







这一篇博文是【大数据技术●降龙十八掌】系列文章的其中一篇,点击查看目录:
-
系列文章:
-
【十八掌●武功篇】第十二掌:Flume之工作原理与使用
【十八掌●武功篇】第十二掌:Flume之Source、Channel、Sink
【十八掌●武功篇】第十二掌:Flume之安装和测试使用
一、 Flume简介
1、 Flume定义
Flume是实时日志收集工具,是一个分布式的、可靠的、高可用的、高效的对大数据量的日志数据进行收集、聚合和传输的系统,它可以收集不同数据源的数据进行集中存储。
CDH版本的文档地址:http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.5.0-cdh5.3.6/
2、 使用Flume的原因
从数据生产节点将数据传输到HDFS、HBase往往需要通过中间一个起缓冲作用的工具,Flume、Kafka等就是这样的工具,他们从大量的各个数据源采集数据,然后写入HDFS。为什么不直接从每个生产节点直接写入HDFS,而使用Flume呢?有以下几个原因:
(1) 减少写入HDFS的用户量。
生产数据的节点往往很多,如果这些节点都直接写入HDFS或者HBase,会造成NameNode承受很大的压力,网络也会不堪重负,通过Flume汇集各个数据源的数据,然后由Flume统一写入HDFS或者HBase会解决这个问题。
(2) 减少HDFS写入网络延迟
如果各个数据生产节点直连HDFS时,很多情况下是跨广域网的,网络延迟会比较大,写入HDFS的操作失败的概率会变大,如果通过广域网将数据慢慢地汇集到Flume,再由Flume统一通过局域网写入,能减少写入延迟,增加写入成功概率。
(3) 流量消峰
Flume可以起到缓存的作用,各个数据生产节点过来的高峰流量,经过Flume后,可以缓存,以稳定的速度写入HDFS。
(4) 保证数据不会丢失
(5) 扩展性强
Flume被设计为分布式的、很容易扩展的系统,可以通过简单地增加Flume Agent就能够扩展服务器的数量。
3、 一个应用实例
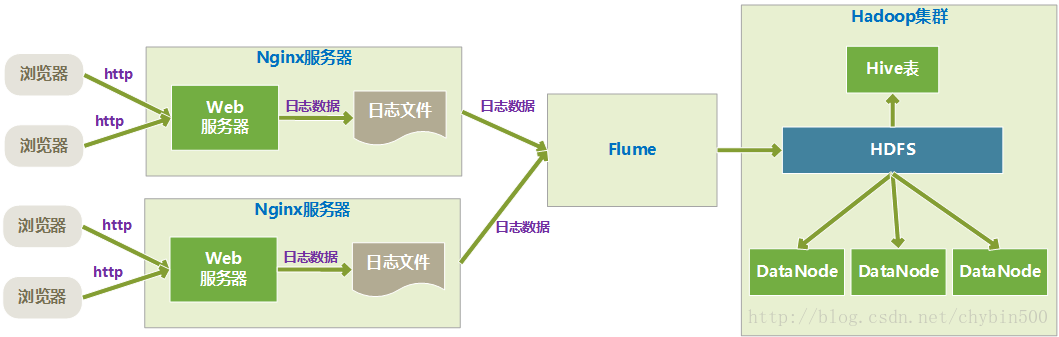
这个例子是Flume监听Nginx Web服务器的日志文件,然后存入HDFS中。
二、 Flume工作原理
1、 Flume组成
每一个Flume实例是一个agent,每一个agenet是一个JVM,每一个Flume Agent由三部分组成:source、channel、sink。
(1) source是数据来源,与外部数据源结合,获取或者接收数据,可以source主动监听外部数据,也可以被动接收外部传递过来的数据,每个source必须至少连接一个channel。
(2) channel的行为很像队列,source接收到数据后,存入channel,sink从channel里拉取数据。
(3) sink从channel里获取数据,发送出去,sink消费完数据后,从channel里移除数据。
Flume中的source、channel、sink有不同的类型,不同的业务场景选择合适的对应类型。
2、 常用的source类型
(1) avro source:avro是二进制数据传输协议,avro类似于json、xml,定义了数据格式,常用在接收其他agent传来的数据。
(2) netcat source:相当于socket客户端,接收socket信息。
(3) http source:监听http。
(4) spooldir source:监听本地文件系统的目录,如果这个目录有新的文件,就读取这个文件
