







这一篇博文是【大数据技术●降龙十八掌】系列文章的其中一篇,点击查看目录:
-
系列文章:
-
【十八掌●武功篇】第十二掌:Flume之工作原理与使用
【十八掌●武功篇】第十二掌:Flume之Source、Channel、Sink
【十八掌●武功篇】第十二掌:Flume之安装和测试使用
选用CDH版本的Flume
1、 下载Flume安装包
http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.5.0-cdh5.3.6.tar.gz
2、 解压安装包
tar -zxvf /opt/software/flume-ng-1.5.0-cdh5.3.6.tar.gz -C /opt/modules/
3、 配置
拷贝配置文件
cp flume-env.sh.template flume-env.sh
cp flume-conf.properties.template flume-conf.properties
配置flume-env.sh
export JAVA_HOME=/opt/modules/jdk1.7.0_67
4、 测试运行(netcat source + memory channel + logger sink)
这个例子中source类型为netcat(监听Socket)、channel类型为memory(存入内存)、sink类型为logger(写入日志),结构图如下所示:
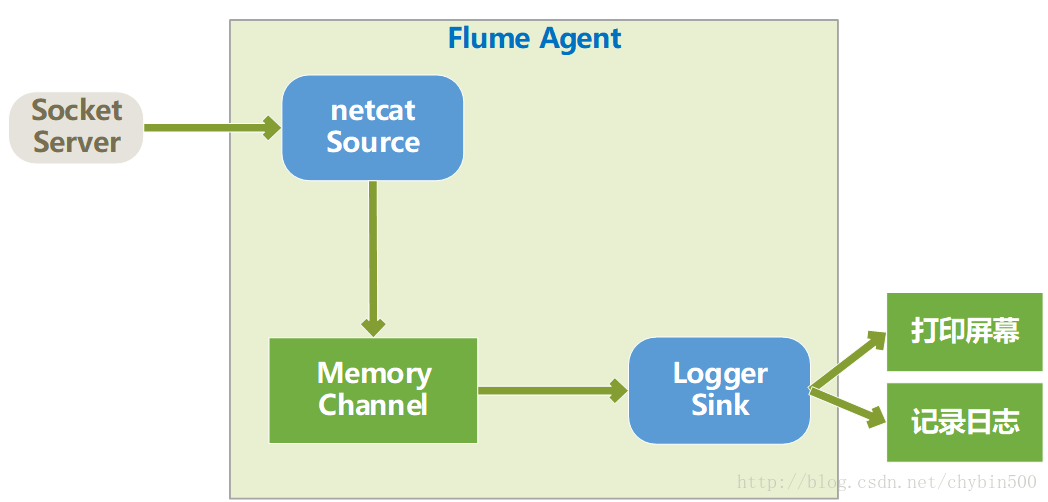
(1) 配置source、channel、sink。官网有个例子如下:
# example.conf: A single-node Flume configuration
# Name the components on this agent
#a1是agent名称。
#a1.sources执行名为a1的agent的source是哪些,如果有多个,就在r1后面添加一个空格后,添加第二个名称
#a1.sources=r1 r2 r3
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
#r1.type是netcat,是个socket服务器
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
#写到日志里去
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
#c1.type是memory是将数据放入内存
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
#将source、channel、sink连接起来
#sources可以将数据传入多个channel
#sinks只能从一个channel里读取数据
#channel可以将数据发送到多个sink中
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
# example.conf: A single-node Flume configuration
# Name the components on this agent
#a1是agent名称。
#a1.sources执行名为a1的agent的source是哪些,如果有多个,就在r1后面添加一个空格后,添加第二个名称
#a1.sources=r1 r2 r3
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
#r1.type是netcat,是个socket服务器
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
#写到日志里去
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
#c1.type是memory是将数据放入内存
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
#将source、channel、sink连接起来
#sources可以将数据传入多个channel
#sinks只能从一个channel里读取数据
#channel可以将数据发送到多个sink中
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
在conf目录下创建一个配置文件:demo.conf,将上面的配置内容拷贝到demo.conf配置文件中。
(2) 启动flume agent:
/opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/bin/flume-ng agent –name a1 –conf conf/ –conf-file conf/demo.conf -Dflume.root.logger=INFO,console
使用bin目录下的flume-ng脚本启动agent;
–name是agent的名称,要跟配置文件demo.conf中定义的agent名称一致。
–conf是指定flume的配置文件路径,注意并不是flume agent的配置文件。
–conf-file是指定flume agent的配置文件路径。
–Dflume.root.logger是指定打印的日志。
启动后,是处于阻塞状态的,这个agent的source是个socket,所以在等待socket输入。
(3) 查看44444端口是否已经成功启动:
netstat -tlnup |grep 44444
(4) 测试发送信息
使用nc工具发送socket信息:
nc localhost 44444
在flume agent的窗口可以看到Flume的sink已经输出到了发送的数据。
5、 测试运行(avro source + file channel + hdfs sink )
(1) 结构图如下所示:
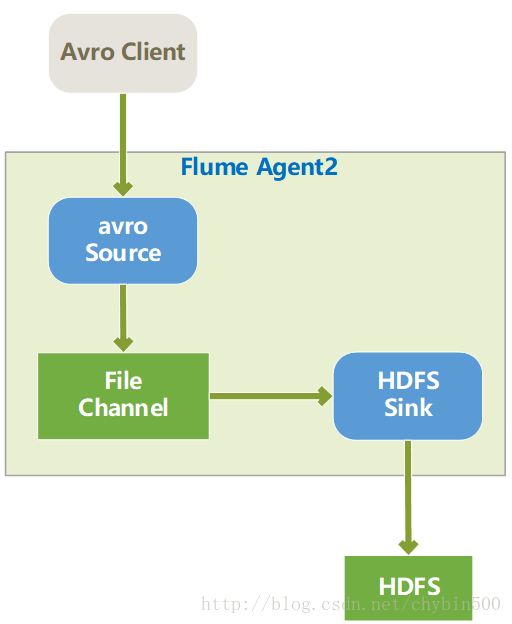
(2) 配置如下:
# example.conf: A single-node Flume configuration
# Name the components on this agent
#a1是agent名称。
#a1.sources执行名为a1的agent的source是哪些,如果有多个,就在r1后面添加一个空格后,添加第二个名称
#a1.sources=r1 r2 r3
