






hadoop集群的组成
-
HDFS集群(一主三从配秘书) 解决海量数据存储
主角色:NameNode
主角色的辅助角色:SecondaryNameNode
从角色:DataNode -
YARN集群(一主三从) 资源管理、调度
主角色:ResourceManager
从角色:NodeManager -
MapReduce 解决海量数据计算
hadoop常用端口
-
外部URL
-
访问HDFS文件系统:9870
-
访问YARN资源调度:8088
-
访问历史MR计算日志:19888
-
内部通信端口
-
HDFS集群的连接端口:8020
HDFS常用shell命令
ls命令 显示文件列表
hadoop fs -ls / # 显示文件列表
hadoop fs -ls -R / # 等同于hdfs dfs -ls -R / 递归(-R)显示问价按列表
hdfs dfs -ls file:/// # 访问linux的根目录文件
mkdir命令 创建文件夹
hadoop fs -mkdir /dir1 # 创建文件
hadoop fs -mkdir -p /aaa/bbb/ccc # 递归创建目录
touch命令 创建文件
hadoop fs -touch /文件名
put命令将源数据srcs从本地文件系统上传到目标文件系统中
hadoop fs -put /root/1.txt(源文件) /dir1(目标文件夹) # 上传文件
hadoop fs -put /root/dir2 / # 上传目录
get命令 拷贝
hadoop fs -get /HDFS文件路径 /本地路径 # 将HDFS文件拷贝到本地文件系统
mv命令 移动
hadoop fs -mv /dir1/1.txt(源路径) /dir2(目标路径) # 将hdfs上的文件从原路径移动到目标路径
rm命令 删除
hadoop fs -rm /文件名 # 删除文件
hadoop fs -rm -r /dir2 # 删除目录
(rm -rf 删除全部数据 等于直接把数据全删掉 工作学习都注意不要用!!!! 谁让你用直接打死它!!)
cp命令 拷贝
hadoop fs -cp /dir1/1.txt(源路径) /dir2(目标路径) # 将文件拷贝到目标路径中
cat命令 输出/查看
hadoop fs -cat /dir1/1.txt # 将参数所指示的文件内容输出到控制台
appendToFile 追加内容
hadoop fs -appendToFile a.txt /目标文件(txt等) # 将a.txt的内容追加到目标文件
帮助文档
hadoop -h 或 hdfs -h
HDFS的原理、机制
块和副本
1.block块 HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件拆分成一系列的数据块进行存储,这个数据块被称为block,除了最后一个,所有的数据块都是同样大小的
2.block块大小 默认:128M(134217728字节) 为了容错,文件的所有block都会有副本。每个文件的数据块大小和副本系数都是可配置的。
3.副本数 默认:3个 副本好处:副本为了保证数据安全(用消耗存储资源方式保证安全,导致了大数据瓶颈是数据存储)
edits和fsimage文件
edits文件
NameNode基于一批edits和一个fsimage文件的配合完成整个文件系统的管理和维护
edits文件,是一个流水账文件,记录了hdfs中的每一次操作,以及本次操作影响的文件其对应的block
将全部的edits文件,合并为最终结果,即可得到一个FSImage文件
如当前没有fsimage文件,将全部edits合并为第一个fsimage文件
如当前已存在fsimage文件,将全部edits和已存在的fsimage进行合并,形成新的fsimage
SecondaryNameNode辅助合并元数据:
SecondaryNameNode会定期从NameNode拉取数据(edits和fsimage)然后合并完成后提供给NameNode使用。
HDFS的三大机制
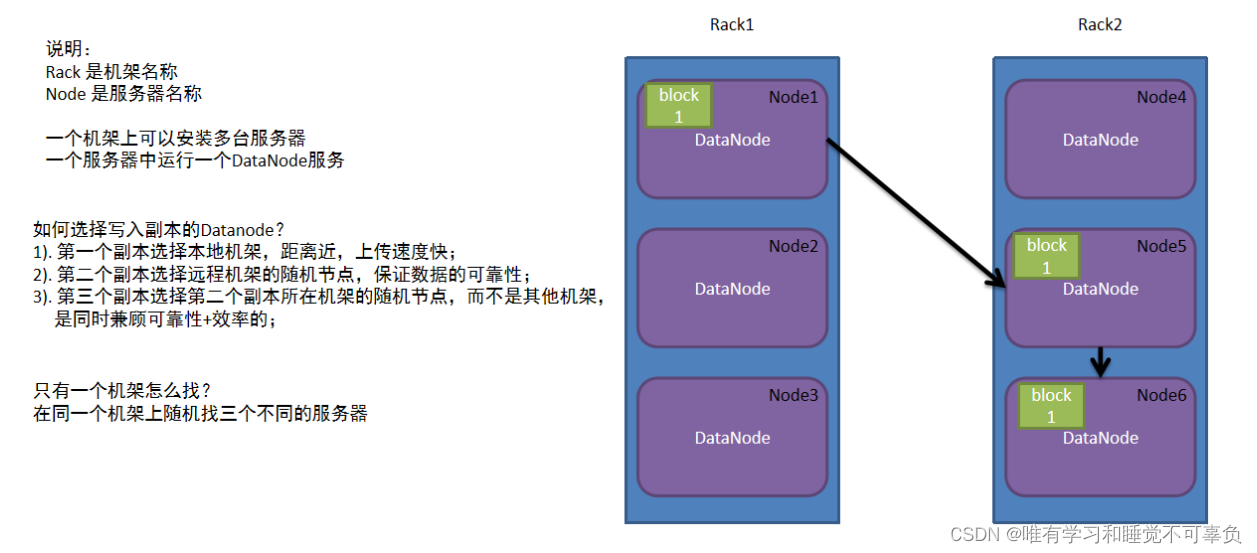
- 副本机制
为了保证数据安全和效率,block块信息存储多个副本,第一个副本保存在客户端所在服务器,第二副本保存在和第一个副本不同机架服务器上,第三副本保存在和第二副本相同机架不同服务器上
- 负载均衡机制
NameNode为了保证不同的DataNode中block块信息大体一样,分配存储任务的时候会优先保存在余量比较大的DataNode上
- 心跳机制
DataNode每隔3秒向NameNode汇报自己的状态信息,如果某个时刻,DataNode连续10次不汇报了,NameNode会认为DataNode有可能宕机了,NameNode就会每5分钟发送一次确认消息,连续2次没有收到回复,就认定DataNode此时一定宕机了
机架感知机制
HDFS数据上传、写入原理(写流程) 【重点】
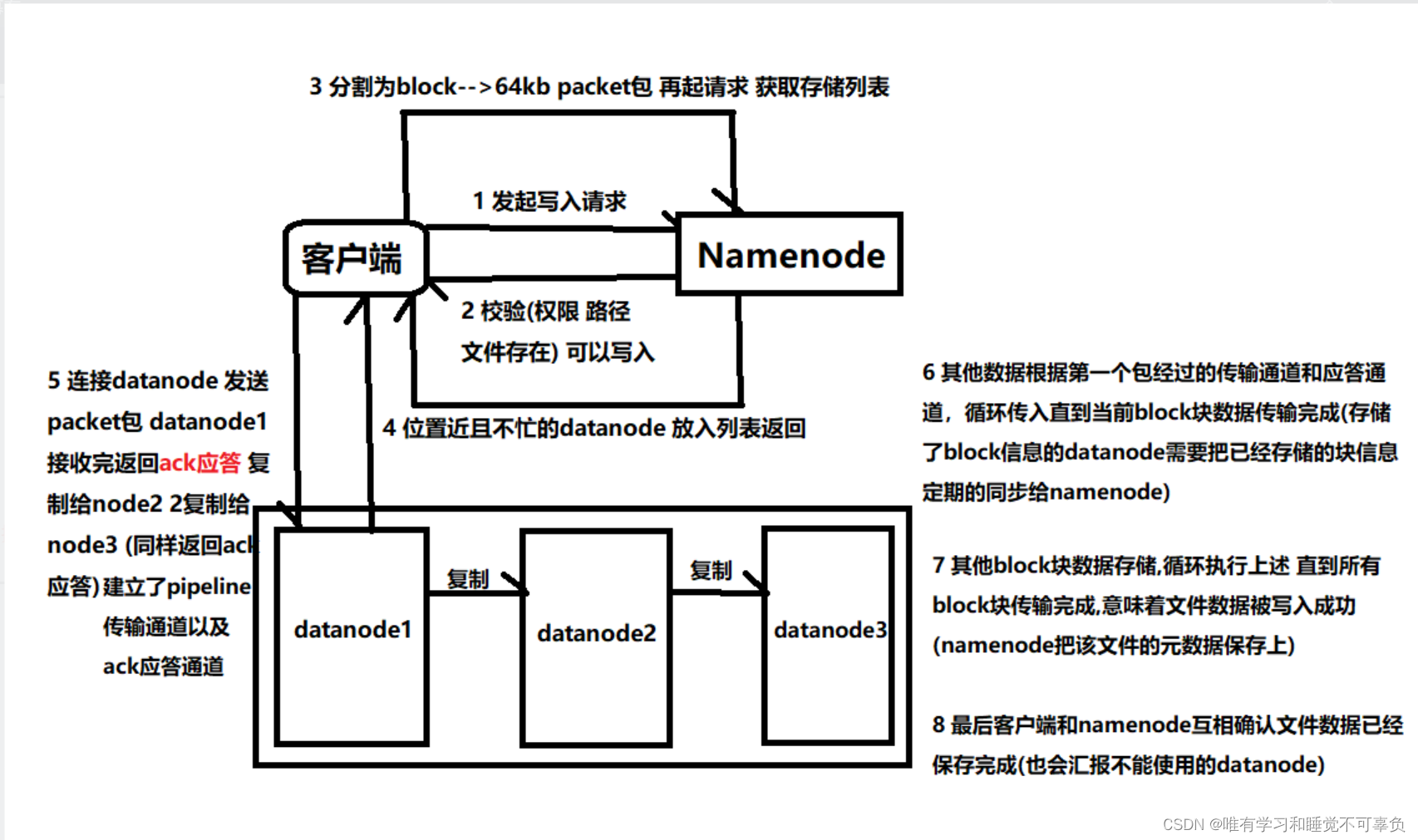
- 客户端发送写入数据请求给NameNode
- NameNode接收到客户端请求,开始校验(是否有有权限、文件路径是否存在、文件是否存在等),如果校验没有问题,就告知客户端可以写入
- 客户端收到消息,开始把文件数据分割成默认的128M大小的block块,并且把block块数据拆分成64kb的packet数据包,放入传输序列
- 客户端携带block块信息再次向NameNode发送请求,获取能够存储block块数据的DataNode列表
- NameNode查看当前距离上传位置近且不忙的DataNode,放入列表中返回给客户端
- 客户端连接DataNode,开始发送packet数据包,第一个DataNode接收完后就给客户端返回ack应答(客户端可以传入下一个packet数据包),同时第一个DataNode开始复制刚才接收到的数据包给node2,node2接收到数据包也赋值给node3(复制成功也需要返回ack应答),最终建立了pipeline传输通道以及ack应答通道
- 其他packet数据根据第一个packet数据包经过的传输通道和应答通道,循环传入packet, 直到当前block块数据传输完成(存储了block信息的DataNode需要把已经存储的块信息定期的同步给NameNode)
- 其他block块数据存储,循环执行上述4-7步,直到所有block块传输完成,意味着文件数据被写入成功(NameNode把该文件的原数据保存上)
- 最后客户端和NameNode互相确定文件数据已经保存完成(也会汇报不能使用的DataNode)
HDFS数据读取(读流程) 【重点】
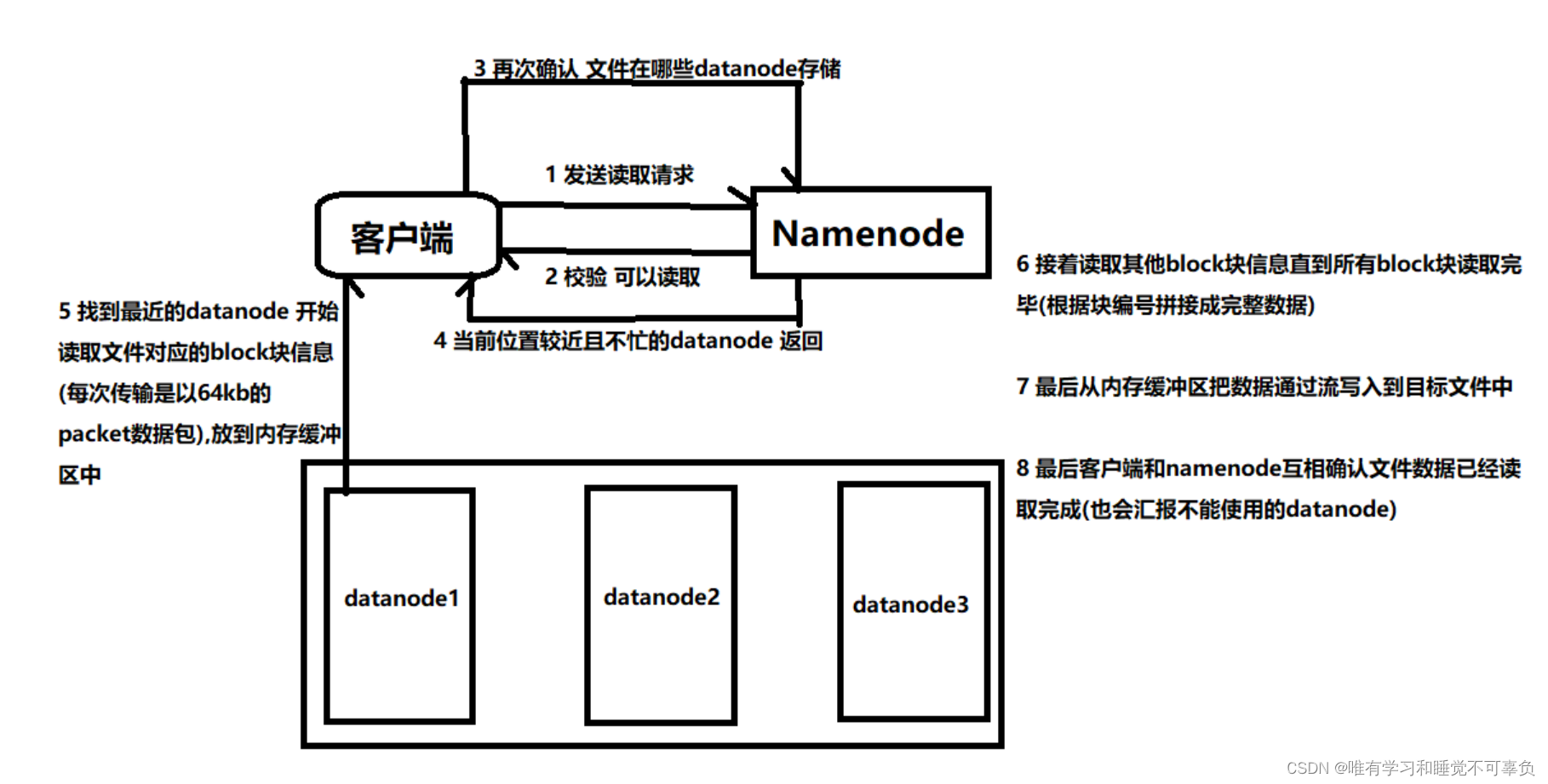
- 客户端发送读取文件请求给NameNode