(5) exec source:tail –f 监听本地文件系统的文件。
3、 常用的channel类型
(1) memory channel:内存channel,速度快,数据可能会丢失。
(2) file channel:文件channel。速度慢,可以保证数据不会丢失,会记录数据及检查点。
4、 常用的sink类型
(1) logger sink:将数据写入日志或者打印到控制台,常用于调试。
(2) hdfs sink:上传数据到hdfs。
(3) kafka sink:将数据传送到kafka。
(4) avro sink:连接不同的agent。将数据发送到其他agent上去。
(5) file sink:写入本地文件。
5、 Flume Agent内部原理
Flume Agent内部是以event对象传递数据的,event对象是非常简单的数据结构,它有一个headers和body组成,headers是一个map对象,其中有多个键值对。headers是用来路由和跟踪event的,并不存储日志数据;body是一个二进制数组,存储的是日志数据。
一个Flume Agent内部工作流程如下图所示:
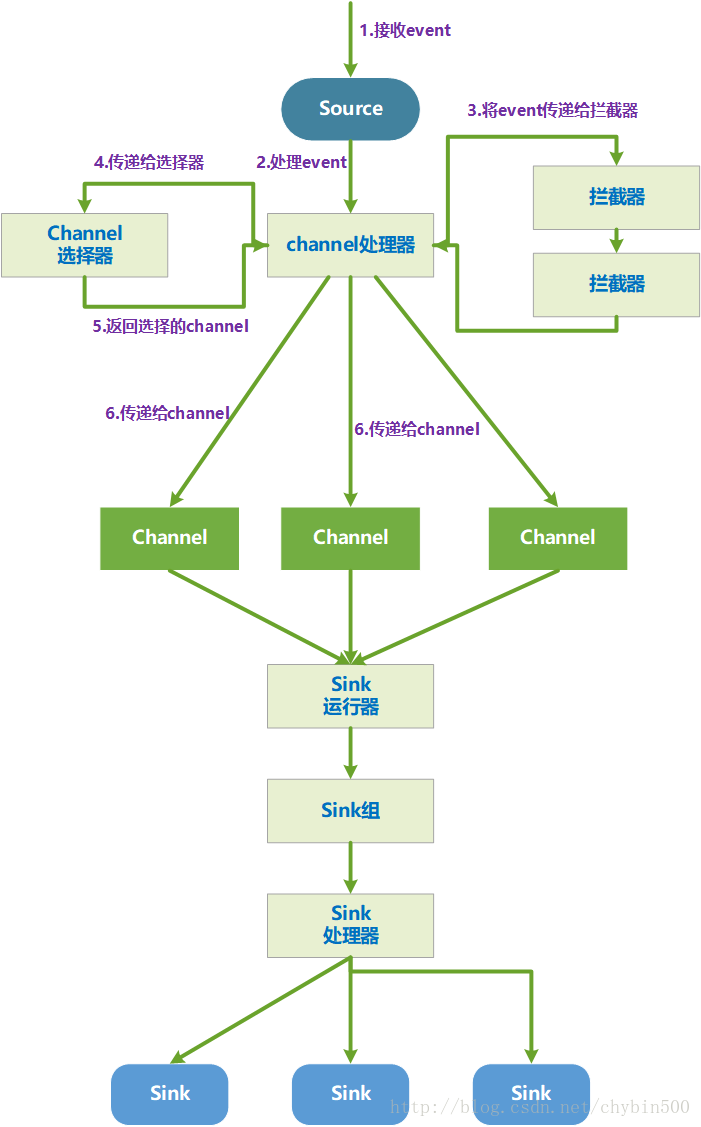
(1) source接收到一个event对象
(2) source将event对象交给channel处理器处理这个event
(3) channel处理器将这个event传递到一个或者多个source拦截器中,拦截器是一段代码,拦截器可以读取、修改、删除event,可以添加新的headers值、移除headers值。每一个source可以设置多个拦截器,按照配置的顺序依次执行拦截器,执行完成后返回给channel处理器。
(4) 将event传给channel选取器,由channel选择器决定将当前event传入哪个channel。
(5) channel将选择好的chennel信息告诉channel处理器,可以是多个channel。
(6) channel处理器将event对象传递给对应的channel,也可以传递给多个channel。
(7) sink运行器是一个线程,它运行一个sink组,一个sink组中有一个或者多个sink,一个sink组有一个sink处理器(sink processor),sink处理器选择一个sink处理event对象。
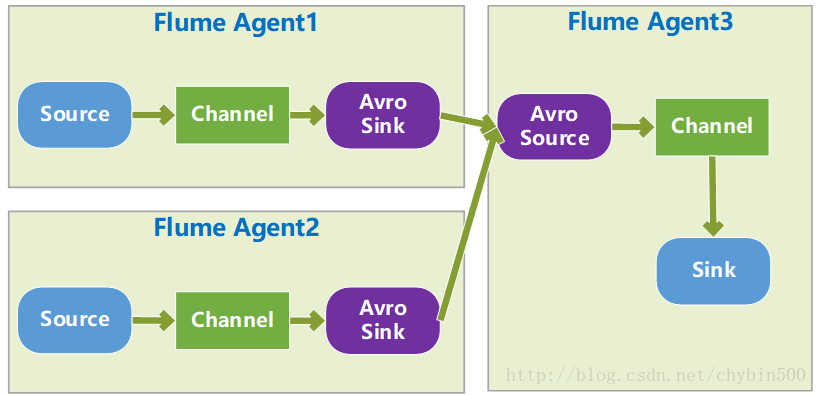
6、 Flume Agent之间的通信
针对于Flume Agent之间通讯的需求,Flume内置了专门的sink-source对Arvo-sink – Avro Soucre,数据发送的Agent采用avro sink,接收数据的Agent采用avro source。
7、 无数据丢失保证和channel事务
Flume中的持久性保证依赖于使用持久性的Channel,Flume自带了两类Channel:memory channel和file channel,memory channel是将数据存储在内存中,JVM重启或者机器重启都会造成数据丢失,如果使用file channel,数据是存储在硬盘里的,JVM重启或者机器重启都能保证数据不会丢失。
channel本身是事务性的,这是保证数据无丢失的关键,无论是当source将event写入channel或者是sink从channel中读取event时,都会利用channel启动一个事务,它们必须在事务的范围内进行操作。Flume保证event至少一次被成功送到它的目的地,但是不能保证只被送了一次,所以要考虑数据重复的问题。
