







1.简介
word2vec 是google在2013发布的开源工具包, 用于生产分布式词向量. 它简单高效, 特别适合大规模, 超大规模的语料库, 从中获取高精度的词向量表示.
词向量的介绍看 这里 .
Q: 对于形如
v
(
w
)
=
{
0.054
,
−
0.22
,
0.12
,
0.215
,
−
0.17093
,
.
.
.
}
v(w)=\{0.054, -0.22, 0.12, 0.215 , -0.17093, ...\}
v(w)={0.054,−0.22,0.12,0.215,−0.17093,...} 这样的向量, 要怎么用呢?
A: 通过向量间的距离(如 余弦距离) 来刻画不同词汇之间的相似度. 这里的相似度并不是同义词, 近义词等, 而是语料库中跟它具有同样相邻词的词.
基于词向量的LSTM架构, 在中文分词, 词性标注, 语义组块, 命名实体识别 等方面取得了良好的效果. 在精度上均与 概率图 模型不相上下, 而产生的模型要小得多.
2.算法原理
word2vec用的是神经网络模型,分为两种
- CBOW, Continuous Bag of Words
- skip-gram
每个模型的训练方法又分别有两种
- Hierarchical Softmax
该网络解决的是一个多分类问题, 典型的多分类结构是 全连接层跟一个softmax处理. 但这个任务中词典过大, 所以借助huffman树进行不断的二分类, 这就叫 Hierarchical Softmax. - Negative Sampling
所以搭配起来,
C
2
1
∗
C
2
1
=
4
C_2^1*C_2^1=4
C21∗C21=4 , 就有4种具体实现.
本文讲述CBOW+Hierarchical Softmax 的原理. 通过周围词来预测当前词.
Q: 周围 这个标准, 如何界定?
句号, 叹号 等符号, 不会作为界定符号, 而是把它们也当做一个词送到网络里面去训练. 不同的doc会作为一个天然的分隔符. 即第一篇文档的最后一个词与第二篇文档的第一个词, 不会认为相连.
2.0 小贴士
网络上《word2vec中的数学原理详解》一文流传甚广, 但我觉得它的符号约定不太友好, 比如用
p
w
p^w
pw 来表示路径, 路径上的编码从
d
2
w
d_2^w
d2w 开始. 于是约定了自己认为直观易懂的符号展开讲解.
本文不展开偏导计算部分.
2.1 符号约定
- w
要预测的当前词. -
x
w
x_w
xw
w的分布式向量 -
C
o
n
t
e
x
t
(
w
)
Context(w)
Context(w)
w上下文相关的词, 它之前的c个词 与 它之后的c个词, 共2c个词.
设c=2, C o n t e x t ( w ) = [ w ( t − 2 ) , w ( t − 1 ) , w ( t + 1 ) , w ( t + 2 ) ] Context(w)=[w(t-2), w(t-1),w(t+1), w(t+2)] Context(w)=[w(t−2),w(t−1),w(t+1),w(t+2)] - m
分布式词向量的固定长度 - D
语料库Corpus中所有出现单词组成的词典. - path(w)
huffman树中, 单词w的路径. 如 p a t h ( w ) = ( 1 , 1 , 0 , 0 ) path(w)=(1,1,0,0) path(w)=(1,1,0,0) .
p a t h ( w ) i ∈ ( 0 , 1 ) path(w)_i \in (0,1) path(w)i∈(0,1) 表示路径向量中第i个分量的值. - len(path(w))
huffman树中, 单词w的路径长度. -
θ
(
w
)
i
\theta(w)_i
θ(w)i
huffman树中, 单词w的路径中第i个非叶子节点.
θ ( w ) = ( θ ( w ) 1 , . . . , θ ( w ) l e n ( p a t h ( w ) ) ) \theta(w)=(\theta(w)_1, ... , \theta(w)_{len(path(w))} ) θ(w)=(θ(w)1,...,θ(w)len(path(w)))
其中 θ ( w ) 1 \theta(w)_1 θ(w)1对应的就是根节点.