- NameNode接收到客户端请求,开始校验(是否有有权限、文件路径是否存在、文件是否存在等),如果校验没有问题,就告知客户端可以读取
- 客户端需要再次和NameNode确认当前文件在哪些DataNode中存储
- NameNode查看当前距离下载位置较近且不忙的DataNode,放入列表中放回给客户端
- 客户端找到最近的DataNode开始读取文件对应的block块信息(每次传输是以64kb的packet数据包,放到内存缓冲区中)
- 接着读取其他block块信息,循环上述3-5步,直到所有block块读取完毕(根据块编号拼接成完整数据)
- 最后从内存缓冲区把数据通过流写入到目标文件中
- 最后客户端和NameNode互相确认文件数据已经读取完成(也会汇报不能使用的DataNode)
原数据存储流程 【重点】
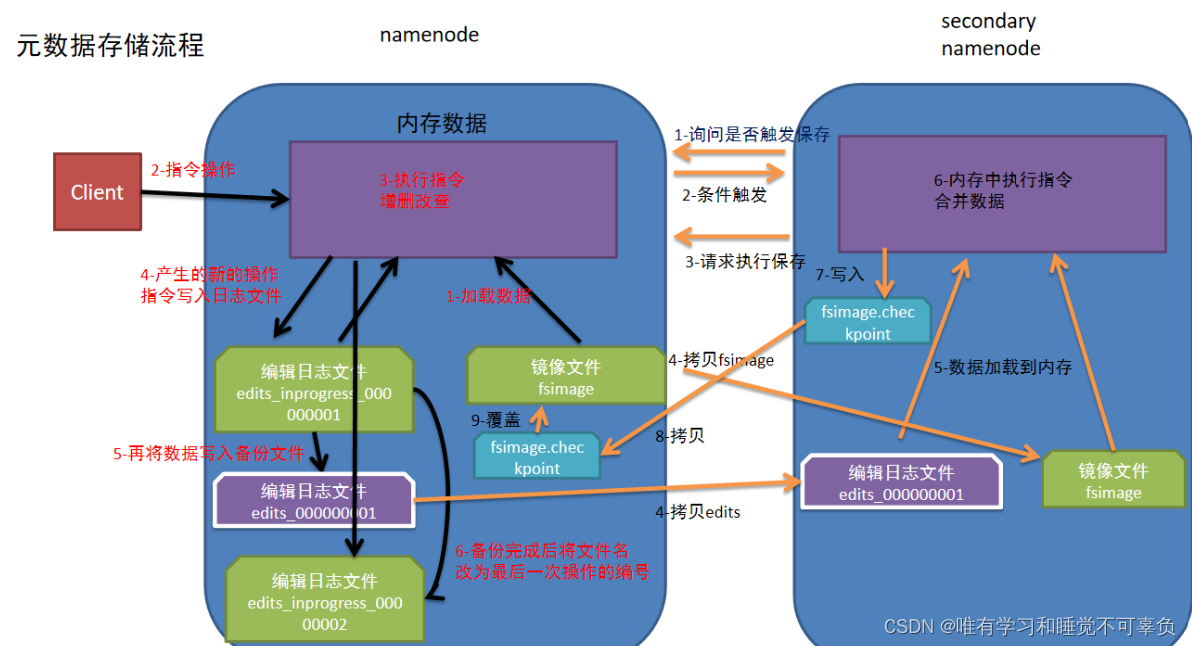
- NameNode第一次启动的时候先把最新的fsimage文件中内容加载到内存中,同时把edits文件中内容也加载到内存中
- 客户端发起指令(增删改查等操作),NameNode接收到客户端指令把每次产生的新的指令操作先放到内存中
- 然后把刚才内存中新的指令操作写入到edits_inprogress文件中
- edits_inprogress文件中数据到了一定阈值的时候,把文件中历史操作记录写入到序列化的edits备份文件中
- NameNode就在上述2-4步中循环操作···
- 当SecondaryNameNode检测到自己距离上一次检查点(checkpoint)已经1小时或者事务数达到100w,就触发SecondaryNameNode询问NameNode是否对edits文件和fsimage文件进行合并操作
- NameNode告知可以进行hebing
- SecondaryNameNode将NameNode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行合并(这个过程叫checkpoint)
- SecondaryNameNode把刚才合并后的fsimage.checkpoint文件拷贝给NameNode
- NameNode把拷贝过来的最新的fsimage.checkpoint文件,重命名为fsimage,覆盖原来的文件
安全模式
不允许HDFS客户端进行任何修改文件的操作,包括上传文件,删除文件等操作
#查看安全模式状态:
[root@node1 /] hdfs dfsadmin -safemode get
Safe mode is OFF
#开启安全模式:
[root@node1 /] hdfs dfsadmin -safemode enter
Safe mode is ON
#退出安全模式:
[root@node1 /] hdfs dfsadmin -safemode leave
Safe mode is OFF
归档机制(小文件)
归档原因:每个小文件单独存放到hdfs中(占用一个block块),那么hdfs就需要以此存储每个小文件的元数据信息,相对来说浪费资源
归档格式:hadoop archive -archiveName 归档名.har -p 原始文件的目录 归档文件的存储目录
归档特性:
- Hadoop Archives的URL是:har://scheme-hostname:port/路径/归档名.har
- scheme-hostname格式为hdfs-域名:端口
- 如果没有提供scheme-hostname,它会使用默认的文件系统:har:///路径/归档名.har
垃圾桶机制
- 在虚拟机中rm命令删除文件,默认是永久删除
- 在虚拟机中需要手动设置才能使用垃圾桶回收:把删除的内容放到
/user/root/.Trash/Current/- 先关闭服务,在node1中执行
stop-all.sh,新版本不关闭服务也没有问题。- 再修改文件
core-site.xml。进入/export/server/hadoop-3.3.0/etc/hadoop目录下进行修改。
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
# 其中,1440 表示 1440分钟,也就是 24小时,一天的时间
设置了垃圾桶机制好处:文件不会立刻消失,可以去垃圾桶里把文件恢复,继续使用
# 没有开启垃圾桶效果
[root@node1 hadoop]# hdfs dfs -rm /binzi/hello.txt
Deleted /binzi/hello.txt
# 开启垃圾桶
[root@node1 ~]#cd /export/server/hadoop-3.3.0/etc/hadoop
[root@node1 hadoop]# vim core-site.xml
# 注意: 放到<configuration>内容</configuration>中间
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
# 开启垃圾桶效果
[root@node1 hadoop]# hdfs dfs -rm -r /test1.har
2023-05-24 15:07:33,470 INFO fs.TrashPolicyDefault: Moved: 'hdfs://node1.itcast.cn:8020/test1.har' to trash at: hdfs://node1.itcast.cn:8020/user/root/.Trash/Current/test1.har
# 开启垃圾桶后并没有真正删除,还可以恢复
[root@node1 hadoop]# hdfs dfs -mv /user/root/.Trash/Current/test1.har /
MapReduce底层原理 【重点】
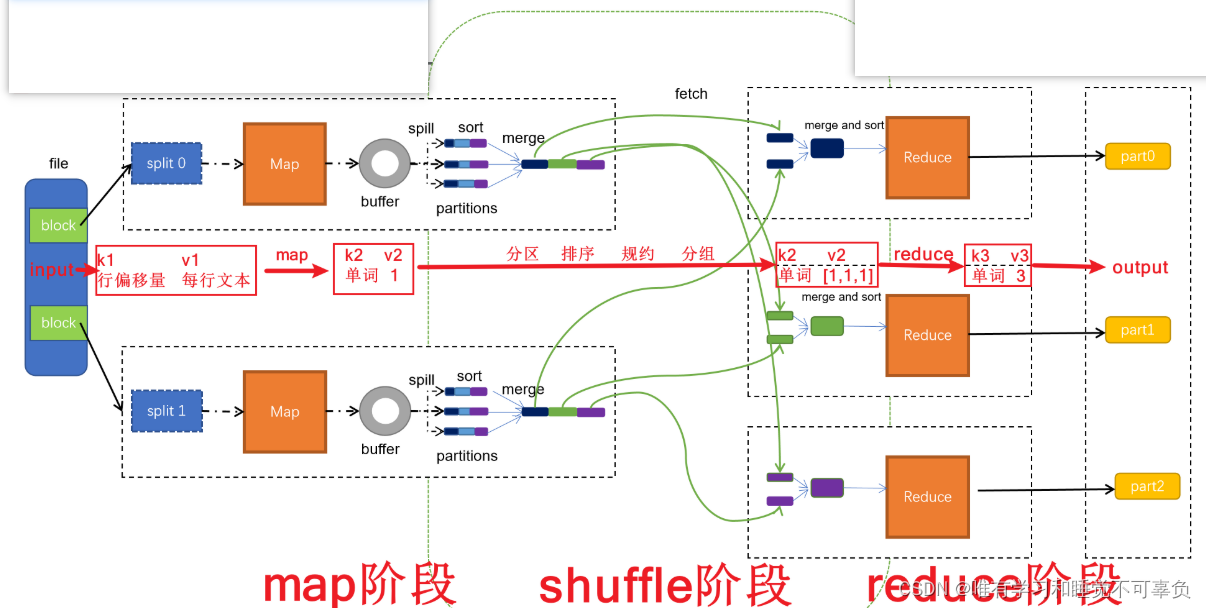
map阶段
第一阶段:把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认情况下split size 等于 Block size。每一个切片由一个MapTask处理(当然也可以通过参数单独修改split大小)
第二阶段:是对切片中的数据按照一定的规则解析成对,默认规则是把每一行文本内容解析成键值对。key是每一行的起始位置(单位是字节),value是本行的文本内容.(TextInputFormat)
第三阶段:是调用Mapper类中的map方法。上阶段中中每解析出来的一个。调用一次map方法。每次调用map方法会输出零个或多个键值对
第四阶段:按照一定的规则对第三阶段输出的键值对进行分区。默认是只有一个分区。分区的数量就是Reducer任务运行的数量。默认只有一个Reducer任务
第五阶段:对每个分区中的键值对进行排序。首先,按照键值对进行排序,对于键相同的键值对,按照值进行排序。比如三个<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。
