






Hive简介和扩展设想
By云深作者:Alen/Adam 2009年6月
转载请注明出处
1. Hive是什么
- Hive是Data Warehouse,Hive不是基于传统数据库上的Data Warehouse,但它能处理的数据量往往比传统数据库要大得多,而且成本低廉。它的诞生就是Facebook需要一个D/W平台来处理日益庞大的日志数据。
- Hive使用Hadoop系统存储和分析处理数据,因为Hadoop系统是批处理系统,因此不能保证处理的低迟延(low latency)问题,只能在完成处理时发出通知;Hadoop能够处理非常巨大的数据量。而Oracle等数据库是基于相对较小的数据量实时处理查询。
2. Hive的架构
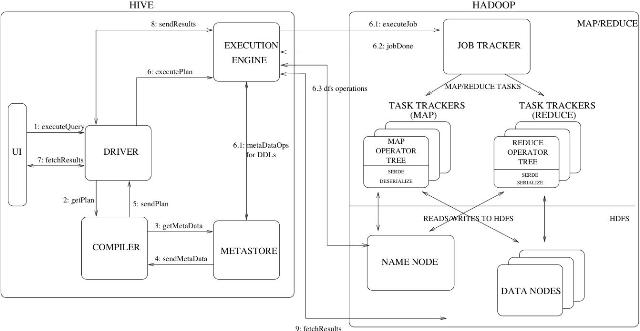
图1 Hive 架构(Hadoop 0.19.1)
Hive的总体结构如上图所示:
- UI:接收HQL和显示HQL的RESULT;
- DRIVER: 处理HQL的驱动模块;
- COMPILER:Parse HQL并转换为MapReduce Jobs;
- EXECUTION ENGINE:把MapReduce job提交给Hadoop系统,并等待Job的完成。
- METASTORE: 存储databases的meta 信息,如db name、table name、columns info、
Ser/DE classname、data path、partitions info和buckets info。
3. Hive的使用
1) 定义数据模型:
- db:默认的db名称为“default”。
- table:数据表,表中的数据是历史数据,所以是load进来的,不是动态地insert
进来的,也就是把整个数据文件copy或者mv到table的data path路径下。
- partition:分区,即把表中的数据分为几个partitions存放在不同的path路径下;
因为是data warehouse,所以partition一般根据时间段来划分,例如,把每一年
的数据放在一个独立的partition path路径下;
- bucket:根据columns把rows分类并存放在不同的文件中,例如,根据用户名称user_name把rows分开存放在32个不同的文件中,一般使用hash(user_name)来实现划分;
- 语法:
Create [External] table user_info (user_name string, subject string, mark int, teacher)
Partitioned by (dt string)
Clustered by (user_name) into 32 BUCKETS
Row format delimited Fields terminated by ‘/054’ Lines terminated by ‘/012’
[Location ‘<hdfs_location>’];
2) load数据
- 把数据文件load到table或者table partition;
- 语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)];
3) Select
- Select语句用来实现对数据的分析和查询,Select语句会被翻译为不同的MapReduce任务,然后调用Hadoop来完成select。
- 语法:
Select user_info.user_name, count(distinct user_info.teacher), sum(user_info.mark) from user_info group by user_info.user_name;
4) 处理结果
- INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] FROM from_statement select_statement1;
- INSERT OVERWRITE [LOCAL] DIRECTORY directory1 FROM from_statement select_statement1;
4. Hive的处理过程
举个实际的例子说明Hive如何利用Hadoop来处理Select 的。
Select user_info.user_name, count(distinct user_info.teacher), sum(user_info.mark) from user_info group by user_info.user_name;
用explain语句可以看到Select对应的MapReduce任务树:
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-2 depends on stages: Stage-1
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-1
Map Reduce
Alias -> Map Operator Tree:
user_info
Reduce Output Operator
key expressions:
expr: user_name
type: string
expr: teacher
type: string
# partition fields: 2147483647
tag: -1
value expressions:
expr: mark
type: string
Reduce Operator Tree:
Group By Operator
expr: sum(VALUE.0)
expr: count(DISTINCT KEY.1)
