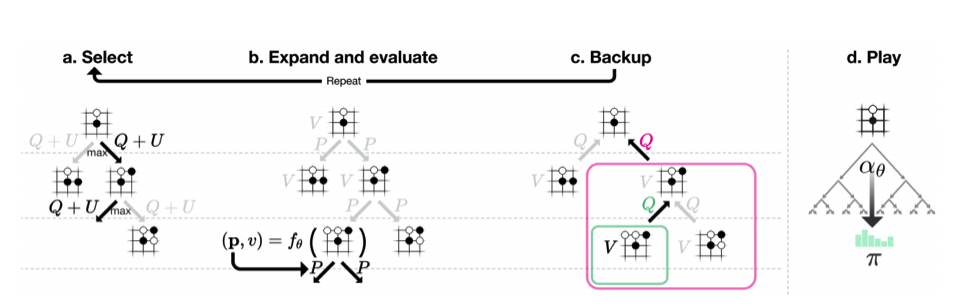
论文中的描述:
AlphaGo Zero中的蒙特卡洛树搜索。
- a.每次模拟通过选择具有最大行动价值Q的边加上取决于所存储的先验概率P和该边的访问计数N(每次访问都被增加一次)的上限置信区间U来遍历树。
- b.展开叶子节点,通过神经网络(P(s, ·), V (s)) = f_θ(s)来评估局面s;向量P的值存储在叶子结点扩展的边上。
- c.更新行动价值Q等于在该行动下的子树中的所有评估值V的均值。
- d.一旦MCTS搜索完成,返回局面s下的落子概率π,与N^(1 /τ)成正比,其中N是从根状态每次移动的访问计数, τ是控制温度的参数。
按照论文所述,每次MCTS使用1600次模拟。过程是这样的,现在AI从白板一块开始自己跟自己下棋,只知道规则,不知道套路,那只好乱下。每下一步棋,都要通过MCTS模拟1600次上图中的a~c,从而得出我这次要怎么走子。
来说说a~c,MCTS本质上是我们来维护一棵树,这棵树的每个节点保存了每一个局面(situation)该如何走子(action)的信息。这些信息是,N(s, a)是访问次数,W(s, a)是总行动价值,Q(s, a)是平均行动价值,P(s, a)是被选择的概率。
a. Select
每次模拟的过程都一样,从父节点的局面开始,选择一个走子。比如开局的时候,所有合法的走子都是可能的选择,那么我该选哪个走子呢?这就是select要做的事情。MCTS选择Q(s, a) + U(s, a)最大的那个action。Q的公式一会在Backup中描述。U的公式如下:
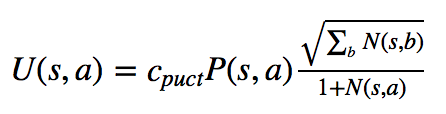
这个可以理解成:U(s, a) = c_puct × 概率P(s, a) × np.sqrt(父节点访问次数N) / ( 1 + 某子节点action的访问次数N(s, a) )
用论文中的话说,c_puct是一个决定探索水平的常数;这种搜索控制策略最初倾向于具有高先验概率和低访问次数的行为,但是渐近地倾向于具有高行动价值的行为。
计算过后,我就知道当前局面下,哪个action的Q+U值最大,那这个action走子之后的局面就是第二次模拟的当前局面。比如开局,Q+U最大的是当头炮,然后我就Select当头炮这个action,再下一次Select就从当头炮的这个棋局选择下一个走子。
b. Expand
现在开始第二次模拟了,假如之前的action是当头炮,我们要接着这个局面选择action,但是这个局面是个叶子节点。就是说当头炮之后可以选择哪些action不知道,这样就需要expand了,通过expand得到一系列可能的action节点。这样实际上就是在扩展这棵树,从只有根节点开始,一点一点的扩展。
Expand and evaluate这个部分有个需要关注的地方。论文中说:在队列中的局面由神经网络使用最小批量mini-batch 大小为8进行评估;搜索线程被锁定,直到评估完成。叶子节点被展开,每个边(s_L, a)被初始化为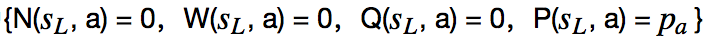
如果我当前的局面没有被expand过,不知道下一步该怎么下,所以要expand,这个时候要用我们的神经网络出马。把当前的局面作为输入传给神经网络,神经网络会返回给我们一个action向量p和当前胜率v。其中action向量是当前局面每个合法action的走子概率。当然,因为神经网络还没有训练好,输出作为参考添加到我们的蒙特卡洛树上。这样在当前局面下,所有可走的action以及对应的概率p就都有了,每个新增的action节点都按照论文中说的对若干信息赋值,
c. Backup
接下来就是重点,evaluate和Backup一起说,先看看Backup做什么事吧:边的统计数据在每一步t≤L中反向更新。访问计数递增,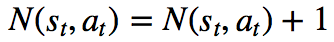
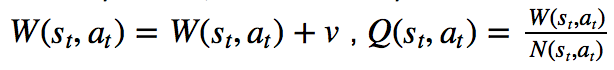
我们来整理一下思路,任意一个局面(就是节点),要么被展开过(expand),要么没有展开过(就是叶子节点)。展开过的节点可以使用Select选择动作进入下一个局面,下一个局面仍然是这个过程,如果展开过还是可以通过Select进入下下个局面,这个过程一直持续下去直到这盘棋分出胜平负了,或者遇到某个局面没有被展开过为止。
如果没有展开过,那么执行expand操作,通过神经网络得到每个动作的概率和胜率v,把这些动作添加到树上,最后把胜率v回传(backed up)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1356
1356











 到【灌水乐园】发言
到【灌水乐园】发言