如果有第六阶段,那么进入第六阶段;如果没有,直接输出到文件中
第六阶段:是对数据进行局部聚合处理,也就是combiner处理。键相等的键值对会调用一次reduce方法。经过这一阶段,数据量会减少,本阶段默认是没有的
shuffle阶段
shuffle是MapReduce的核心,它分布在MapReduce的map阶段和Reduce阶段。一般把从map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle
collect(收集)阶段:将maptask的结果输出到默认大小为100M的环形缓冲区,保存的是key/value,partition分区信息等
spill(溢出)阶段:当内存中的数量达到一定的阈值(80%)的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序
merge(合并)阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件
Copy(复制)阶段:ReduceTask启动Fetcher线程到已经完成mapTask的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阈值的时候,就会将数据写到磁盘上
merge(合并)阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作
sort(排序)阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可
reduce阶段
第一阶段:是Reduce任务会主动从Mapper任务复制其输出的键值对。Mapper任务可能会有很多,因此Recucer会复制多个Mapper的输出
第二阶段:把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并的数据排序
第三阶段:对排序后的键值对调用reduce方法。键值对的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS文件中
YARN提交MR流程 【重点】
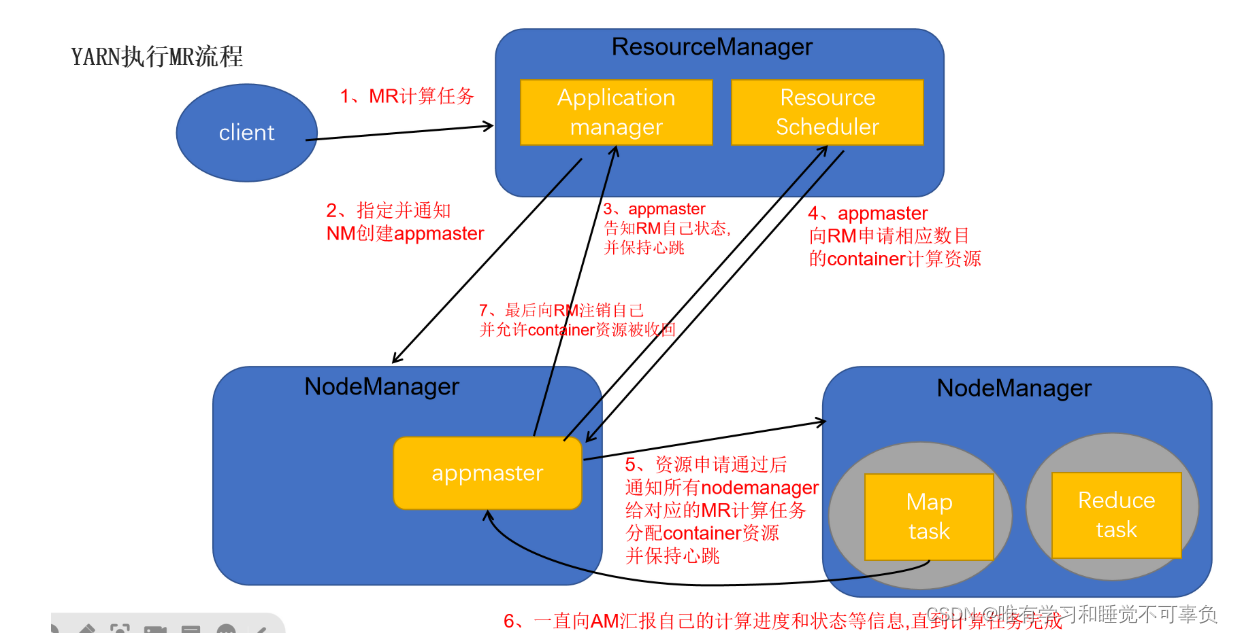
- 客户端提交一个MR程序给ResourceManager(校验请求是否合法···)
- 如果请求合法,ResourceManager随机选择一个NodeManager用于生成appmaster(应用程序控制者,每个应用程序都单独有一个appmaster)
- appmaster会主动向ResourceManager的应用管理器(applocation manager)注册自己,告知自己的状态信息,并且保持心跳
- appmaster会根据任务情况计算自己所需要的container资源(cpu,内存···),主动向ResourceManager的资源调度器(resource scheduler)申请并获取这些container资源
- appmaster获取到container资源后,把对应指令和container分发给其他NodeManager,让NodeManager启动task任务(maptask任务,reducetask任务)
- NodeManager要和appmaster保持心跳,把自己任务计算进度和状态信息等同步给appmaster,(注意当maptask任务完成后会通知appmaster,appmaster接到消息后会通知reducetask区maptask那儿拉取数据)直到最后任务完成
- appmaster会主动向ResourceManager注销自己(告知ResourceManager可以把自己的资源进行回收了,回收后自己就销毁了)
(舔狗之王appmaster) 自己突发的理解
作为‘舔狗之王的appmaster’ 自己负责和‘女神ResourceManager’有联系,但‘女神’的任务 ,让下面的‘狗小弟NodeManager’去做。任务做完‘狗小弟’交给‘狗王’,‘狗王’把结果献给‘女神’,然后狗王自己‘为爱而亡’
YARN的三大调度器
- 先进先出调度器
FIFO Scheduler:把应用按提交的顺序排成一个队列,在进行资源分配时,先给队伍中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推
好处:能够保证每一个任务都能够拿到充足的资源,对于大任务的运行非常有好处
弊端:如果有大任务后又小任务,会导致后续小任务无资源可用,长期处于等待状态
应用:测试环境
- 公平调度器
Fair Scheduler:不需要保留集群的资源,因为它会动态在所有正在运行的作业之间平衡资源,当一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源
当后面有小任务提交后,Fair调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源
好处:保证每个任务都有资源可用,不会有大量的任务等待在资源分配上
弊端:如果大任务非常多,会导致每个任务获取资源都非常的有限,也会导致执行时间会拉长
应用:CDH商业版本的hadoop
- 容量调度器
Capacity Scheduler:为每个组织分配专门的队列和一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。在每个队列内部,资源的调度是采用的是先进先出(FIFO)策略
好处:可以保证多个任务都可以使用一定的资源,提升资源的利用率
弊端:如果遇到非常大的任务,此任务不管运行在那个队列中,都无法使用到集群中所有的资源,导致大任务执行效率比较低,当任务比较繁忙的时候,依然会出现等待状态
应用:apache开源版本的hadoop
hive
metastore源数据服务配置的3种模式
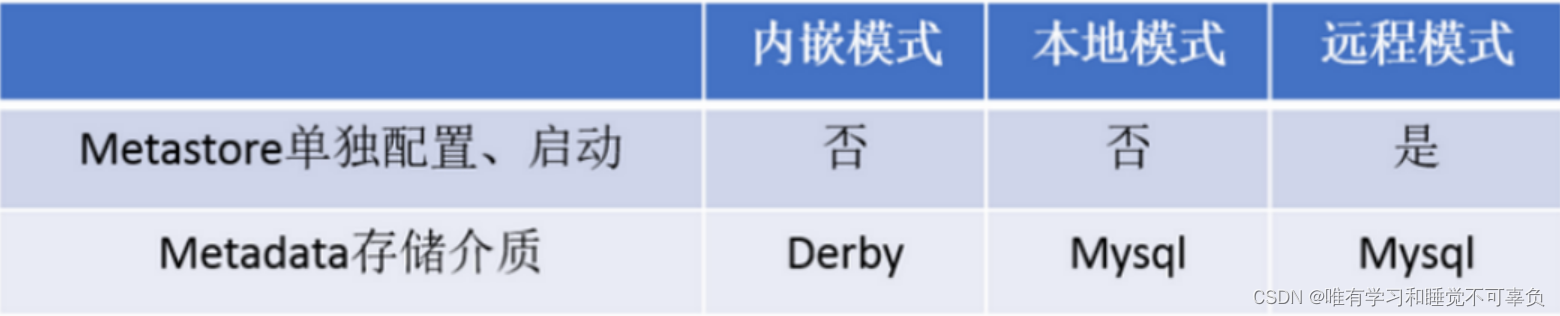
- 内嵌模式
优点:解压hive安装包 bin/hive 启动即可使用 自带的
缺点:不适用于生产环境,derby和metastore服务都嵌入在主Hive Server进程中,一个服务只能被一个客户端连接(如果用两个客户端以上都非常浪费资源),且源数据不能共享
- 本地模式
优点:可以单独使用外部的数据库(mysql),源数据共享
缺点:相对浪费资源,metastore嵌入到了hive进程中,每启动一次都要启动一个metastore服务
- 远程模式(常用)
优点:可以单独使用外部库(mysql),可以共享源数据,可以连接metastore服务也可以连接hiveserver2服务
缺点:需要注意的是如果想要启动hiveserver2服务需要先启动metastore服务
启动Hive metastore服务
启动Hive之前一定要先启动hadoop集群!!!!