keys:
expr: KEY.0
type: string
mode: partial1
File Output Operator
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat
Stage: Stage-2
Map Reduce
Alias -> Map Operator Tree:
/tmp/hive-alen/110634916/990405419.10002
Reduce Output Operator
key expressions:
expr: 0
type: string
# partition fields: 1
tag: -1
value expressions:
expr: 1
type: string
expr: 2
type: string
Reduce Operator Tree:
Group By Operator
expr: sum(VALUE.0)
expr: count(VALUE.1)
keys:
expr: KEY.0
type: string
mode: partial2
Select Operator
expressions:
expr: 0
type: string
expr: 2
type: string
expr: 1
type: string
File Output Operator
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat
Stage: Stage-0
Fetch Operator
limit: -1
Hive把通过三个Stages来完成Select,Stage-1和Stage-2都是MapReduce Job;
Stage-1:
- Map: 从user_info的data path中读出data files,用user_info的Deserializer来分析rows并取出user_name,、teacher和mark三个columns的值,把这三个columns的值传送给Reducer;根据user_name和teacher来partition Map的结果。
- Reduce:根据Map送过来的user_name、teacher和mark计算出user_name、count(distinct teacher)和sum(mark);最后把结果保存在/tmp/hive-alen/110634916/990405419.10002目录下;
Stage-2:
- Map:从/tmp/hive-alen/110634916/990405419.10002目录中取出文件并Deserialize rows取出user_name作为key.0,sum(mark)作为value.0,count(distinct mark)作为value.1,把这三个值传送给Reducer;根据user_name来partition Map的结果。
- Reduce:根据Map传送过来的key.0,value.0和value.1计算出key.0, sum(value.0)和count(value.1);把最后的结果保存在预定的临时目录下;
Stage-0:
- 从Stage-2的保存的临时目录中读取结果文件并deserialize rows取出结果。
5. Hive的扩展设想
Hive最初是Facebook基于Hadoop为内部大规模日志数据处理提供的一个公共平台,贡献给Hadoop后,大家都对Hive发展成一个完整的强大的数据仓库和数据挖掘、分析平台有所期待。
关于一个完整的数据处理系统所具备的能力,Ben Fry在他的论文《COMPUTATIONAL INFORMATION DESIGN》中有较为详细分析和说明。另外,Michael Driscoll有一个比较概括性的说明,在“The Three Sexy Skills of Data Geeks”的论文中,他认为一个完整的数据处理系统需要具备三个方面的能力 (http://dataspora.com/blog/sexy-data-geeks/):
1. Statistics - traditional analysis you're used to thinking about
2. Data Munging - parsing, scraping, and formatting data
3. Visualization - graphs, tools, etc.
显然Hive离这个标准还有差距,当然它应该也是Hive扩展的重要方向:
1、 可视化:Hive现有的可视化UI还处在字符终端阶段,使用的用户也比较专业,面向不同的应用,提供个性化的可视化展现,是Hive进行扩展的一个重要方向;好在这个方面有很多开源项目可以集成…
2、 数据的预处理:Hive目前的设计,强调基于MapReduce的并行处理框架,实现面向大规模数据的后置处理,而对数据的前置处理(预处理)支持的比较简单,这使得Hive针对一个特定的应用时,往往表现为对数据预处理不充分,用户体验不理想,后置处理的负荷过重,重复性的后置处理浪费了大量的系统计算资源;如果Hive在数据预处理方面实现平台化,用户就可以根据自己的数据特点,定制相应的预处理能力,将数据的前置处理效果充分的发挥出来。
3、 丰富的数据分析能力:除常用的数据挖掘算法外,像类似 R Project这样的项目,相信在Google,Facebook这样的公司也会得到使用,集成这样的子系统,Hive的数据处理能力会更强。
4、 . . .















 350
350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