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
#配置source类型为avro,avro服务在本地,端口号为4141
a1.sources.r1.type = avro
a1.sources.r1.bind = localhost
a1.sources.r1.port = 4141
# Describe the sink
#配置sink类型为hdfs、文件写入的路径
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://bigdata-51cdh.chybinmy.com:8020/flume/demo
# default:FlumeData
#定义hdfs文件名的前缀
a1.sinks.k1.hdfs.filePrefix = my-
#配置是否使用本地时间戳,应该设置为true
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#文件达到什么条件后创建一个新的文件,rollInterval、rollCount、rollSize只能选其一
#rollInterval是当间隔多长时间分割一个新的文件,如果是0就是不启用这个策略
a1.sinks.k1.hdfs.rollInterval = 0
#rollCount是写入的次数,达到指定次数后就新建一个文件
a1.sinks.k1.hdfs.rollCount = 0
#rollSize是文件大小,当文件达到指定大小后就新建一个文件
a1.sinks.k1.hdfs.rollSize = 10240
#文件格式,可以选择的有:SequenceFile、DataStream、CompressedStream
#SequenceFile是键值对形式的数据
#DataStream是文本类型的数据
#CompressedStream是压缩格式的数据,这种格式下,需要设置压缩格式。
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
#c1.type是file是将数据放入文件中
a1.channels.c1.type = file
#设置file channel的checkpoint目录
a1.channels.c1.checkpointDir = /opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/my_check_file
#设置file存储的目录
a1.channels.c1.dataDirs = /opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/my_data
# Bind the source and sink to the channel
#将source、channel、sink连接起来
#sources可以将数据传入多个channel
#sinks只能从一个channel里读取数据
#channel可以将数据发送到多个sink中
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
(3) 启动agent
/opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/bin/flume-ng agent -name a1 -c /opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/conf/ -conf-file /opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/conf/demo2.conf -Dflume.root.logger=INFO,console(4) 检查端口4141是否启动
netstat -tlnup | grep 4141
(5) 发送avro数据
/opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/bin/flume-ng avro-client -H localhost -p 4141 -F /home/hadoop/input.txt
使用flume自带的avro client将文件input.txt发送到4141端口,flume的avro source接受到数据后,通过file channel,使用hdfs sink发送到配置到好的hdfs路径上去。
(6) 查看HDFS的数据
hadoop fs -ls hdfs://bigdata-51cdh.chybinmy.com:8020/flume/demo
hadoop fs -cat /flume/demo/my-.1502151699610.tmp
6、 测试运行(spooldir source + memory channel + hdfs sink )
(1) 结构图如下所示
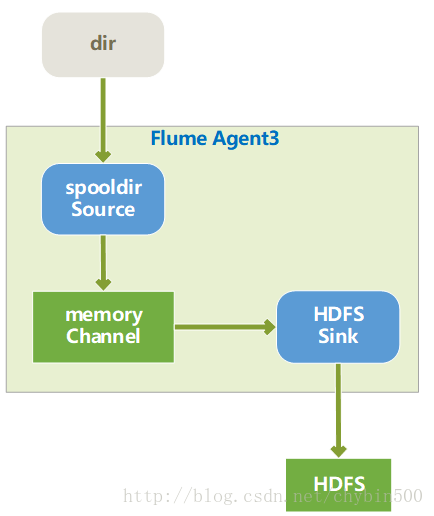
(2) 配置如下
# example.conf: A single-node Flume configuration
# Name the components on this agent
#a1是agent名称。
#a1.sources执行名为a1的agent的source是哪些,如果有多个,就在r1后面添加一个空格后,添加第二个名称
#a1.sources=r1 r2 r3
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
#配置source类型为spooldir,监控本地目录,一有新的文件就读取
a1.sources.r1.type = spooldir
#要监控的目录
a1.sources.r1.spoolDir = /opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/myspoolfils
#是否将信息头里的信息放入
a1.sources.r1.fileHeader = true
a1.sources.r1.fileHeaderKey = file
# Describe the sink
#配置sink类型为hdfs、文件写入的路径
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://bigdata-51cdh.chybinmy.com:8020/flume/spoolfile
