









之前训练faster的时候一直没有办法进行多GPU训练,以为是自己的错,今天看了/include/caffe/layers/python_layer.h发现原来这是caffe的缘故。
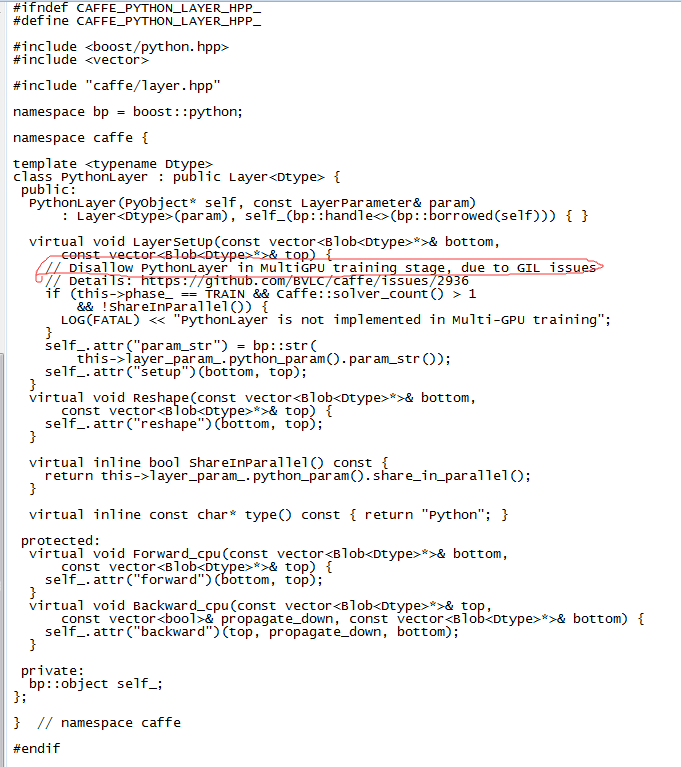
原来caffe在写的时候就不允许python使用多GPU训练。
深入分析:
其是主要的是python的缘故。
这里提到一个GIL。这里的GIL是 Python 的Global Interpreter Lock (全局解释器锁) 一次只允许一个thread在python解释器中运行。
什么是全局解释器锁呢?
Python代码的执行由Python虚拟机(也叫解释器主循环)来控制。Python在设计之初就考虑到要在主循环中,同时至于一个线程在执行,就像但CPU的系统中运行多个进程那样,内存中可以存放多个程序,但在任意时刻,只有一个程序在CPU中运行。同样地,虽然Python解释器可以“运行”多个线程,但在任意时刻,只有一个线程在解释器中运行。
对Python虚拟机的访问由全局解释器锁(global interpreter lock GIL)来控制,正是这个锁能保证同一时刻只有一个线程在运行。在多线程环境中,Python虚拟机按以下方式执行。
- 设置GIL
- 切换到一个线程运行。
运行:
a. 指定数量的字节码的指令,或者
b. 线程主动让出控制(可以调用time.sleep(0))把线程设置为睡眠状态。
- 解锁GIL。
- 再次重复以上所有步骤。
在调用外部代码(如C/C++扩展函数)的时候,GIL将会被锁定,知道这个函数结束为止(由于在这期间没有Python的字节码被运行,所以不会有线程切换)。编写拓展的程序员可以主动解锁GIL。不过,Python的开发人员则不用担心在这些情况下你的Python代码会被锁住【1】。
那解决办法是什么呢?就这样认命么?NO!
高手总是有的。
方案1:https://github.com/BVLC/caffe/issues/2936
提供者:naibaf7 Berkeley Vision and Learning Center member
release the GIL for the forward/backward passes in the OpenCL branch。
方案2:https://github.com/BVLC/caffe/pull/4360
提供者:alessandroferrari
Added ScopedGILRelease for easy GIL release. Modified _caffe.cpp in pycaffe accordingly.
参考文献:
【1】Python核心编程(第二版)















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