8、 批量event处理
当event到达source,channel 处理器会启动一个事务,如果是file channel,一个事务的提交会触发一次文件同步的操作,文件同步的操作成本非常高,如果单次处理几个event,将会节约资源,提高效率。
三、 Flume的使用
1、 配置Flume Agent
Flume Agent使用纯文本配置文件来配置,Flume Agent配置使用属性文件格式,属性文件格式是以类似key1=values1格式来配置的。
Flume Agent的配置可以分为两个部分:
(1) 活跃列表
在配置文件中要对每一个Flume Agent命名,Flume Agent中的Source、Channel、Sink、SinkGroup可以有若干实例,为了能够识别这些不同的实例,也要对这些组件进行命名。
a1.sources = source1 source2
a1.sinks = sink1 sink2 sink3 sink4
a1.sinkgroups = sg1 sg2
a1.channels = channel1 channel2
这个列表指定了这个Agent里所有的组件,没有定义的组件不会被创建和启动。
(2) 组件配置
这部分是对source、channel、sink的配置,格式为:
...=
2、 启动Flume Agent
(1) 启动Agent的命令
使用Flume根目录下bin下的flume-ng脚本启动一个Agent,需要制定的参数有:Flume Agent名称、Flume配置文件路径、Flume Agent配置文件路径。
举例:
/opt/modules/apache-flume-1.5.0-cdh5.3.6-bin/bin/flume-ng agent --name a1 --conf conf/ --conf-file conf/demo.conf -Dflume.root.logger=INFO,consoleflume-ng脚本参数有以下几个:
| 参数 | 说明 |
|---|---|
| -n | 启动的Agent名称,要跟Agent配置中的名称一致 |
| -f | Flume Agent的配置文件 |
| -c | 指定Flume的配置目录 |
| -C | 添加到classpath的目录列表,也可以在Flume_CLASSPATH中指定 |
| -d | |
| –plugins-path | |
| -h | 打印帮助信息 |
(2) Flume Agent配置文件
Flume Agent的配置文件中,可以包括多个Agent的配置,每一个Agent指定一个唯一的名称,当启动Agent时指定一个agent名称,flume-ng脚本只是加载这个指定名称的配置项。
很多时间,Flume一层中所有的Agent都使用相同的名称。
(3) Flume配置目录
使用-c指定的参数是Flume配置目录的位置,这个目录下有两个重要的配置文件:flume-env.sh和log4j.properties。flume-env.sh配置文件中配置的是环境变量,常用的配置如下:
| 参数 | 说明 |
|---|---|
| FLUME_CLASSPATH | 除了Flume lib和plugins.d目录外,其他的目录,多个目录之间用:分割。 |
| JAVA_OPTS | Flume启动JVM时传递的参数,可以控制内存和从命令行传递参数 |
| HADOOP_HOME | Hadoop的安装目录($HADOOP_HOME/bin包含Hadoop可执行文件) |