θ ( w ) i \theta(w)_i θ(w)i也代指该非叶子节点的向量. 它也是m维的.
2.2 网络结构
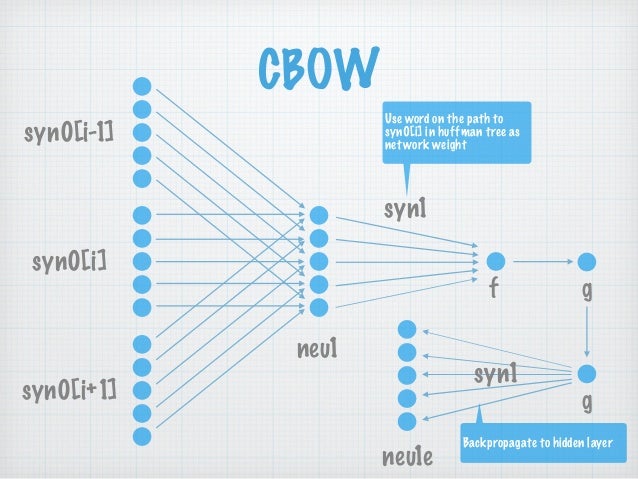
图2-1 CBOW网络结构 syn0[.] 即为 w[.], 表示邻居词汇
每层展开来讲:
ps:自己画图太费时间, 所以下文的符号没有与图2-1 结构对应上, sorry.
-
输入层
C o n t e x t ( w ) = [ w ( t − 2 ) , w ( t − 1 ) , w ( t + 1 ) , w ( t + 2 ) ] Context(w)=[w(t-2), w(t-1),w(t+1), w(t+2)] Context(w)=[w(t−2),w(t−1),w(t+1),w(t+2)].
所以共有2c*m个节点.
一般神经网络的输入都是已知的, 而Word2Vec 网络中的输入, 是通过SoftMax()计算后才得到的. -
投影层
有m个节点. 对输入层各词向量作加和处理. p r o j e c t i o n ( w ) = ∑ C o n t e x t ( w ) projection(w)=\sum Context(w) projection(w)=∑Context(w) -
输出层
输出层是一棵树, 一棵Huffman树! 这是与普通神经网络的显著不同之处. 这棵树的叶子节点数就是词典D的大小 ∣ D ∣ |D| ∣D∣.
Huffman树相关知识可以回顾 树-总述 .
以词频作权重, 我们就构建出了这么一棵Huffman树.

图2-2 网络输出层的示例
以how这个单词来讲, 它的路径就是(1,1,0,0).
2.3 推导计算
每一个单词w, 都对应一个huffman树叶子节点, 因为是二叉的, 所以从根节点走到w的叶子节点的过程, 就是一个在不断地进行二分类的过程.