# 后台启动metastore服务 前加nohup 后加&
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore &
# 此处还有前台启动方法 不在前加nohup 后加&即可 但是前台启动会占用客户端界面,无法继续后面的命令操作,不推荐使用,所以此处只介绍一下,不重要
netstat -naltp | grep 9083 # 检查端口占用
netstat -naltp | grep 10000 # 检查端口占用
# 后台启动日志在其他路径存储(不让其在根目录存储)
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore > /tmp/metastore.log &
启动Hiveserver2服务
在启动metastore服务后 如果要使用其他(如Beeline、datagrip)客户端工具
则需要额外启动一个hiveserver2服务
他们启动有先后顺序 先metastore服务后hiveserver2服务
# metastore服务后台启动
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore &
# hiveserver2服务后台启动
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 &
- hive第二代客户端Beeline连接Hive hive自带的客户端工具
- 需要注意hiveserver2服务启动之后需要稍等一会才可以对外提供服务
- Beeline是JDBC的客户端,通过JDBC协议和Hiveserver2服务进行通信,协议的地址是:jdbc:hive2://node1:10000
# 启动beeline
/export/server/hive/bin/beeline
# 通过beeline连接Hive服务
! connect jdbc:hive2://node1:10000
# 退出客户端
!quit 或 !exit
数据库和数据仓库【重点】
数据库和数据仓库区别
- 数据库
- OLTP 操作性处理,联机事务处理
- 针对具体业务在数据库联机的日常操作,通常进行增删改查操作
- 用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题
- 有索引、没有冗余
- 数据量小、效率高 如MySQL
- 数据仓库
- OLAP分析性处理 ,联机分析处理
- 通常进行查询分析操作
- 一般对某些主题的历史数据进行分析,支持管理决策
- 没有索引、支持冗余
- 数据量大,效率差 如数据仓库 主要用于数据分析
- 数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持
- 数据仓库本身并不”产生“任何数据,其数据来源于不同外部系统
- 同时数据仓库自身也不需要”消费“任何的数据,其结果开放给各个外部应用使用
数仓经典三层架构
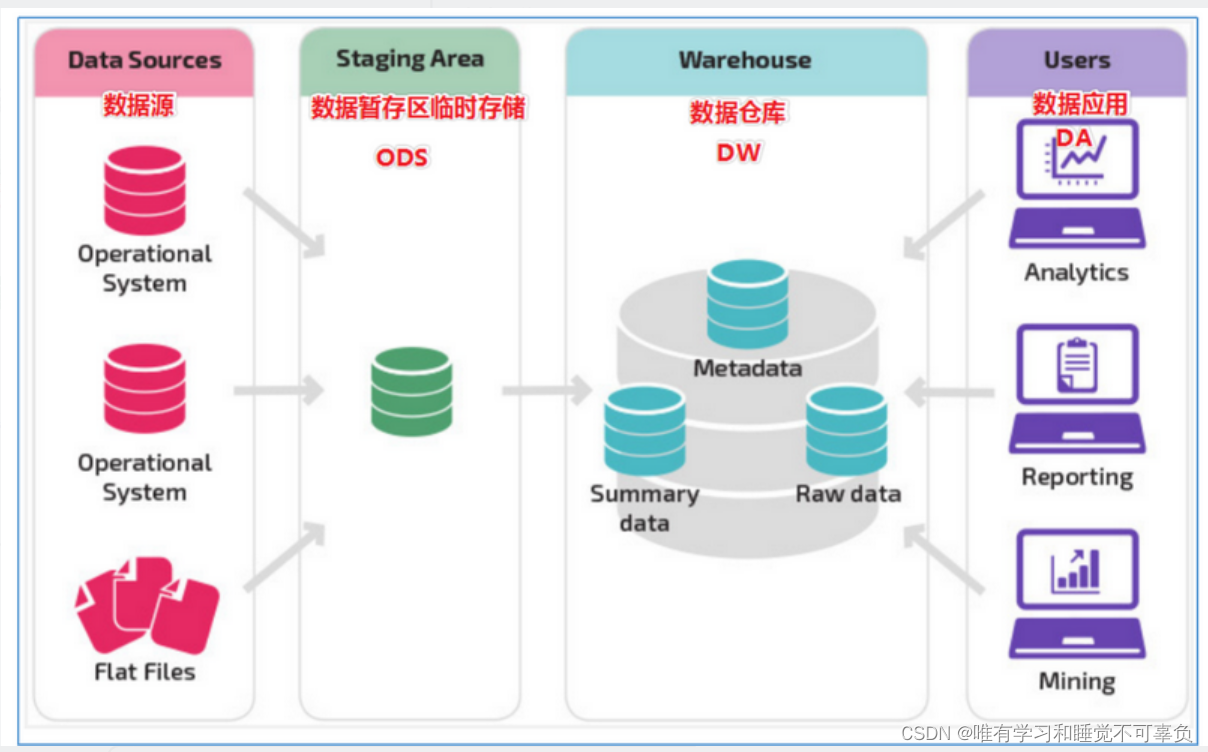
-
源数据层(ODS)
此层数据无任何更改,直接沿用外围系统数据结构和数据,不对外开放;为临时存储层,是接口数据的临时存储区域,为后一步的数据处理做准备 -
数据仓库层(DW)
也称为细节层,DW层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了清洗(去除了杂质)后的数据 -
数据应用层(DA)
前端应用直接读取的数据源;根据报表、专题分析需求而计算生成的数据
ETL 和 ELT
抽取Extra 转化Transfer 装载Load
ETL 抽取–>转换–>加载
ETL先从数据源池中抽取数据,数据保存在临时暂存数据库(ODS)。
然后执行转换操作,将数据结构化并转换为适合目标数据仓库系统的形式
然后将结构化数据加载到数据仓库中进行分析
ELT 抽取–>加载–>转换
ELT从数据源中抽取后立即加载,没有专门的临时数据库(ODS)
这意味着数据会立即加载到单一的集中存储库中,数据在数据仓库系统中直接进行转换,然后进行分析
表操作语法和数据类型 【重点】
内部表 和 外部表
- 内部表(create table 表名 ···)
未被external关键字修饰的即是内部表,内部表又称管理表或者托管表
可以创建分区表或者分桶表
删除内部表:直接删除元数据(metadata)和存储数据本身
元数据存储在关系型数据库中 数据存储在HDFS中
Hive管理表持久使用
# 创建内部表
create table [if not exists] 内部表名;
# 复制内部表
create table 表名 like 存在的表名; # 复制表结构
create table 表名 as select语句(select * from 被复制表名); # 复制表结构和数据
# 删除内部表
drop table 内部表名;
# 查看表格式化信息(详细信息)[内部表类型managed_table]
desc formatted 表名;
# truncate清空内部表数据
truncate table 内部表名;
- 外部表(create external table 表名···)
被external关键字修饰的即是外部表,外部表又称非管理表或者非托管表
可以创建分区表或者分桶表
删除外部表:仅仅是删除元数据(metadata),不会删除存储数据本身
临时链接外部数据使用
# 创建外部表
create external table [if not exists] 外部表名;
# 复制外部表
create table 表名 like 存在的表名;
#复制表结构和数据 as不可用
# 删除外部表
drop table 外部表名;
# 查看表结构化信息[外部表类型external_table]
desc formatted 表名;
外部表不能使用truncate关键字清空数据
数据库基本操作
# 创建数据库并指定HDFS存储位置
create database 库名 location '/存储路径'
# 删除一个空数据库 如果数据库下面有数据表 那么就会报错
drop database 库名;
# 删除有表的库
drop database 库名 cascade;
# 查看数据库详细信息
desc database 库名;
# 查看当前数据库
select current_database();
# 创建表语法
create [external] table [if not exists] 表名(
字段名1 类型1 约束1 注释1,
字段2 类型2 约束2 注释2
)partitioned by(分区字段名 分区字段类型) # 分区表
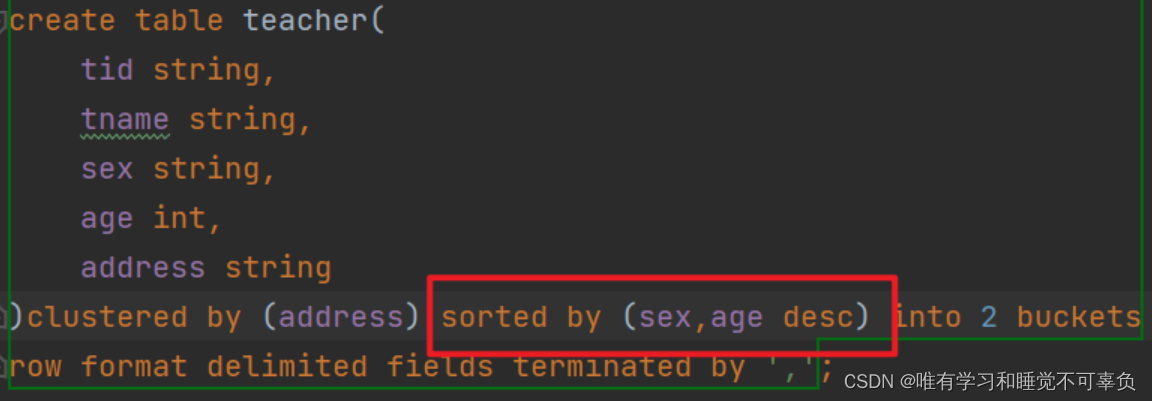
clustered by(分桶字段名) 【sorted by(字段 类型 ASC|DESC)】 into 3 buckets # 分桶表 sorted by为排序 与clustered by 配合使用同为分桶表
row format delimited fields terminated by ',' # 自定义字段分隔符固定格式
stored as textfile # 指定表的存储格式
location '/路径' # 指定了HDFS上的存储路径
tblpropepties(~~) # 设置表的源数据键值对
# 上述关键字顺序是从上到下 从左到右
查看表操作
show tables; # 查看所有表
show create table 表名; # 查看建表语句
desc 表名; # 查看表信息/结构信息
desc formatted 表名; # 查看表格式化信息
修改表操作
alter table 旧表名 rename to 新表名; # 修改表名
alter table 表名 set location 'hdfs中存储路径'; # 修改表路径
alter table 表名 set tblproperties('属性名'='属性值'); # 修改表属性(经常用于内外部表切换)
alter table 表名 add columns (字段名 字段类型); # 字段的添加
alter table 表名 replace columns (字段名 字段类型 , ...); # 字段的替换
alter table 表名 change 旧字段名 新字段名 新字段类型; # 字段名和字段类型同时修改
内外部表切换(通过stu set tblproperties来修改属性)
# 内部表转外部表
alter table 表名 set talproperties('EXTERNAL'='TRUE');
# 外部表转内部表
alter table 表名 set talproperties('EXTERNAL'='FALSE');
要注意:('EXTERNAL'='FALSE') 或 ('EXTERNAL'='TRUE')为固定写法,区分大小写!!! 必须大写!!!