| HBASE_HOME | Hbase的安装目录 |
四、 Flume常见架构
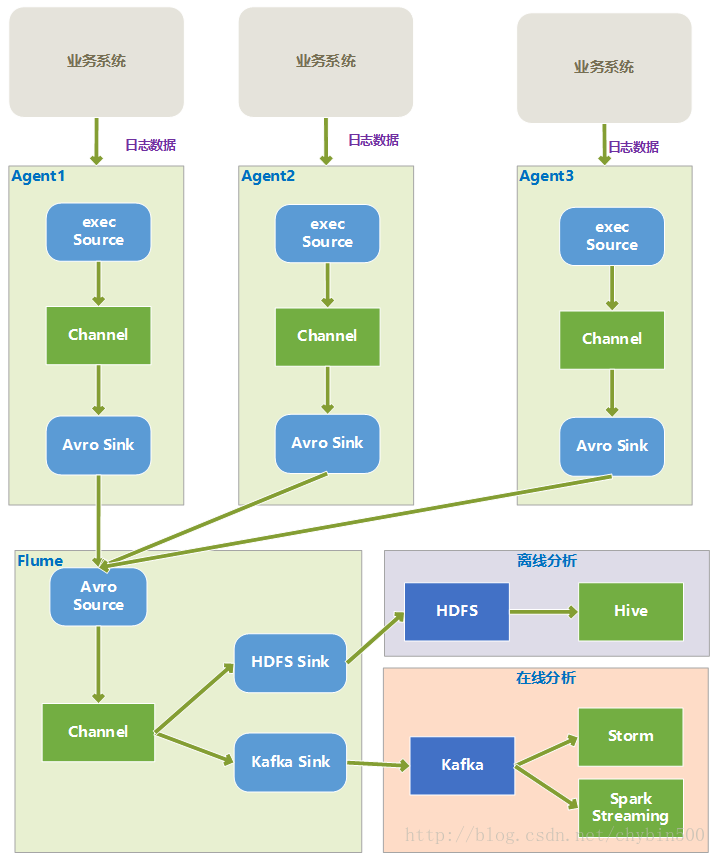
1、 多个Agent汇集到一个Agent
2、 容错模式
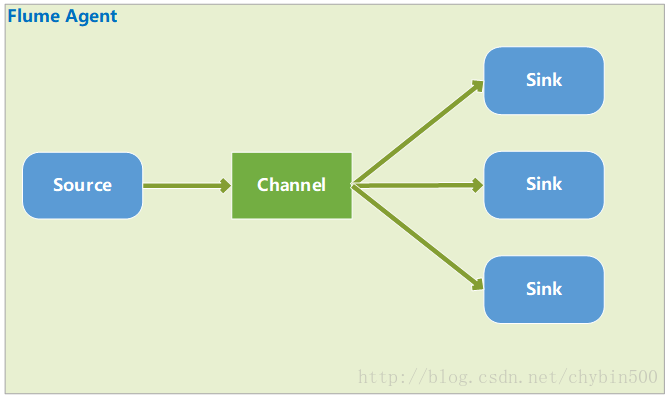
容错是对sink的容错,有多个sink,每个sink有个权重值,channel的数据只发送到其中一个sink中,根据权重值分配发送到哪个sink,总是发送到权重值最大的sink,当权重值最大的sink宕机后,选择权重值次大的sink发送数据。
容错模式需要以下配置:
#定义一个sink组名称
a1.sinkgroups = g1
#设置组内有哪些Sink
a1.sinkgroups.g1.sinks = k1 k2
#设置组内组件的类型,设置为failover,是容错模式
a1.sinkgroups.g1.processor.type = failover
#设置组内Sink k1的权重值
a1.sinkgroups.g1.processor.priority.k1 = 5
#设置组内Sink k2的权重值
a1.sinkgroups.g1.processor.priority.k2 = 10
a1.sinkgroups.g1.processor.maxpenalty = 10000
举个例子:
### failover
# Name the components on this agent
a1.sources = r1
a1.sinks = avro_sink0 avro_sink1 avro_sink2
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = hive-stu2
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.avro_sink0.type = avro
a1.sinks.avro_sink0.channel = c1
a1.sinks.avro_sink0.hostname = hive-stu2
a1.sinks.avro_sink0.port = 4545
a1.sinks.avro_sink1.type = avro
a1.sinks.avro_sink1.channel = c1
a1.sinks.avro_sink1.hostname = hive-stu2
a1.sinks.avro_sink1.port = 4646
a1.sinks.avro_sink2.type = avro
a1.sinks.avro_sink2.channel = c1
a1.sinks.avro_sink2.hostname = hive-stu2
a1.sinks.avro_sink2.port = 4747
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.hdfs_sink0.channel = c1
a1.sinks.hdfs_sink1.channel = c1
a1.sinks.hdfs_sink2.channel = c1
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = hdfs_sink0 hdfs_sink1 hdfs_sink2
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.avro_sink0 = 5