将左结点1记为负样本, 右节点0记为正样本, 基于逻辑斯蒂函数, 将一个节点被分为正样例的概率定为
σ
(
x
w
T
θ
)
=
1
1
+
e
−
x
w
T
θ
\sigma(x_w^T\theta)=\frac{1}{1+e^{-x_w^T\theta}}
σ(xwTθ)=1+e−xwTθ1
那么就得到了条件概率:
P
(
p
a
t
h
(
w
)
i
∣
C
o
n
t
e
x
t
(
w
)
)
=
{
σ
(
x
w
T
θ
(
w
)
i
)
p
a
t
h
(
w
)
i
=
0
1
−
σ
(
x
w
T
θ
(
w
)
i
)
p
a
t
h
(
w
)
i
=
1
=
[
σ
(
x
w
T
θ
(
w
)
i
)
]
1
−
p
a
t
h
(
w
)
i
⋅
[
1
−
σ
(
x
w
T
θ
(
w
)
i
)
]
p
a
t
h
(
w
)
i
\begin{aligned} P(path(w)_i|Context(w)) & = \begin{cases} \sigma(x_w^T\theta (w)_i) & path(w)_i=0 \\ 1-\sigma(x_w^T\theta (w)_i) & path(w)_i=1 \end{cases} \\ & =[\sigma(x_w^T\theta (w)_i)]^{1-path(w)_i} \cdot [1-\sigma(x_w^T\theta (w)_i)]^{path(w)_i} \end{aligned}
P(path(w)i∣Context(w))={σ(xwTθ(w)i)1−σ(xwTθ(w)i)path(w)i=0path(w)i=1=[σ(xwTθ(w)i)]1−path(w)i⋅[1−σ(xwTθ(w)i)]path(w)i
所以
p
(
w
∣
C
o
n
t
e
x
t
(
w
)
)
=
∏
i
=
1
l
e
n
(
p
a
t
h
(
w
)
)
P
(
p
a
t
h
(
w
)
i
∣
C
o
n
t
e
x
t
(
w
)
)
p(w|Context(w))=\prod_{i=1}^{len(path(w))} P(path(w)_i|Context(w))
p(w∣Context(w))=i=1∏len(path(w))P(path(w)i∣Context(w))
我们取对数似然函数做目标函数:
L
=
∑
w
∈
C
o
r
p
u
s
log
P
(
w
∣
C
o
n
t
e
x
t
(
w
)
)
=
∑
w
∈
C
o
r
p
u
s
log
∏
i
=
1
l
e
n
(
p
a
t
h
(
w
)
)
P
(
p
a
t
h
(
w
)
i
∣
C
o
n
t
e
x
t
(
w
)
)
=
∑
w
∈
C
o
r
p
u
s
∑
i
=
1
l
e
n
(
p
a
t
h
(
w
)
)
log
P
(
p
a
t
h
(
w
)
i
∣
C
o
n
t
e
x
t
(
w
)
)
=
∑
w
∈
C
o
r
p
u
s
∑
i
=
1
l
e
n
(
p
a
t
h
(
w
)
)
log
{
[
σ
(
x
w
T
θ
(
w
)
i
)
]
1
−
p
a
t
h
(
w
)
i
⋅
[
1
−
σ
(
x
w
T
θ
(
w
)
i
)
]
p
a
t
h
(
w
)
i
}
=
∑
w
∈
C
o
r
p
u
s
∑
i
=
1
l
e
n
(
p
a
t
h
(
w
)
)
log
[
σ
(
x
w
T
θ
(
w
)
i
)
]
1
−
p
a
t
h
(
w
)
i
+
log
[
1
−
σ
(
x
w
T
θ
(
w
)
i
)
]
p
a
t
h
(
w
)
i
=
∑
w
∈
C
o
r
p
u
s
∑
i
=
1
l
e
n
(
p
a
t
h
(
w
)
)
{
[
1
−
p
a
t
h
(
w
)
i
]
log
σ
(
x
w
T
θ
(
w
)
i
)
+
p
a
t
h
(
w
)
i
log
[
1
−
σ
(
x
w
T
θ
(
w
)
i
)
]
}
\begin{aligned} L & =\sum_{w\in Corpus} \log P(w|Context(w)) \\ & =\sum_{w\in Corpus} \log \prod_{i=1}^{len(path(w))} P(path(w)_i|Context(w)) \\ & =\sum_{w\in Corpus} \sum_{i=1}^{len(path(w))} \log \ P(path(w)_i|Context(w)) \\ & = \sum_{w\in Corpus} \sum_{i=1}^{len(path(w))} \log \ \{[\sigma(x_w^T\theta (w)_i)]^{1-path(w)_i} \cdot [1-\sigma(x_w^T\theta (w)_i)]^{path(w)_i} \} \\ & = \sum_{w\in Corpus} \sum_{i=1}^{len(path(w))} \log \ [\sigma(x_w^T\theta (w)_i)]^{1-path(w)_i} + \log [1-\sigma(x_w^T\theta (w)_i)]^{path(w)_i} \\ & = \sum_{w\in Corpus} \sum_{i=1}^{len(path(w))} \{[1-path(w)_i] \log \sigma(x_w^T\theta (w)_i) + path(w)_i \log [1-\sigma(x_w^T\theta (w)_i)]\} \end{aligned}
L=w∈Corpus∑logP(w∣Context(w))=w∈Corpus∑logi=1∏len(path(w))P(path(w)i∣Context(w))=w∈Corpus∑i=1∑len(path(w))log P(path(w)i∣Context(w))=w∈Corpus∑i=1∑len(path(w))log {[σ(xwTθ(w)i)]1−path(w)i⋅[1−σ(xwTθ(w)i)]path(w)i}=w∈Corpus∑i=1∑len(path(w))log [σ(xwTθ(w)i)]1−path(w)i+log[1−σ(xwTθ(w)i)]path(w)i=w∈Corpus∑i=1∑len(path(w)){[1−path(w)i]logσ(xwTθ(w)i)+path(w)ilog[1−σ(xwTθ(w)i)]}
至此, 得到了CBOW模型的目标函数. 我们通过随机梯度下降法来求它的最大值.