快速映射表
# 创建表
create table table_name(
字段1 字段类型1,
字段2 字段类型2
)row format delimited fields terminated by ','; # 默认分隔符
# 加载数据【重点】
load data [local] inpath '数据文件路径' into table table_name;
# 省略local代表从hdfs中加载数据文件
# 基于HDFS进行load加载数据,源数据文件会消失(本质是被移动到表所在的目录中)
# 不省略local代表从linux本地加载数据
# 建表字段数量要和数据相对应
数据加载和导出
- 加载
local data [local] inpath '数据路径' [overwrite] into table 被加载表名;
# 使用local,数据不在HDFS,需使用file://协议指定路径
# 不使用local,数据在HDFS,可以使用HDFS://协议指定路径
# overwrite覆盖已存在数据
# 使用OVERWRITE进行覆盖
# 不使用OVERWRITE则不覆盖
#省略local代表从hdfs中加载数据文件基于HDFS进行load加载数据,源数据文件会消失(本质是被移动到表所在的目录中)
#不省略local代表从linux本地加载数据 本质上是在进行put上传命令
#当表中有数据时 不使用overwrite(覆盖) 重复使用加载数据 会让数据重复加载(有重复数据则重复)
insert [ overwrite | into ] table 表名 [partition
(···)[if not exists]] select语句;
# 通过sql语句 从其他表中加载数据
# 将SELECT查询语句的结果插入到其它表中,被SELECT查询的表可以是内部表或外部表
# 例子 insert into table tbl1 select * from tbl2;
#put命令 数据加载本质上是在进行put上传命令
hadoop fs -put /被加载文件目录 /加载到的文件路径
- 导出
insert overwrite [local] directory 数据文件存储路径(文件要导出到的路径) [指定分隔符] select语句(被导出表);
# 不加local导出则导出到HDFS上
# 例子 将查询的结果导出到本地 - 指定列分隔符
#insert overwrite local directory '/home/hadoop/export2' row format delimited fields terminated by ' ,' select * from test_load;
hive shell导出(linux)
# hive -f/-e 执行语句 >file
bin/hive -e "select * from myhive.test_load;" > /home/hs1.txt
# -e后面跟sql语句 一定要用引号
# myhive.test_load 一定要带上库名(myhive) test_load为表
# 语法(hive -f/-e 脚本 > file)
bin/hive -f export.sql > /home/hs2.txt
# export.sql 通过vim创建编辑 里面放select * from myhive.test_load语句
# 使用手册
hive -h -help --help
分区表 【重点】
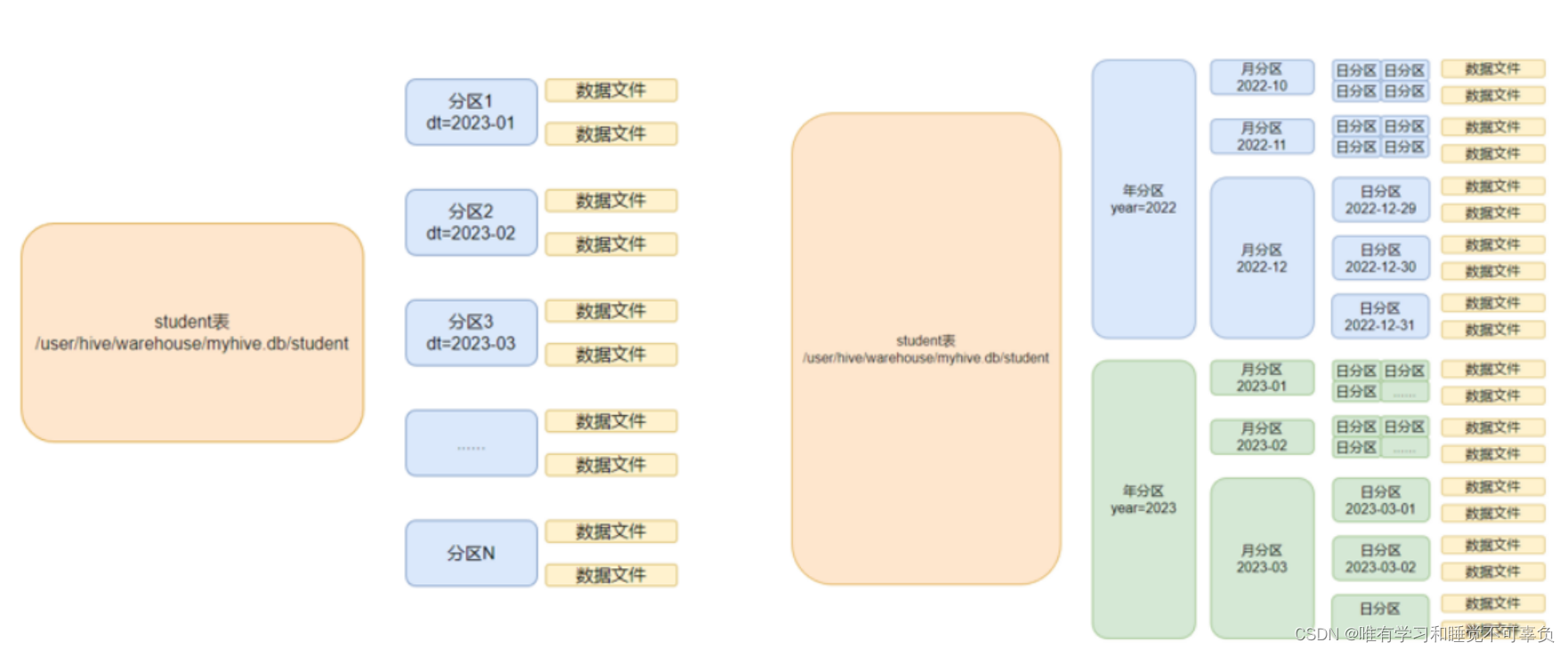
为什么要用分区表?
设想一下
你有很多的学习资料,全放在一个文件夹下也可以,但是按学科进行分类是不是在找的时候就更加的方便了
所以 分区表就是在分文件夹 方便查找 通过分区就可以找到目标数据 提高了效率
- 单分区
# 基本语法
create table table_name (
·····
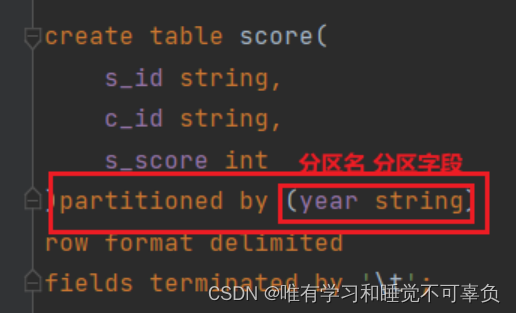
)partitioned by(分区名1 分区类型1) # 分区
row format delimited fields terminated by ',';
# 
# 加载数据到分区表中
load data [local] inpath '被加载数据路径' into table 加载到的表名 partition (分区名='值(与分区类型对应)');
# 
# 查询单分区
select * from 表名 where 分区名='查询值';
- 多分区
# 文件夹里嵌文件夹 年里放月 月里放日
# 基本语法
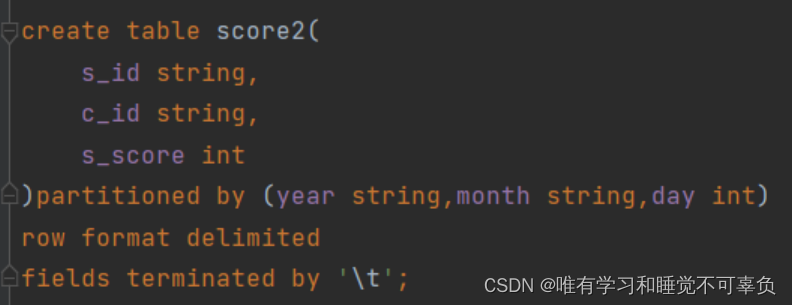
create table table_name(
·····
)partition by(分区名1 分区类型1,分区名2 分区类型2)
row format delimited fields terminated by ',';
# 
# 加载数据到多分区表中
load data [local] inpath '被加载数据路径' into table 加载到的表名 partition (分区名1='值1',分区名2='值2');
# 
# 查询多分区
select * from 表名 where 分区名1='查询值1' and 分区名2='查询值2';
- 分区表基本操作
# 查看分区
show partitions 表名;
# 添加分区
alter table 表名 add partition (分区名='值(与分区类型对应)')
#添加多个分区
alter table 表名 add partition (分区名='值(与分区类型对应)') partition (分区名='值(与分区类型对应)');
# 删除分区
alter table 表名 drop partition(分区名='值');
# 修改分区
alter table 表名 partition(被改分区名='被改分区值') rename to partition (改后的分区名='被改后的分区值')
# 拓展:修复分区:补充元数据信息
msck repair table table_name;
分桶表 【重点】
为什么要用分桶表?
抽样查询、提高查询效率、减少单个分区的数据量,提高系统性能
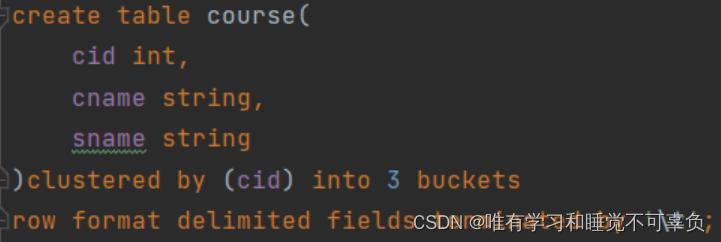
分桶的方式
对字段进行哈希取模(取余)
数据放在哪个桶计算方式:哈希的值/桶的数量
hash(如下语法中 clustered by 的cid)/3 取余数分桶0、1、2
# 语法
create table 表名 (
分区名1 分区类型1,···
) clustered by(分区名1用创建好的分区名 一般用id) into 3 buckets(桶)
row format delimited fields terminated by '\t';
# 
# 加载数据
load data inpath '加载表名路径' into table 被加载表名;
# 分桶的排序
create table 表名 (
分区名1 分区类型1,···
)clustered by(分区名1用创建好的分区名一般用id)
sorted by(分区名 ASC|DESC)
into 3 buckets(桶)
row format delimited fields terminated by '\t';
# 
分区和分桶的区别
本质不同
- 分区就是分文件夹
- 分桶就是分文件
数据导入不同
- 分区导入必须加上分区字段partition(字段=值)
- 分桶导入和普通导入语法一样 但是分桶会走MapReduce
复杂数据类型
- array复杂类型

集合/数组类型
主要存储:数组格式 保存一堆同类型的元素 如:1,2,3,4,5
# 建表语句
create table table_name(
name string,
work_locations array<string>
)row format delimited dields terminated by '\t'
collection items terminated by ','; # 集合的分隔符
# array<string>表示一个包含字符串元素的数组类型
# work_locations 列中的每个单元格都将包含一个字符串数组
# fields terminated by '\t' 表示列分隔符是\t
# collection items terminated by ',' 表示集合(array)元素的分隔符是逗号
常用array类型查询
# 查询work_locations数组中第一个元素
select 字段名[0] as work_locations from 表名;
# 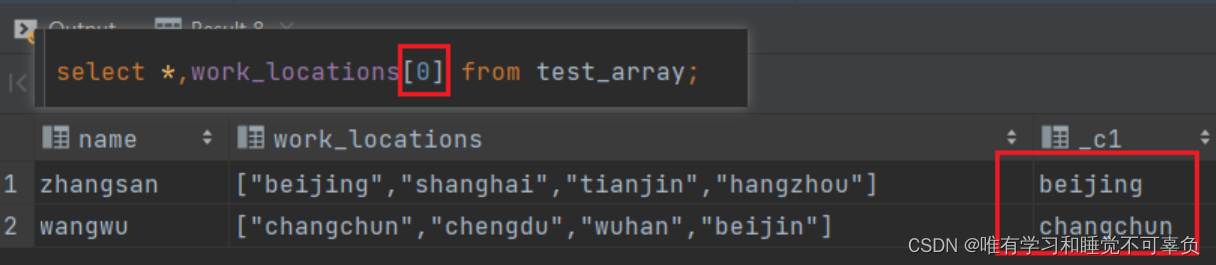
# 数组[数字序号],可以取出指定需要元素(从0开始)
# 用下标索引
# 查询work_locations数组中元素的个数
select size(work_locations) from 表名;