# default:FlumeData
#定义hdfs文件名的前缀
a1.sinks.k1.hdfs.filePrefix = spoolfile -
#配置是否使用本地时间戳,应该设置为true
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#文件达到什么条件后创建一个新的文件,rollInterval、rollCount、rollSize只能选其一
#rollInterval是当间隔多长时间分割一个新的文件,如果是0就是不启用这个策略
a1.sinks.k1.hdfs.rollInterval = 0
#rollCount是写入的次数,达到指定次数后就新建一个文件
a1.sinks.k1.hdfs.rollCount = 0
#rollSize是文件大小,当文件达到指定大小后就新建一个文件
a1.sinks.k1.hdfs.rollSize = 10240
#文件格式,可以选择的有:SequenceFile、DataStream、CompressedStream
#SequenceFile是键值对形式的数据
#DataStream是文本类型的数据
#CompressedStream是压缩格式的数据,这种格式下,需要设置压缩格式。
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
#c1.type是memory是将数据放入内存中
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
#将source、channel、sink连接起来
#sources可以将数据传入多个channel
#sinks只能从一个channel里读取数据
#channel可以将数据发送到多个sink中
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
(3) 启动agent
/opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/bin/flume-ng agent -name a1 -c /opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/conf/ -conf-file /opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/conf/demo3.conf -Dflume.root.logger=INFO,console(4) 将文件拷贝进监听目录
cp /home/hadoop/actionlog2016-08-20.txt /opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/myspoolfils/
(5) 查看HDFS文件
hadoop fs -ls /flume/spoolfile
spoolfile source监听目录,有了新文件就读取后存入hdfs上指定的目录中。
7、 测试运行(多个agent汇集到一个agent)
(1) 结构
三个agent:http source + memory channel + avro sink
汇集agent:avro source + file channel + hdfs sink
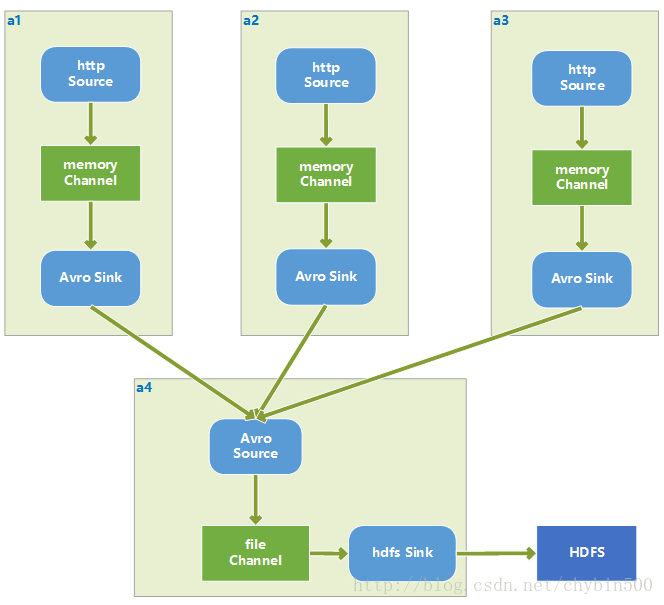
(2) 配置
a1、a2、a3配置如下:(注意a2、a3要将agent名字应该分别为a3、a4,另外http source监听的端口号应该不同)
# example.conf: A single-node Flume configuration
# Name the components on this agent
#a1是agent名称。
#a1.sources执行名为a1的agent的source是哪些,如果有多个,就在r1后面添加一个空格后,添加第二个名称
#a1.sources=r1 r2 r3
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
#配置source类型为http,监控一个端口的http请求
a1.sources.r1.type = http
#a1监听的是5140端口,a2、a3应该监听其他端口号,比如a2监听5141,a3监听5142
a1.sources.r1.port = 5140
#数据格式为json
a1.sources.r1.handler = org.apache.flume.source.http.JSONHandler
# Describe the sink
#配置sink类型为avro,以便传递给下一个汇集agent a4
a1.sinks.k1.type = avro
#传递给avro的主机
a1.sinks.k1.hostname = localhost
#avro的端口号
a1.sinks.k1.port = 4545
# Use a channel which buffers events in memory
#c1.type是memory是将数据放入内存中
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
#将source、channel、sink连接起来
#sources可以将数据传入多个channel
#sinks只能从一个channel里读取数据
#channel可以将数据发送到多个sink中
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a4配置
# example.conf: A single-node Flume configuration
# Name the components on this agent
#a4是agent名称。
#a4.sources执行名为a4的agent的source是哪些,如果有多个,就在r1后面添加一个空格后,添加第二个名称
#a4.sources=r1 r2 r3
a4.sources = r1
a4.sinks = k1
a4.channels = c1
# Describe/configure the source
#配置source类型为avro,avro服务在本地,端口号为4141
a4.sources.r1.type = avro