这个模型中的参数有
x
w
,
θ
(
w
)
i
x_w, \theta (w)_i
xw,θ(w)i , 其中
x
w
x_w
xw 就是我们需要的单词w的词向量.
skip-gram
这里再简述下 skip-gram 的思想.
在CBOW中, 拿 context(w) 去沿着 path(w) 行走. 在 skip-gram 中, 拿 x(w) 分别沿 path(w(t-2)),path(w(t-1)),path(w(t+1)),... 行走.
NEG
NCE, Noise Contrastive Estimation ,噪声对比估计.
NEG, NEGative Sampling, 负采样. 可以理解为NCE思想的一个简化实现.
原始的计算方法,
p
(
w
j
∣
w
i
)
=
e
x
p
(
e
j
e
i
)
∑
d
=
1
D
e
x
p
(
e
d
e
i
)
p(w_j|w_i)=\frac{exp(e_j e_i)}{\sum_{d=1}^D exp(e_d e_i)}
p(wj∣wi)=∑d=1Dexp(edei)exp(ejei)
性能太差, 需要对所有单词都做向量乘法计算, 为此可以使用 Hierarchial softmax 代替标准的 softmax. 现在使用 NCE, 可以更进一步节省性能.
为词语
w
j
w_j
wj收集它的负采样集合.
N
E
G
(
w
j
)
NEG(w_j)
NEG(wj).
p
(
w
j
∣
w
i
)
=
σ
(
e
j
e
i
)
∏
s
=
0
S
(
1
−
σ
(
e
s
e
i
)
)
p(w_j|w_i)=\sigma(e_j e_i)\prod_{s=0}^{S} (1-\sigma (e_s e_i))
p(wj∣wi)=σ(ejei)s=0∏S(1−σ(esei))
1323
g
(
w
)
=
∏
u
∈
{
w
}
∪
u
∈
N
E
G
(
w
)
p
(
u
∣
C
o
n
t
e
x
t
(
w
)
)
=
σ
(
x
w
t
θ
w
)
∏
u
∈
N
E
G
(
w
)
[
1
−
σ
(
x
w
t
θ
u
)
]
g(w) = \prod_{u\in \{w\} \cup u\in NEG(w)} p(u|Context(w)) \\ =\sigma (x_w^t\theta^w) \prod_{u\in NEG(w)} [1-\sigma (x_w^t\theta^u)]
g(w)=u∈{w}∪u∈NEG(w)∏p(u∣Context(w))=σ(xwtθw)u∈NEG(w)∏[1−σ(xwtθu)]
cosine similarity vs. Euclidean distance
很多地方都倾向于使用 余弦距离 而非 欧氏距离.
相关讨论见[3], [4].