# 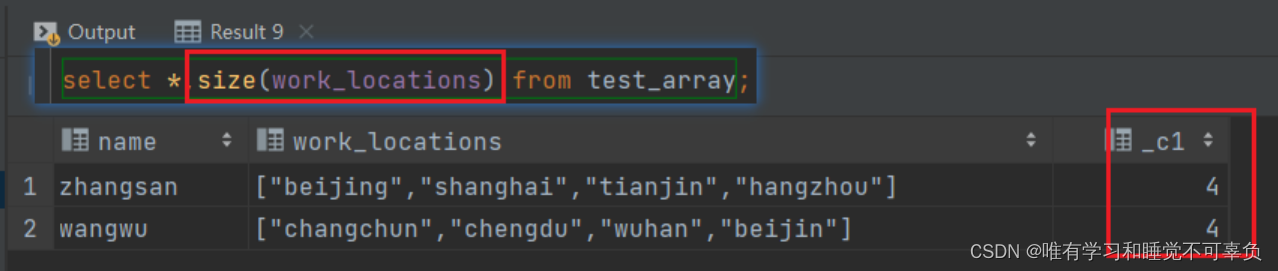
# size(数组),可以统计数组元素个数
# 查询work_locations数组中包含tianjin的信息
select * from myhive.test_array where array_contains(work_locations(array字段),'tianjin');
# 
- struct复杂类型

复合类型
主要存储:复合格式
可以在一个列中存入多个子列
每个子列允许设置类型和名称
可以包含多个二级列,二级列支持列名和类型
如“a”: 1, “b”: “foo”, “c”: “2000-01-01”
# 建表语句
create table myhive.test_struct(
id string,
info struct<name:string, age:int> # 复合类型
)row format delimited fields terminated by '#'
collection items terminated by ':';
# 定义格式:struct<name:string, age:int>
# struct的分隔符只需要:collection items terminated by '分隔符' 只需要分隔数据即可(数据中不记录key,key是建表定义的固定的)
# 查询
# 直接使用列名.子列名 即可从struct中取出子列查询
select ip, info.name(struct的字段.键keys) from hive_struct;
- map复杂类型

Key-Value型数据格式(键值对)
保存一堆同类型的键值对
# 建表语句
create table myhive.test_map(
id int, name string,
members map<string,string>,
age int
)row format delimited fields terminated by',' # 字段分隔符
collection items terminated by '#' # 字段/集合的分隔符
map keys terminated by ':'; # map集合内部k-v分隔符
# 定义格式:map<key类型, value类型>
# 不同键值对之间:collection items terminated by '分隔符' 分隔
# 一个键值对内,使用:map keys terminated by '分隔符' 分隔K-V
# 查询
# 查询father、mother这两个map的key
select id, name, members['father'] as father, members['mother'] as mother, age from myhive.test_map;
# 查询全部map的key,使用map_keys函数,结果是array类型
select id, name, map_keys(members) as relation from myhive.test_map;
# 查询全部map的value,使用map_values函数,结果是array类型
select id, name, map_values(members) as relation from myhive.test_map;
#查询map类型的KV对数量
select id,name,size(members) as num from myhive.test_map;
# 查询map的key中有brother的数据
select * from myhive.test_map where array_contains(map_keys(members), 'brother');
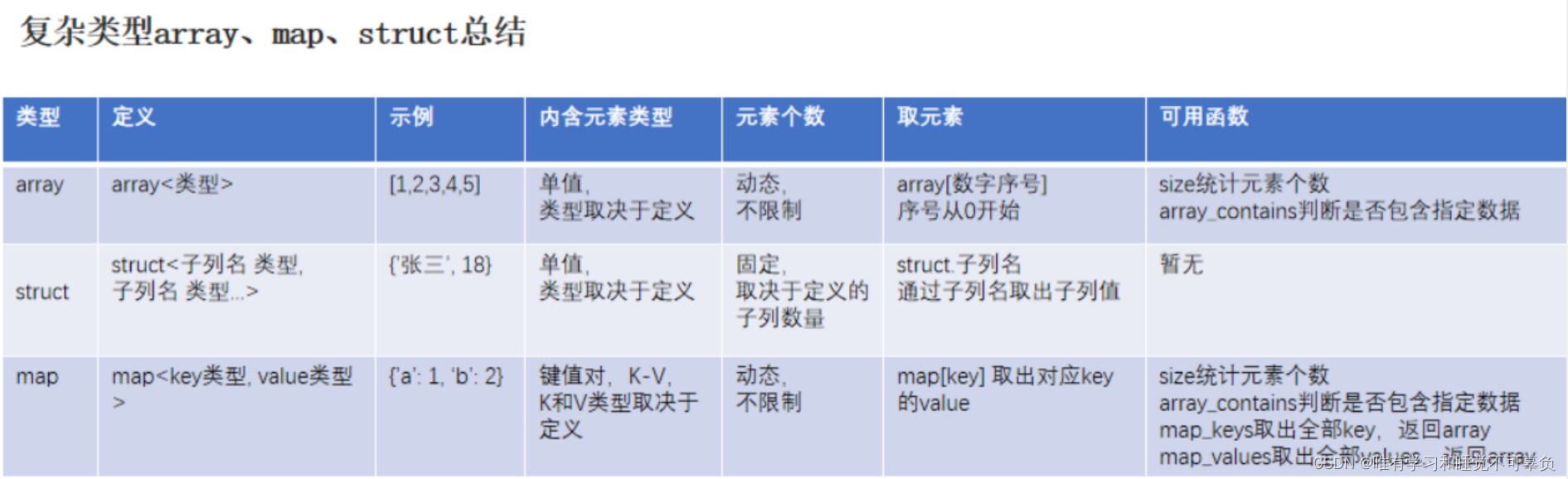
复杂数据类型array、map、struct总结
函数 【重点】
UDF分类标准的扩大化
-
UDF (User-Defined-Function):普通函数:一进一出,输出一行数据输出一行数据
-
UDAF (User-Dfined Aggregation Function) 聚合函数:多进一出,输入多行输出一行
-
UDTF (User-Defined Table-Generating Functions) 表生成函数:一进多出 输入一行输出多行
-
String Functions 字符串函数(部分)
select concat('a','b'); # 连接字符串
select concat_ws('!','a','b'); # 自定义连接符号
select length('fackbook'); # 字符串的长度
select lower('AbcDEFg'); # 全部转小写
select upper('AbcDEFg'); # 全部转大写
select trim(' ab '); # 从a的两端裁剪空格得到的字符串 去不掉中间的空格
select substr('fackbook',5); # 截取字符串
select split('apache,hadoop,hive',','); # 逗号代表前面的字符串中出现逗号的地方分割 例'h' [apac,e,adoop,ive] 有h则分割 不算h
- Date Functions 日期函数(部分)
select unix_timestamp(); # 获取当前UNIX时间戳函数
select unix_timestamp('2022-12-07 13:01:03'); # 日期转UNIX时间戳函数
select unix_timestamp('20221207 13:01:03','yyyyMMdd HH:mm:ss'); # 指定格式日期转UNIX时间戳函数
select from_unixtime(1620723323); # UNIX时间戳转日期函数
select current_timestamp(); # 返回当前时间戳
select current_date(); # 返回当前日期
select to_date(); # 时间戳转日期
- Mathematical Functions 数学函数(部分)
select round(3.1415926); # round取整
select round(3.1415926,3); # 设置小数精度
select floor(3.1415926) # 向下取整
select ceil(3.1415926); # 向上取整
select rand(); # 随机数(范围0-1)
- Conditional Functions条件函数(部分)
select isnull(null); # 判断参数是否为空
select isnotnull(null); # 判断参数是否为空
select nvl(null,2); # 如果值1为空,则返回默认值2,否则返回值1本身
select coalesce(a1,a2,a3,···); # 返回第一个不为空的值
# case when 条件判断
case when 条件1 then 值1
when 条件2 then 值2
when 条件3 then 值3
···
else 值n
end
- Type Conversion Functions类型转换函数(部分)
# 任意数据类型之间转换:cast
select cast(12.14 as string);
select cast("hello" as nit); # null
- Data Masking Functions数据脱敏函数(部分)
select mask('ABCdef123');
- Misc. Functions其它函数(部分)
# 返回参数的hash数字
select hash(1234);
# 返回当前登录用户/当前选择的数据库
select current_user();
select current_database();
- Collection Functions集合函数(部分)
# 返回array类型的元素个数
select size(array('1234','abc','123')); --> 3
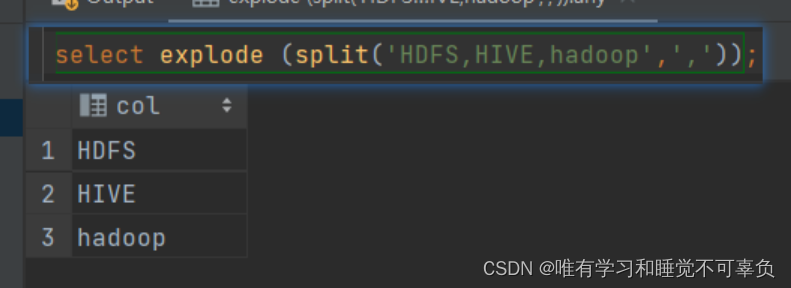
Hive高阶函数-explode炸裂函数 【重点】
表生成函数:接收map、array类型的参数,一般都是array类型。它的结果是一张表,所以他叫表生成函数
属于UDTF函数 输入一行数据输出多行数据
# 基本语法
Select explode (split('HDFS,HIVE,hadoop',','));
- Lateral view 侧视图
案例:
原始数据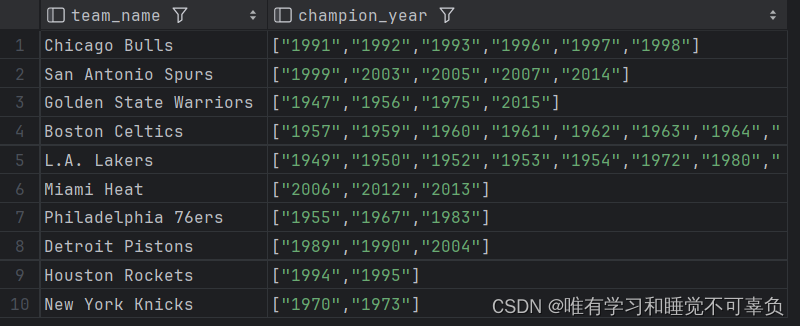
过程命令
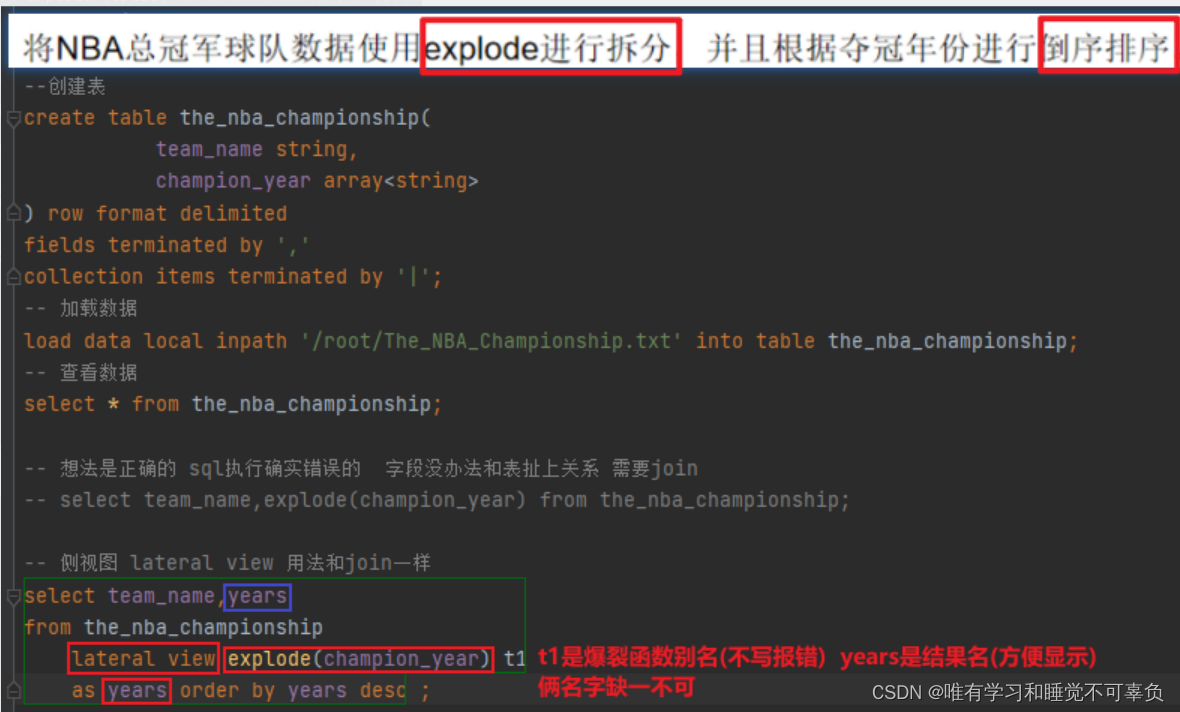
select team_name, years
from the_nba_championship
lateral view explode(champion_year) t1
as years
order by years desc;
最后结果
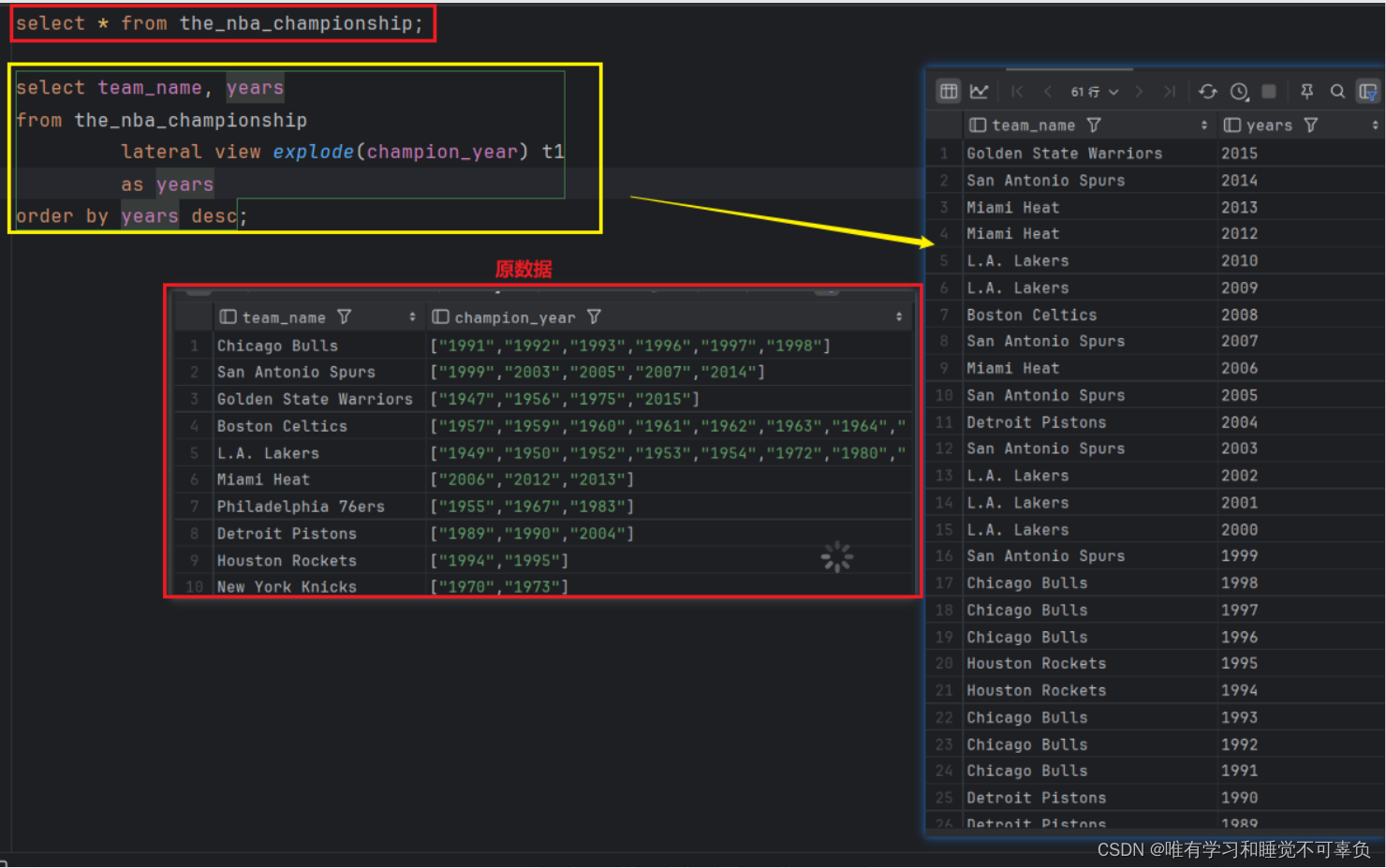
lateral view侧视图
基本语法
select ··· from tableA lateral view UDTF(xxx) 别名 as col1,col2,col3···;
