







Learning to Rank(LTR)
声明:
本文主要参考Learning to Rank 简介、Learning to Rank小结文章。
另参考李航老师A short introduction to learning to rank一文。
对以上文章有较多引用,在此对原作者表示感谢!
刚刚接触排序学习,很多问题尚不清楚,在努力学习中,如有错误欢迎指出。本文也会不断改进、完善。
更欢迎就排序学习相关问题进行讨论。
摘要
排序学习是在处理排序问题时采用机器学习方法来训练模型的方法。排序学习可以应用在信息检索、自然语言处理、数据挖掘等方面。本文对排序学习做了一个简单的介绍,对基本问题和已经存在的方法进行简单说明,并描述了一些基于SVM技术的排序学习方法。
关键词: 排序学习,信息检索,自然语言处理,SVM
背景
排序学习可以在信息检索(IR)、自然语言处理(NLP)和数据挖掘(DM)等领域被广泛使用。典型应用有文献检索、专家检索系统、定义查询系统、协同过滤、问答系统、关键词提取、文档摘要还有机器翻译等。
在传统搜索引擎的排序策略中,一般会包含若干子策略,子策略通过若干种方式组合成更大的策略一起发挥作用。策略的组合方式以及参数一般采取人工或者半人工的方式确定,不使用机器学习策略或仅对少量参数进行学习。随着策略的逐步细化,传统的方式变得越来越困难。
近期文献检索方面,特别是在互联网搜索方面的一个新趋势,是使用机器学习方法去自动的建立评价模型 f(q,d) 。这是因为一系列事实而产生的动机。在互联网搜索方面,有许多标识可以代表相关性,例如,网页的链接文本和PageRank得分。在排序模型中将这些信息结合,并使用机器学习技术自动建立排序模型是一个自然而然的选择。在搜索引擎中,大量的搜索日志数据被保留,例如数据的点击。这使得通过搜索日志数据来进行训练并自动建立排序模型成为可能。事实上,排序学习已经成为了当今互联网搜索领域一个关键技术。
排序学习系统框架
排序学习是一个监督学习过程,排序学习包括训练和测试阶段(Fig. 1)。
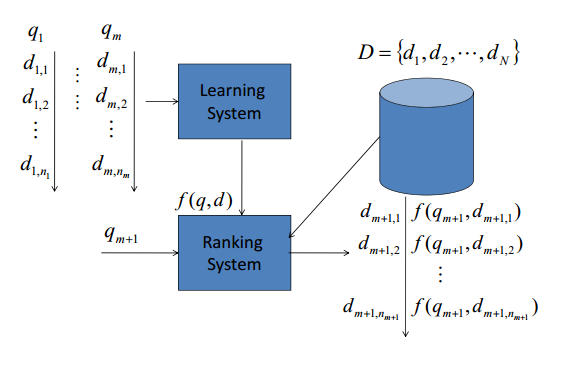
Fig. 1 信息检索的排序学习
对于标注训练集,选定LTR方法,确定损失函数,以最小化损失函数为目标进行优化即可得到排序模型的相关参数,这就是学习过程。预测过程将待预测结果输入学习得到的排序模型中,即可得到结果的相关得分,利用该得分进行排序即可得到待预测结果的最终顺序。
排序学习特征选择 [2]
与文本分类不同,LTR考虑的是给定查询的文档集合的排序。所以,LTR用到的特征不仅仅包含文档d本身的一些特征(比如是否是Spam)等,也包括文档d和给定查询q之间的相关度,以及文档在整个网络上的重要性(比如PageRank值等),亦即我们可以使用相关性排序模型和重要性排序模型的输出来作为L2R的特征。
1. 传统排序模型的输出,既包括相关性排序模型的输出 f(q,d) ,也包括重要性排序模型的输出。
2. 文档本身的一些特征,比如是否是Spam等。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









