







梯度下降算法
梯度方向: 指定点处, 函数值变化幅度最大的方向.
梯度下降算法, Gradient Descent, 也称为 最速下降算法, Steepest Descent. 是求解无约束最优化问题的经典方法.
它属于迭代优化方法. 迭代公式是:
x
(
k
+
1
)
=
x
(
k
)
+
(
−
1
)
λ
k
∇
f
(
x
(
k
)
)
x^{(k+1)}=x^{(k)}+ (-1)\lambda_k \nabla f(x^{(k)})
x(k+1)=x(k)+(−1)λk∇f(x(k))
即从
x
(
k
)
x^{(k)}
x(k)点出发, 沿该点处的负梯度方向
−
∇
f
(
x
(
k
)
)
-\nabla f(x^{(k)})
−∇f(x(k)), 以步长
λ
k
\lambda_k
λk 找到下一个迭代点.
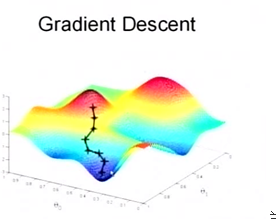
- 局部最优与全局最优
梯度下降不一定能够找到全局的最优解,有可能是一个局部最优解。可以取不同的初始迭代点, 分别求解, 增加找到全局最优的几率.
当然,如果损失函数是凸函数,梯度下降法得到的解就一定是全局最优解。
参数
- 步长的选择
步长过大, 容易震荡; 而步长过小, 收敛速度又会很慢.
随机梯度下降
SGD, Stochastic Gradient Descent.
一般来讲, 目标函数是每个样本损失函数的加和. 即
L
(
w
)
=
∑
i
=
1
n
L
i
(
w
)
L(w)=\sum_{i=1}^n L_i(w)
L(w)=i=1∑nLi(w)
当样本很多, 参数很多, 又没有简单的公式时, 计算的代价会很昂贵.
所以随机梯度下降的思想是: 在计算每轮迭代时, 从总样本中随机选一个子集来计算. 大大减轻运算量. It’s effective in large-scale machine learning problems.
虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的, 最终的结果往往是在全局最优解附近.
- 应用
用处很广, 支持向量机,逻辑回归和图形模型. 当与反向传播算法相结合时,它是用于训练人造神经网络的实际标准算法.
momentum
momentum, [mə’mentəm], [物] 动量.
P
=
m
v
P=mv
P=mv.
在sgd的过程中,每次下降步长仅通过α(alpha)来控制,容易陷入更新太慢的状态:
- 平坦地区,下降好多步,也走不到头;
- 陡峭的区域,下降过头,导致,左一步,右一步,收敛也慢
看一下小球滚落的物理现象:
如果是个笔直的斜坡, 由于加速度方向一致, 小球的动量会快速变大; 若轨道比较蜿蜒, 小球甚至还会减速.
于是参照小球滚落的物理现象, 引入了 mementum 参数.
思想是,若当前梯度方向与上一次相同,那么,此次的步长增强,否则,应该相应减弱.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zcfMJZOa-1610894718739)(http://image100.360doc.com/DownloadImg/2016/10/1008/81923986_10.jpg)]
Nesterov momentum
Nesterov Accelerated Gradient(NAG)算法相对于Momentum的改进在于,以“向前看”看到的梯度 而不是 当前位置梯度去更新。经过变换之后的等效形式中,NAG算法相对于Momentum多了一个本次梯度相对上次梯度的变化量,这个变化量本质上是对目标函数二阶导的近似。由于利用了二阶导的信息,NAG算法才会比Momentum具有更快的收敛速度。
参数
下面的参数来自于kerkas中的 keras.optimizers.SGD.
- lr: float >= 0. Learning rate.
- momentum: float >= 0. Parameter updates momentum.
- decay: float >= 0. Learning rate decay over each update.
- nesterov: boolean. Whether to apply Nesterov momentum.
例题
- 用最速下降法求解
min f ( x ) = 2 x 1 2 + x 2 2 \min f(x)=2x_1^2+x_2^2 minf(x)=2x12+x22
引自: <<最优化理论与算法>> P.283 - 假设我们想用直线
y
=
w
1
+
w
2
x
y=w_1+w_2x
y=w1+w2x 去拟合一系列二维的点, n为样本个数, 损失函数为平方差, 那么请列出参数的更新方程.
答: 总的损失函数就是
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fYPb4gRL-1610894718741)(https://wikimedia.org/api/rest_v1/media/math/render/svg/b3b8bbcea44ef6bb1c2e7b281fae5c4495186e44)]
参数更新递推公式为:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EnlIr6Ui-1610894718743)(https://wikimedia.org/api/rest_v1/media/math/render/svg/1287a455b42c47dadf958a42cc4164c38abfbfd0)]
lala