a1.sinkgroups.g1.processor.priority.avro_sink1 = 10
a1.sinkgroups.g1.processor.priority.avro_sink2 = 15
a1.sinkgroups.g1.processor.maxpenalty = 10000
3、 负载均衡
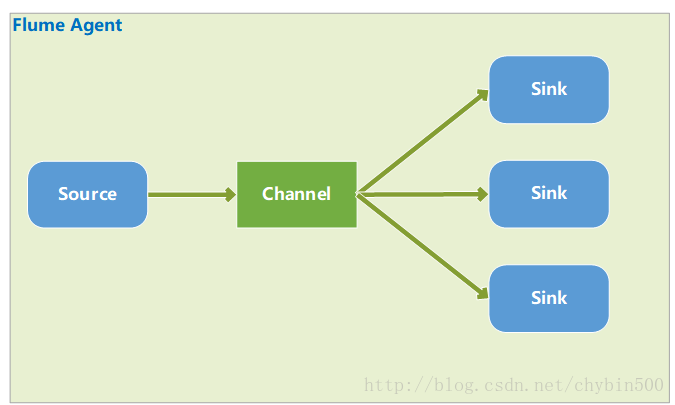
负载均衡的结构和容错模式结构图是一样的,不同点在于负载均衡模式中channel的数据根据一定算法可能会发送到任意一个sink中。
#定义一个sink组
a1.sinkgroups = g1
#设置组内的sink有哪些
a1.sinkgroups.g1.sinks = k1 k2
#设置类型为负载均衡模式load_balance
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
#选择sink的算法,random是随机选择
a1.sinkgroups.g1.processor.selector = random举个例子:
# sinks ---> load_balance
# netcat source ---> memory channel -->
# kafka_sink hdfs_sink
# Name the components on this agent
a1.sources = r1
#a1.sinks = kafka_sink hdfs_sink1 hdfs_sink2
a1.sinks = hdfs_sink0 hdfs_sink1 hdfs_sink2
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = hive-stu2
a1.sources.r1.port = 44444
# Describe the sink
# a1.sinks.kafka_sink
a1.sinks.hdfs_sink0.type = hdfs
a1.sinks.hdfs_sink0.hdfs.path = /flume/events0/%Y-%m-%d
a1.sinks.hdfs_sink0.hdfs.useLocalTimeStamp = true
a1.sinks.hdfs_sink0.hdfs.fileType = DataStream
a1.sinks.hdfs_sink0.hdfs.rollInterval = 0
a1.sinks.hdfs_sink0.hdfs.rollSize = 102400
a1.sinks.hdfs_sink0.hdfs.rollCount = 0
a1.sinks.hdfs_sink1.type = hdfs
a1.sinks.hdfs_sink1.hdfs.path = /flume/events1/%Y-%m-%d
a1.sinks.hdfs_sink1.hdfs.useLocalTimeStamp = true
a1.sinks.hdfs_sink1.hdfs.fileType = DataStream
a1.sinks.hdfs_sink1.hdfs.rollInterval = 0
a1.sinks.hdfs_sink1.hdfs.rollSize = 102400
a1.sinks.hdfs_sink1.hdfs.rollCount = 0
a1.sinks.hdfs_sink2.type = hdfs