select ··· from 原表 lateral view explode(字段) 别名 as 字段名;
本质上是在做join操作
能搭配其他UDTF类型函数使用
列转行 【重点】
# 列转行通过explode+split即可
select col1,col2,col from col2row2 lateral view explode(split(col3,',')) tmp as col;
思路:explode函数给它炸开!!!
模板:select a,b,c 字段别名 from 表 lateral view explode(字段) 别名 as 字段名
行转列 【重点】
select col1,col2,concat_ws('-',collect_list(cast(col3 as string))) from row2col2 group by col1, col2;
- collect_list/collect_set就是一个array(集合)类型
- concat/concat_ws,字符串拼接,可以是一个字符串或者一个array,要求这个array的数据类型是string
- cast函数 就是把col3数字转换为字符串的
- 思路: concat_ws结合collect_list或者collect_set使用
- 模板: select a,b concat_ws(‘连接符’,collect_list(字段)) from 表 group by a,b;
- 数据收集函数
collect_set --把多行数据收集为一行 返回set集合 去重无序
collect_list --把多行数据收集为一行 返回list集合 不去重有序- 字符串拼接函数
concat --直接拼接字符串
concat_ws --指定分隔符拼接- 类型转换 select cast(1 as string);
开窗函数(窗口函数) 【重点】
- 排序
- row_ number 行号:自然序号 不重复 不跳跃 如12345
- rank 排名;有重复,有跳跃 如12335
- dense_rank:排名:有重复 不跳跃 如12334
- ntile(N):分堆函数,把数据均衡分N堆,没一堆数据差不超过1条,不常用
- partition by+order by:分组,且组内排序
- partition by:分组
- order by:只是排序,不分组
- 排序的窗口范围
- 语法 over(partition by ··· order by··· rows between a and b)
- unbounded preceding 对上限无限制
- n preceding 当前行之前的n行
- current row 当前行
- n following 当前行之后的n行
- unbounded following 对下无限制
- 聚合函数
- count():表示求指定列的总记录数
- max():表示求指定列的最大值
- min():表示求指定列的最小值
- sum():表示求指定列的和
- avg():表示求指定列的平均值
- 分析(偏移)
- 语法 select lag() over(···) from ···;
- lag():同列中往前取值,默认偏移量是1个
- lead():同列中往后取值,默认偏移量是1个
- first_value(col):取第一个值,窗口从第一行开始开窗
- last_value(col):取最后一个,取到当前窗口的最后一个
Hive调优 【重点】
hive数据压缩
作用:以CPU换整体效率
hive底层是运行MapReduce,所以Hive支持什么压缩格式本质上取决于MapReduce


开启压缩
- 开启map输出阶段压缩可以减少job中map和Reduce task间数据传输量
- 当Hive将输出写入到表中时,输出内容同样可以进行压缩
- 用户可以通过在查询语句或执行脚本中设置这个值为true,来开启输出结果压缩功能
# 开启hive支持中间结果的压缩方案
set hive.exec.compress.intermediate=true ;
# 开启hive支持最终结果压缩
set hive.exec.compress.output=true;
# 开启MR的mapper端压缩操作
set mapreduce.map.output.compress=true;
# 设置mapper端压缩的方案
set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec;
# 开启MR的reduce端的压缩方案
set mapreduce.output.fileoutputformat.compress=true;
# 设置reduce端压缩的方案
set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
# 设置reduce的压缩类型
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
数据存储格式
- 列式存储和行式存储
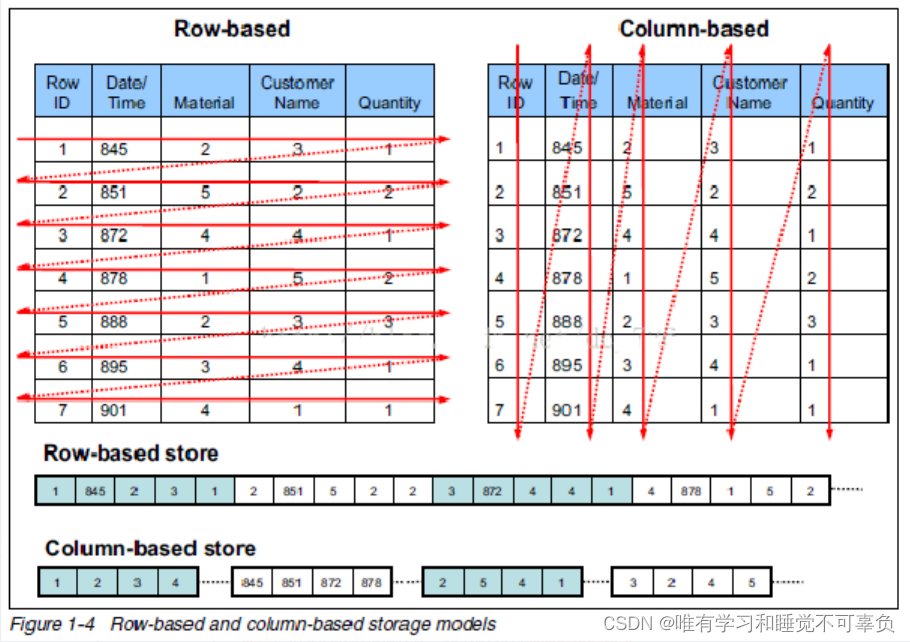
- 行式存储
特点: 查询满足条件的一整行数据的时候,列存储需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行式存储查询的速度更快
- textfile和sequencefile的存储格式都是基于行存储的
- 优点:相关的数据是保存在一起的 比较符合面向对象的思维因为一行数据就是一条记录这种存储格式比较方便进行insert/update操作
- 缺点: 如果查询只涉及某几个列,它会把整行数据都读取出来,不能跳过不要的列读取 如果数据量比较大就比较影响性能 由于每一行中,列的数据类型不一致,导致不用容易获得一个极高的压缩比,也就是空间利用率不高 不是所有的列都适合作为索引
- 列式存储
特点: 因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的压缩算法
- ORC和parquet都是基于列存储的
- 优点:查询时,只有涉及到的列才会被查询,不会把所有列都查询出来,即可以跳过不必要的列查询。高效的压缩率,不仅节省储存空间也节省计算内存和CPU任何列都可以作为索引
- 缺点: insert/update 很麻烦或者不方便 不适合扫描小量的数据
- TextFile格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大
可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压)但使用这种方式,hive不会对数据进行切分,从而无法对数据进入并行操作
# 创建表,存储数据格式为TEXTFILE:18.1M左右
# 语法 create table ···row format ··· 【stored as textfile】;
create table 表名(
id int
)row format delimited fields terminated by ','
stored as textfile;
- ORC格式
使用ORC文件格式可以提高Hive读、写和处理数据的能力

# 创建表 存储数据格式为ORC:2.8M左右
# 语法 create table ···row format ··· 【stored as orc】;
create table 表名(
id int
)row format delimited fields terminated by ','
stored as orc;
- 一个TextFile格式 导入orc表中,无法直接导入,使用insert into table (orc表) select * from (textfile表);
- ORC文件格式的数据,默认内置一种压缩算法:ZLIB,在实际生产中一般会将ORC压缩算法替换为snappy。格式为:STORED AS orc tblproperties(“orc.compress”=“SNAPPY”)
- parquet格式
面向分析性业务的列式存储格式

# 创建表 存储数据格式为parquet:13.1M左右
# 语法 create table ···row format ··· 【stored as parquet】;
create table 表名(
id int
)row format delimited fields terminated by ','
stored as parquet;
- fetch抓取
核心点:在执行SQL,能不走MR,尽量不走MR

hive.fetch.task.conversion=more: # 设置本地抓取策略
# none 所有查询都走MR
# minimal 保证执行全表扫描以,查询某几个列,简单limit操作,3种情况可以不走MR
# more 可以保证在执行全表扫描, 查询某几个列, 进度limit操作,还有简单条件查询4种情况都不会走MR 常用
扩展 HIve只有MR引擎吗
不是 他还有tez和spark引擎
面试题 128.1M文件 分几个块?运行几个MapReduce任务?
