







导语
前面讲了一些机器学习相关概念的理解方式,而现在只要提到机器学习,则不得不提深度学习。在硬件计算能力日益发达的今天,深度学习作为机器学习的一个重要分支,日益受到重视,变得广为人知。那么深度学习到底是什么?本文将通过一篇英文讲稿,给大家揭开她的神秘面纱,为之后讲CNN作铺垫。
DL简介
OK Let’s begin. I’m very pleased to have this opportunity to make a brief introduction of Deep learning, and I’m sure everybody is interested in this topic, so first of all, I’d like to share with you two examples. The first one is about Google Brain Project in June last year.

This project was led by Stanford University computer scientist Andrew Ng(吴恩达) and the Google fellow Jeff Dean. Having used sixteen thousand computer processors to create a “neural network” with more than one billion connections, the “Google brain” behaved in a manner that mirrored the habits of many human Internet users: it became obsessed with pictures of cats, means that it has taught itself how to recognize cats. And…the second one I found a video to share, it’s about Microsoft’s voice recognition, an activity in November last year. Isn’t it amazing? So, as a result, which is the key technology supported behind these? Right, that is Deep Learning.
Firstly, I summarized two aspects as its background. On the one hand, there are many unsolved problems about Machine Learning. On the other hand, the feature expression by hand could be a low-efficiency task. Well, let’s see this flow chart.

We get data with sensors by this phase, through data pre-processing, feature extraction, and feature selection, we may get to the last phase, model inference, most of the machine learning work is done in this phase. But in the middle three parts, the feature expression, we always rely on experience even luck by hand with a huge workload.
Next, I’d like to present some basic concepts of DL. Deep Learning has another name, unsupervised feature learning, just as its name implies, feature extraction will processed with no human help. And it consists of multilayer perceptron contrasted to the shallow learning since the 1980s and the training method compared with the traditional network. (I may remind you that this perceptron is not the same as the sensor I just mentioned)
Ok, the major question is, how to train? In other word, how to proceed the so-called “deep learning”? before that, I want to talk about baby learning in the first place, because these two are very similar with each other.
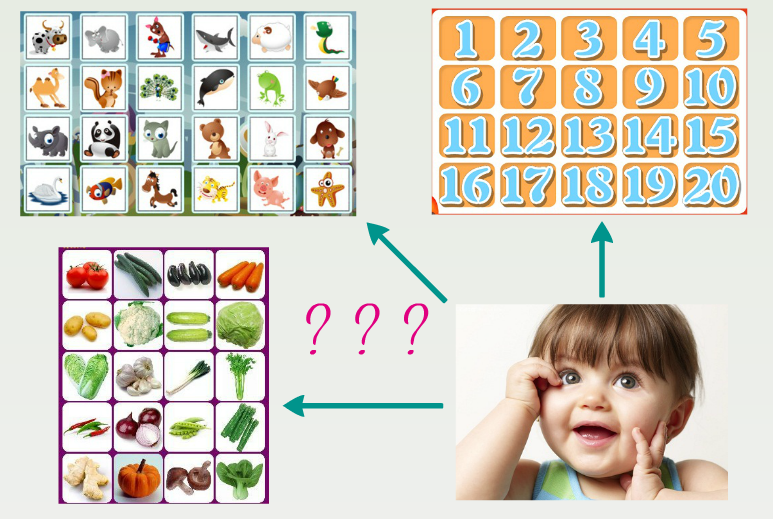
Look at this picture, there are three tables and a cute baby. How does the baby learn from these stuff tables? Imagining that during this baby’s life, see animals like cattle, elephant, shark, sheep, snake, cat and dog, see vegetable like tomato, cucumber, carrot, cabbage, pumpkin, mushroom, and green pepper, and see Arabic numbers like one, two, three, four, five, and so on. Actually, in most cases, it doesn’t know “dog” should be called dog, “pumpkin” should be called pumpkin and “one” should be called one. It only knows…sort of the difference between the things which belongs to the same categories. Let me give you a specific example, this “thing”, you may have seen it in countryside or from TV series in the first time and then you may see it again in many places, finally you have learned that this “thing” looks a little bit cute with white fur, and has big round noses and you can tell it from the other species or categories but, you don’t know how to call it. By now, you hear a word “pig” from TV, book, newspaper, magazine or the other people whatever, refer to this thing so you know the correct definition of it. After that, when you see it again, you may say, “I know it, that is pig!” Similarly, the general procedure of deep learning is just like this, let me show you next.
There are two phases. First one is the bottom-up unsupervised learning using no label data and training layer by layer, this phase seems like baby surrounding recognition. Second phase is top-down supervised learning using labeled data and further fine-tuning each layer’s parameters, this may seem like you know the definitely word “pig” rather than “cat” to define.

This is the real training result from feature learning. Firstly bottom-up and secondly top-down.
There are four popular models and methods to train the deep neural network, AutoEncoder, Sparse Coding, Restricted Boltzmann Machine and Convolutional Neural Networks. If you are interested in these methods, you may google them and learn yourselves.
Finally I want to talk about the future problem. Impact by big data, from Google’s speech-recognition experiment, scientists found that DNN has the same forecast error in training samples and test samples. And there is a long way to go with these significant issues. As to human and social problems, I guess all of you should have seen the movie I, Robot and The Matrix. We couldn’t image what human life will be if deep learning makes the AI truly come true.
Thank you!
结语
这是我研一讨论班的演讲稿,由于时间原因没能做成中文版,希望蜻蜓点水式的介绍能对理解深度学习有所帮助。在此感谢各位的耐心阅读,不足之处希望多多指教。后续内容将会不定期奉上,欢迎大家关注小斗公众号 对半独白!
















 5858
5858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