a4.sources.r1.bind = localhost
a4.sources.r1.port = 4545
# Describe the sink
#配置sink类型为hdfs、文件写入的路径
a4.sinks.k1.type = hdfs
a4.sinks.k1.hdfs.path = hdfs://bigdata-51cdh.chybinmy.com:8020/flume/collect/%Y-%m-%d
# default:FlumeData
#定义hdfs文件名的前缀
a4.sinks.k1.hdfs.filePrefix = collect-
#配置是否使用本地时间戳,应该设置为true
a4.sinks.k1.hdfs.useLocalTimeStamp = true
#文件达到什么条件后创建一个新的文件,rollInterval、rollCount、rollSize只能选其一
#rollInterval是当间隔多长时间分割一个新的文件,如果是0就是不启用这个策略
a4.sinks.k1.hdfs.rollInterval = 0
#rollCount是写入的次数,达到指定次数后就新建一个文件
a4.sinks.k1.hdfs.rollCount = 0
#rollSize是文件大小,当文件达到指定大小后就新建一个文件
a4.sinks.k1.hdfs.rollSize = 10240
#文件格式,可以选择的有:SequenceFile、DataStream、CompressedStream
#SequenceFile是键值对形式的数据
#DataStream是文本类型的数据
#CompressedStream是压缩格式的数据,这种格式下,需要设置压缩格式。
a4.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
#c1.type是memory是将数据放入内存中
#c1.type是file是将数据放入文件中
a4.channels.c1.type = file
#设置file channel的checkpoint目录
a4.channels.c1.checkpointDir = /opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/my_check_file
#设置file存储的目录
a4.channels.c1.dataDirs = /opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/my_data
# Bind the source and sink to the channel
#将source、channel、sink连接起来
#sources可以将数据传入多个channel
#sinks只能从一个channel里读取数据
#channel可以将数据发送到多个sink中
a4.sources.r1.channels = c1
a4.sinks.k1.channel = c1
(3) 启动agent
/opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/bin/flume-ng agent -n a1 -c /opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/conf/ -f /opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/conf/a1.conf -Dflume.root.logger=INFO,console &
/opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/bin/flume-ng agent -n a2 -c /opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/conf/ -f /opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/conf/a2.conf -Dflume.root.logger=INFO,console &
/opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/bin/flume-ng agent -n a3 -c /opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/conf/ -f /opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/conf/a3.conf -Dflume.root.logger=INFO,console &
/opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/bin/flume-ng agent -n a4 -c /opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/conf/ -f /opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/conf/a4.conf -Dflume.root.logger=INFO,console &
(4) 发送post 请求
curl -X POST -d'[{"headers" : {"timestamp" : "434324343","host" :"random_host.example.com"},"body" : "random_body"},{"headers" : {"namenode" : "namenode.example.com","datanode" :"random_datanode.example.com"},"body" :"really_random_body"}]' localhost:5140(5) 查看HDFS上数据
hadoop fs -ls /flume/collect/2017-08-08
hadoop fs -cat /flume/collect/2017-08-08/collect-.1502177104663.tmp
这一篇博文是【大数据技术●降龙十八掌】系列文章的其中一篇,点击查看目录:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