答:分2块 启动1个reduce任务
(严格执行128M每块的原则,reduce任务数量:128*1.1(144M) )
本地模式
本地模式不建议在生产环境使用
# 开启本地MR
set.hive.exec.mode.local.auto=true;
# 设置local MR的最大输入数据量 当输入数据量小于这个值时采用local mr的方式,默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=134217728;
# 设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=4;
- local模式 也就是说 hive可以在local运行 而不用提交到集群来运行
- hive把sql转换为MR后 在本地启动一个进程来模拟MapReduce框架,进行分布式计算
- 本地模式由于只有一个进程 所以适合计算少量数据 因此 开发测试常用 生产不用
hive的join优化 【重点】
原始的join,底层MR是如何运行???
- join合并操作,是发生在Reduce端的
- Map端主要负责读取数据,并且根据on条件,将on条件字段作为k2发送到reduce端
- 存在的弊端
(1) 可能会发生数据倾斜问题,某些reduce接收的数据量可能会远远大于其他的reduce
(2)所有的处理数据的压力都集中在reduce, 而reduce数量一般都是小于map的数量, 导致reduce端压力较大, 执行效率降低
- Map join
使用场景:大表 和 小表 join工作
原理
(1)将原有reduce端合并操作,移植到MapTask进行
(2)将小表的数据放置到每个MapTask的内存中
(3)MapTask在读取大表数据的时候,边读取,边和内存中数据进行关联,能关联上,直接输出,关联不上直接舍弃
弊端
比较消耗内存
要求整个join中,必须都有一个小表,否则无法放入内存中
# 开关(默认打开)
set hive.auto.convert.join=true
# 小表阈值(默认23.8M)
set hive.mapjoin.smalltable.filesize= 25000000; --设置 小表的文件大小(23.84m)
# 所有表阈值(总共加起来)
set hive.auto.convert.join.noconditionaltask.size=20971520; -- 设置 join任务数据量(总量)
- bucket Map join
使用场景:大表 和 中表 join工作
原理
对表进行分桶,通过分桶确保表中每个桶数据都能满足小表的阈值,从而支持将其放置到内存中,实现Map join关联
使用条件
(1)两个表必须为分桶表
(2)必须开启bucket map join 开关
(3)分桶字段必须是join字段
(4)两个表的分桶数量必须相同或为整数倍
(5)必须建立在map join的基础上
# 开关(默认打开)
set hive.optimize.bucketmapjoin; -- 默认false
- SMB join
使用场景:大表 和 大表 join工作
使用条件
(1)两个表必须为分桶表
(2)必须开启SMB map join 支持
(3)分桶字段必须是join字段,必须按照分桶字段进行排序
(4)两个表的分桶数量必须相同
(5)必须建立在bucket map join的基础上
(6)开启自动尝试SMB参数
# SMB map join 支持
set hive.auto.convert.sortmerge.join; -- 默认false
set hive.optimize.bucketmapjoin.sortedmerge ;-- 默认false
set hive.auto.convert.sortmerge.join.noconditionaltask;-- Hive 0.13.0默认开启
- skew join(博客觉得最好用的一个join优化)
(1)适用范围广:不限制key字段,只要key字段的值超过10万行就会生效
(2)由于 Bucket MapJoin和SMB Join,对key字段有要求(必须是分桶字段),所以skew join 的应用范围更广
(3)开启运行时倾斜优化 set hive.optimize.skewjoin=true;
(4)设置倾斜阈值 set hive.skewjoin.key=100000;
(5)运行顺序 1.先运行未倾斜的 2.后MapJoin倾斜的 3.union all
SQL优化——列裁剪、分区裁剪
- 列裁剪
- 需要几个列 就查询几个列
- HIve在读取数据的时候,可以只读取查询中所需要用到的列,而忽略其他列
3. set hive.optimize.pruner=true; --默认为就是true (在hive 2.x中无需在配置了, 直接为固定值: true)

- 分区裁剪
- 分区表一定要带上分区字段
- 如果操作的表是一张分区表,那么建议一点要带上分区字段,以减少扫描的数据量,从而提升效率
- set hive.optimize.pruner=true; --默认为就是true (在hive 2.x中无需在配置了, 直接为固定值: true)

SQL优化——count(distinct) 求和去重
- 在数据量比较大的情况下,效率并不高
- 数据量大的情况下,由于count distinct操作需要用一个Reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个join很难完成,一般count distinct 使用先group by 再count 的方式替代
- set hive.optimize.countdistinct = true; 默认就是true
Hive的数据倾斜 【重点】
- join引发的数据倾斜
- 方案一 : 采用 map Join、bucket Map Join 以及 SMB Join 解决
注意 通过 Map Join,Bucket Map Join,SMB Join 来解决数据倾斜, 但是 这种操作是存在使用条件的, 如果无法满足这些条件, 无法使用 这种处理方案
-
方案二: 将表中易发生倾斜的key值和对应数据单独抽取出来, 通过一个单独的MR处理, 处理完成后和之前结果进行合并
运行期解决
- 思路:在运行过程中, 不断的对k2的值进行计数, 当相同的k2的值出现的次数大于设定阈值, 认为此值存在倾斜, 将其单独提出, 由MR处理, 处理后在合并union all 即可
- 相关参数:
(1)set hive.optimize.skewjoin=true; (启运行期处理倾斜参数默认false)
(2)set hive.skewjoin.key=100000; (阈值 此参数在实际生产环境中, 需要调整在一个合理的值(否则极易导致大量的key都是倾斜的),默认100000)- 适用场景: 不太清楚表中哪些值存在倾斜
编译期解决
- 思路: 在建表的时候, 直接设置表中哪个字段对应的哪个值存在倾斜, 在运行的时候, 直接将其剔除, 交由MR处理, 处理后进行合并
- 相关使用参数
set hive.optimize.skewjoin.compiletime=true; ( 开启编译期处理倾斜参数)- 适用场景: 清晰的知道表中什么值存在倾斜问题
- group by 引起的数据倾斜
- 方案一: 采用combiner(规约) 对数据在map端进行提前聚合, 从而减少从map端到reduce的数量, 减轻数据倾斜的压力
默认开启 set hive.map.aggr=true;
- 方案二: 采用负载均衡的策略, 通过运行二个MR , 由第一个MR对数据进行打散操作, 并对打散数据进行提前聚合得到局部结果, 再由第二个MR进行最终聚合处理
默认关闭,如果需要,手动开启 set hive.groupby.skewindata=true;
注意: 一旦使用第二种, SQL语句中不允许出现多次的distinct操作
效果: 方案二相对来说解决的倾斜问题更加彻底一些
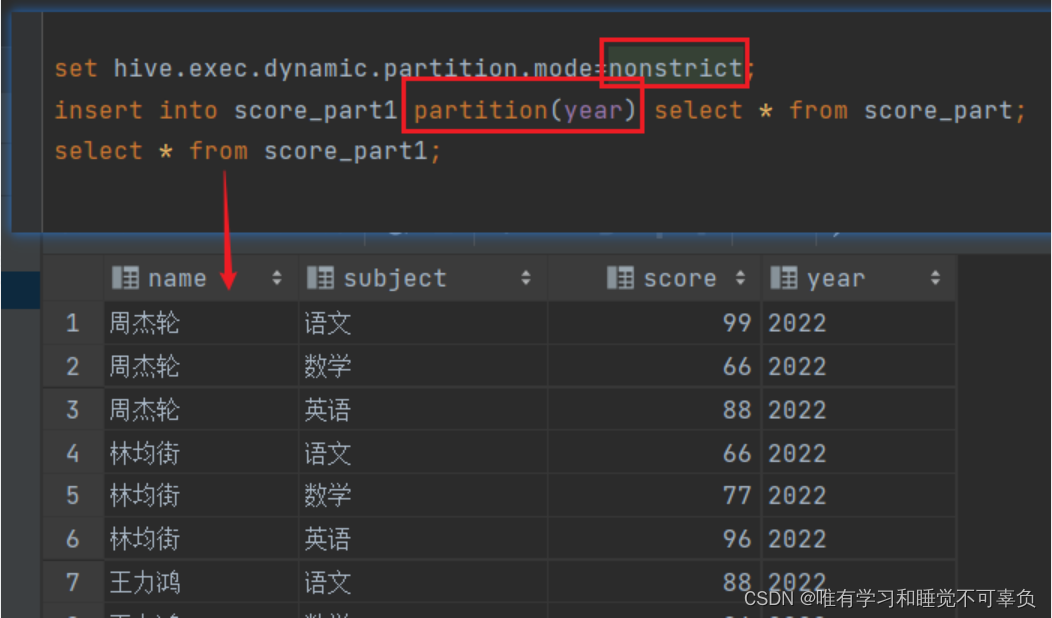
动态分区 【重点】
动态分区是以第一个表的分区规则,来对应第二个表的分区规则(所以第一个只能是静态表)
重要参数 使用动态分区一定要开启
开启非严格模式 默认为 strict(严格模式)
set hive.exec.dynamic.partition.mode=nonstrict;
开启动态分区支持, 默认就是true
set hive.exec.dynamic.partition=true;
严格模式
- hive默认严格模式 目的为了过滤一些低效率的SQL
- 低效率SQL:笛卡尔积、order by 不加limit、join的on条件没写或者不生效
动态分区不要指定具体的分区值,只需要指定分区字段
















 1776
1776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