In the word2vec space, word的加减也是有语义的, 一个例子:

Figure In the word2vec space, word的加减也是有语义的
sample
在某语料库中, word2vec 训练后, 得到的向量长这个样子:
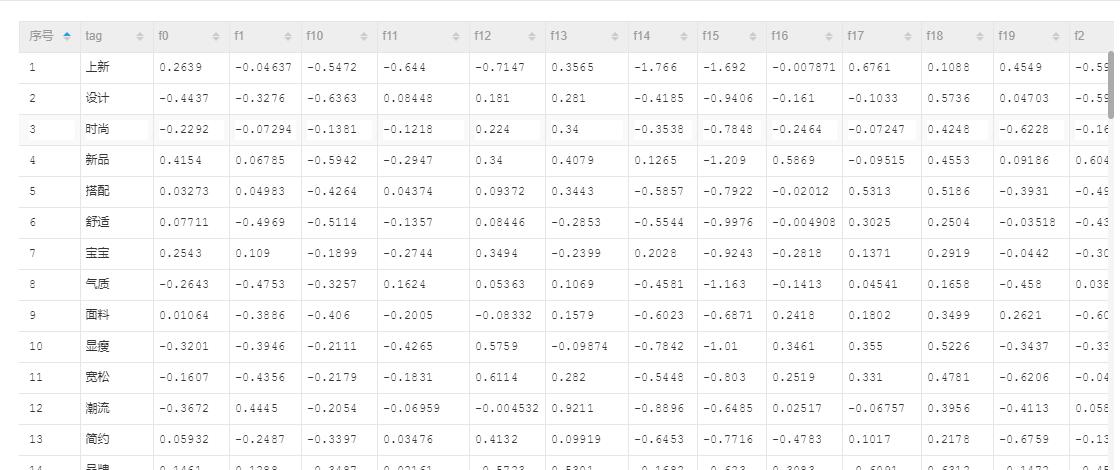
随机抽查一部分词, 查看它的 最相近的前10个词.
保护 防护,0.8080060492828974:防止,0.737328127236279:维护,0.756883036312962:隐私,0.719719004775421:伤害,0.7102083722640832:呵护,0.7689806653955088:损伤,0.7248499979768325:强化,0.7082930000123623:有效,0.7210036810963242:减缓,0.7072668026752227
拉高 腰线,0.7026912151587168:修饰,0.6623862734676348:身形,0.6848170794555877:显高,0.6935728006391041:腰身,0.6489577473319301:拉伸,0.683662826892513:腿部,0.6355870334962672:腿型,0.6465047962273794:比例,0.6344159161968872:高挑,0.6330144012527854
棉衣 羽绒服,0.8595425108447587:连帽外套,0.8124322006757069:棉服,0.9489753948632147:大毛领,0.8310189286473926:棉袄,0.8536170990915103:外套,0.8286431535527627:羊羔毛,0.8069242934406703:毛呢大衣,0.8067598668694049:呢子大衣,0.7952532387556884:两面穿,0.790104056339203
充斥 弥漫,0.7854175886673246:伴随,0.7242136738324945:围绕,0.7456771035320819:诉说,0.7450610596954507:承载,0.6818498865490531:蔓延,0.6813511537988906:洋溢,0.6819810565565785:无处不在,0.6761426397296442:意味,0.6791400707402294:散发,0.6662296499431495
受 深受,0.6504423419823643:青睐,0.6923765203398384:追捧,0.692126859277624:喜爱,0.6605105895823916:因而,0.6525599904683921:影响,0.6499564689374678:备受,0.689604965413093:伤害,0.639200609139887:广大,0.6447122224527433:认可,0.6320602224230568
本真 朴实,0.7888601295751051:纯真,0.7778734549110182:淳朴,0.8130077163758056:大自然,0.7310053770582935:本质,0.752657465057506:质朴,0.7872175509729687:原始,0.7744899474862871:真实,0.7288218268384364:回归,0.7350083313624669:崇尚,0.722597418168269















 1552
1552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