参数w的更新迭代为:
w
=
w
+
(
−
1
)
∗
λ
∗
∂
L
∂
w
w = w+(-1)* \lambda *\frac {\partial L}{\partial w}
w=w+(−1)∗λ∗∂w∂L
略去学习率与负号,
Δ
w
3
=
∂
L
∂
w
3
=
h
3
(1)
\Delta w3=\frac {\partial L}{\partial w3}=h3 \tag 1
Δw3=∂w3∂L=h3(1)
继续往前, 就要用到复合函数求导的链式法则了. 以激活函数为 sigmoid,
σ
(
⋅
)
\sigma(\cdot)
σ(⋅) 为例:
Δ
w
2
=
∂
L
∂
w
2
=
∂
L
∂
h
3
⋅
∂
h
3
∂
w
2
=
w
3
⋅
∂
h
3
∂
w
2
(2)
\begin{aligned} \Delta w2 &=\frac {\partial L}{\partial w2} \\ &=\frac {\partial L}{\partial h3}\cdot \frac {\partial h3}{\partial w2} \\ &= w3 \cdot \frac {\partial h3}{\partial w2} \tag 2 \end{aligned}
Δw2=∂w2∂L=∂h3∂L⋅∂w2∂h3=w3⋅∂w2∂h3(2)
对其中的复合函数
h
3
=
σ
(
w
2
h
2
+
b
2
)
h3=\sigma(w2h2+b2)
h3=σ(w2h2+b2) 再度应用链式法则:
Δ
w
2
=
w
3
⋅
∂
[
σ
(
h
2
w
2
+
b
2
)
]
∂
w
2
=
w
3
⋅
∂
[
σ
(
h
2
w
2
+
b
2
)
]
∂
(
h
2
w
2
+
b
2
)
⋅
∂
(
h
2
w
2
+
b
2
)
∂
w
2
=
w
3
⋅
σ
(
h
2
w
2
+
b
2
)
(
1
−
σ
(
h
2
w
2
+
b
2
)
)
⋅
h
2
(2.1)
\begin{aligned} \Delta w2 &= w3 \cdot \frac {\partial [\sigma( h2w2+b2)]}{\partial w2} \\ &= w3 \cdot \frac {\partial [\sigma( h2w2+b2)]}{\partial (h2w2+b2)} \cdot \frac {\partial ( h2w2+b2)}{\partial w2} \\ &= w3\cdot \sigma( h2w2+b2)(1-\sigma( h2w2+b2)) \cdot h2 \tag {2.1} \end{aligned}
Δw2=w3⋅∂w2∂[σ(h2w2+b2)]=w3⋅∂(h2w2+b2)∂[σ(h2w2+b2)]⋅∂w2∂(h2w2+b2)=w3⋅σ(h2w2+b2)(1−σ(h2w2+b2))⋅h2(2.1)
可以看到, 值的大小由 {高层权重, 前一层输出, 激活函数选择} 共同决定.
所以, 对一个 variable 打印梯度, 在不同的 step, 其梯度也会有较大变化.
再继续往前,
Δ
w
2
=
∂
L
∂
w
1
=
∂
L
∂
h
3
⋅
∂
h
3
∂
w
1
=
∂
L
∂
h
3
⋅
∂
h
3
∂
h
2
⋅
∂
h
2
∂
w
1
(3)
\begin{aligned} \Delta w2 &=\frac {\partial L}{\partial w1} \\ &=\frac {\partial L}{\partial h3}\cdot \frac {\partial h3}{\partial w1} \\ &=\frac {\partial L}{\partial h3}\cdot \frac {\partial h3}{\partial h2} \cdot \frac {\partial h2}{\partial w1} \tag 3 \end{aligned}
Δw2=∂w1∂L=∂h3∂L⋅∂w1∂h3=∂h3∂L⋅∂h2∂h3⋅∂w1∂h2(3)
其中
h
3
=
σ
(
w
2
h
2
+
b
2
)
h3=\sigma(w2h2+b2)
h3=σ(w2h2+b2), 与式(2)中类似, 由对
w
2
w2
w2 求偏导变为 对
h
2
h2
h2求偏导.
激活函数对梯度的影响

图: sigmoid 函数的梯度函数的图像. 其梯度的值域为 [0,0.25] .














 3891
3891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