a1.sinks.hdfs_sink2.hdfs.path = /flume/events2/%Y-%m-%d
a1.sinks.hdfs_sink2.hdfs.useLocalTimeStamp = true
a1.sinks.hdfs_sink2.hdfs.fileType = DataStream
a1.sinks.hdfs_sink2.hdfs.rollInterval = 0
a1.sinks.hdfs_sink2.hdfs.rollSize = 102400
a1.sinks.hdfs_sink2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.hdfs_sink0.channel = c1
a1.sinks.hdfs_sink1.channel = c1
a1.sinks.hdfs_sink2.channel = c1
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = hdfs_sink0 hdfs_sink1 hdfs_sink2
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = random
a1.sinkgroups.g1.processor.maxTimeOut = 20000
4、 多路复用
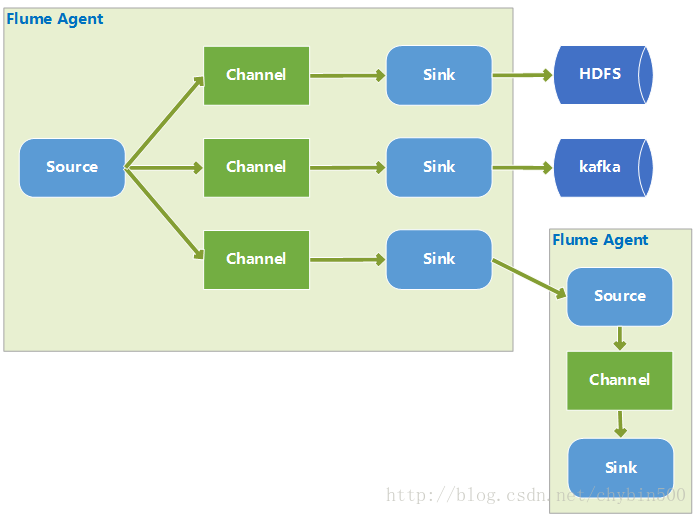
从source发出的数据,根据headers中的某一个key值来选择走哪一个channel,这也就是动态路由。
需要添加一下配置:
a1.sources = r1
a1.channels = c1 c2 c3 c4
#配置source的selecter.type为multiplexing(多路复用),默认为replicating(复制),复制模式下source的数据会发送给所有的channel
a1.sources.r1.selector.type = multiplexing
#根据event中的headers中key为state的值进行分发
a1.sources.r1.selector.header = state
#state值为CZ的走channel c1
a1.sources.r1.selector.mapping.CZ = c1
#state值为US的走channel c2
a1.sources.r1.selector.mapping.US = c2
#state值为其他的走channel c4
a1.sources.r1.selector.default = c4
举个例子
# netcat source ---> memory channel -->
# kafka_sink hdfs_sink
# Name the components on this agent
a1.sources = r1
#a1.sinks = kafka_sink hdfs_sink1 hdfs_sink2
a1.sinks = hdfs_sink0 hdfs_sink1 hdfs_sink2
a1.channels = c0 c1 c2
# Describe/configure the source
a1.sources.r1.type=http
a1.sources.r1.bind=hive
a1.sources.r1.port=50000
a1.sources.r1.channels= c0 c1 c2
# Describe the sink
# a1.sinks.kafka_sink
a1.sinks.hdfs_sink0.type = hdfs
a1.sinks.hdfs_sink0.hdfs.path = /flume/events0/%Y-%m-%d
a1.sinks.hdfs_sink0.hdfs.useLocalTimeStamp = true
a1.sinks.hdfs_sink0.hdfs.fileType = DataStream
a1.sinks.hdfs_sink0.hdfs.rollInterval = 0
a1.sinks.hdfs_sink0.hdfs.rollSize = 102400
a1.sinks.hdfs_sink0.hdfs.rollCount = 0
a1.sinks.hdfs_sink1.type = hdfs
a1.sinks.hdfs_sink1.hdfs.path = /flume/events1/%Y-%m-%d
a1.sinks.hdfs_sink1.hdfs.useLocalTimeStamp = true
a1.sinks.hdfs_sink1.hdfs.fileType = DataStream
a1.sinks.hdfs_sink1.hdfs.rollInterval = 0
a1.sinks.hdfs_sink1.hdfs.rollSize = 102400
a1.sinks.hdfs_sink1.hdfs.rollCount = 0
a1.sinks.hdfs_sink2.type = hdfs
a1.sinks.hdfs_sink2.hdfs.path = /flume/events2/%Y-%m-%d
a1.sinks.hdfs_sink2.hdfs.useLocalTimeStamp = true
a1.sinks.hdfs_sink2.hdfs.fileType = DataStream
a1.sinks.hdfs_sink2.hdfs.rollInterval = 0
a1.sinks.hdfs_sink2.hdfs.rollSize = 102400
a1.sinks.hdfs_sink2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a1.channels.c0.type = memory
a1.channels.c0.capacity = 1000
a1.channels.c0.transactionCapacity = 100
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sinks.hdfs_sink0.channel = c0
a1.sinks.hdfs_sink1.channel = c1
a1.sinks.hdfs_sink2.channel = c2
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = State
a1.sources.r1.selector.mapping.CA = c0
a1.sources.r1.selector.mapping.AZ = c1
a1.sources.r1.selector.mapping.NY = c2
a1.sources.r1.selector.default = c1
这一篇博文是【大数据技术●降龙十八掌】系列文章的其中一篇,点击查看目录:















 454
454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









