




 在Hadoop 2.2.0版本中,尝试通过filesystem访问DFS时遇到了HTTP 500错误,原因是使用了已废弃的`hadoop -namenode -format`命令。正确的做法是使用`hdfs namenode -format`进行HDFS初始化。问题解决方法包括:停止所有Hadoop进程,重新格式化,以及确保datanode未启动的情况下,检查并统一`dfs.name.dir/current/VERSION`中的clusterID,以匹配namenode的clusterID。完成这些步骤后,重启服务即可解决问题。
在Hadoop 2.2.0版本中,尝试通过filesystem访问DFS时遇到了HTTP 500错误,原因是使用了已废弃的`hadoop -namenode -format`命令。正确的做法是使用`hdfs namenode -format`进行HDFS初始化。问题解决方法包括:停止所有Hadoop进程,重新格式化,以及确保datanode未启动的情况下,检查并统一`dfs.name.dir/current/VERSION`中的clusterID,以匹配namenode的clusterID。完成这些步骤后,重启服务即可解决问题。
2.2.0版本中通过filesystem进入
http://192.168.211.128:50070/nn_browsedfscontent.jsp
界面显示如下:
HTTP ERROR 500
Problem accessing /nn_browsedfscontent.jsp. Reason:
Can't browse the DFS since there are no live nodes available to redirect to.
Caused by:
java.io.IOException: Can’t browse the DFS since there are no live nodes available to redirect to.
at org.apache.hadoop.hdfs.server.namenode.NamenodeJspHelper.redirectToRandomDataNode(NamenodeJspHelper.java:646)
at org.apache.hadoop.hdfs.server.namenode.nn_005fbrowsedfscontent_jsp._jspService(nn_005fbrowsedfscontent_jsp.java:70)
at org.apache.jasper.runtime.HttpJspBase.service(HttpJspBase.java:98)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:820)
at org.mortbay.jetty.servlet.ServletHolder.handle(ServletHolder.java:511)
at org.mortbay.jetty.servlet.ServletHandler
CachedChain.doFilter(ServletHandler.java:1221)atorg.apache.hadoop.http.lib.StaticUserWebFilter
StaticUserFilter.doFilter(StaticUserWebFilter.java:109)
at org.mortbay.jetty.servlet.ServletHandler
CachedChain.doFilter(ServletHandler.java:1212)atorg.apache.hadoop.http.HttpServer
QuotingInputFilter.doFilter(HttpServer.java:1081)
at org.mortbay.jetty.servlet.ServletHandler
CachedChain.doFilter(ServletHandler.java:1212)atorg.apache.hadoop.http.NoCacheFilter.doFilter(NoCacheFilter.java:45)atorg.mortbay.jetty.servlet.ServletHandler
CachedChain.doFilter(ServletHandler.java:1212)
at org.apache.hadoop.http.NoCacheFilter.doFilter(NoCacheFilter.java:45)
at org.mortbay.jetty.servlet.ServletHandler
CachedChain.doFilter(ServletHandler.java:1212)atorg.mortbay.jetty.servlet.ServletHandler.handle(ServletHandler.java:399)atorg.mortbay.jetty.security.SecurityHandler.handle(SecurityHandler.java:216)atorg.mortbay.jetty.servlet.SessionHandler.handle(SessionHandler.java:182)atorg.mortbay.jetty.handler.ContextHandler.handle(ContextHandler.java:766)atorg.mortbay.jetty.webapp.WebAppContext.handle(WebAppContext.java:450)atorg.mortbay.jetty.handler.ContextHandlerCollection.handle(ContextHandlerCollection.java:230)atorg.mortbay.jetty.handler.HandlerWrapper.handle(HandlerWrapper.java:152)atorg.mortbay.jetty.Server.handle(Server.java:326)atorg.mortbay.jetty.HttpConnection.handleRequest(HttpConnection.java:542)atorg.mortbay.jetty.HttpConnection
RequestHandler.headerComplete(HttpConnection.java:928)
at org.mortbay.jetty.HttpParser.parseNext(HttpParser.java:549)
at org.mortbay.jetty.HttpParser.parseAvailable(HttpParser.java:212)
at org.mortbay.jetty.HttpConnection.handle(HttpConnection.java:404)
at org.mortbay.io.nio.SelectChannelEndPoint.run(SelectChannelEndPoint.java:410)
at org.mortbay.thread.QueuedThreadPool$PoolThread.run(QueuedThreadPool.java:582)
Powered by Jetty://
导致这种错误的原因是使用2.2.0版本就废弃的hadoop -namenode -format进行hdfs初始化,应该使用hdfs namenode
-format进行。
解决办法为先停止所有hadoop相关进程,然后使用hdfs namenode -format格式化再重启服务。
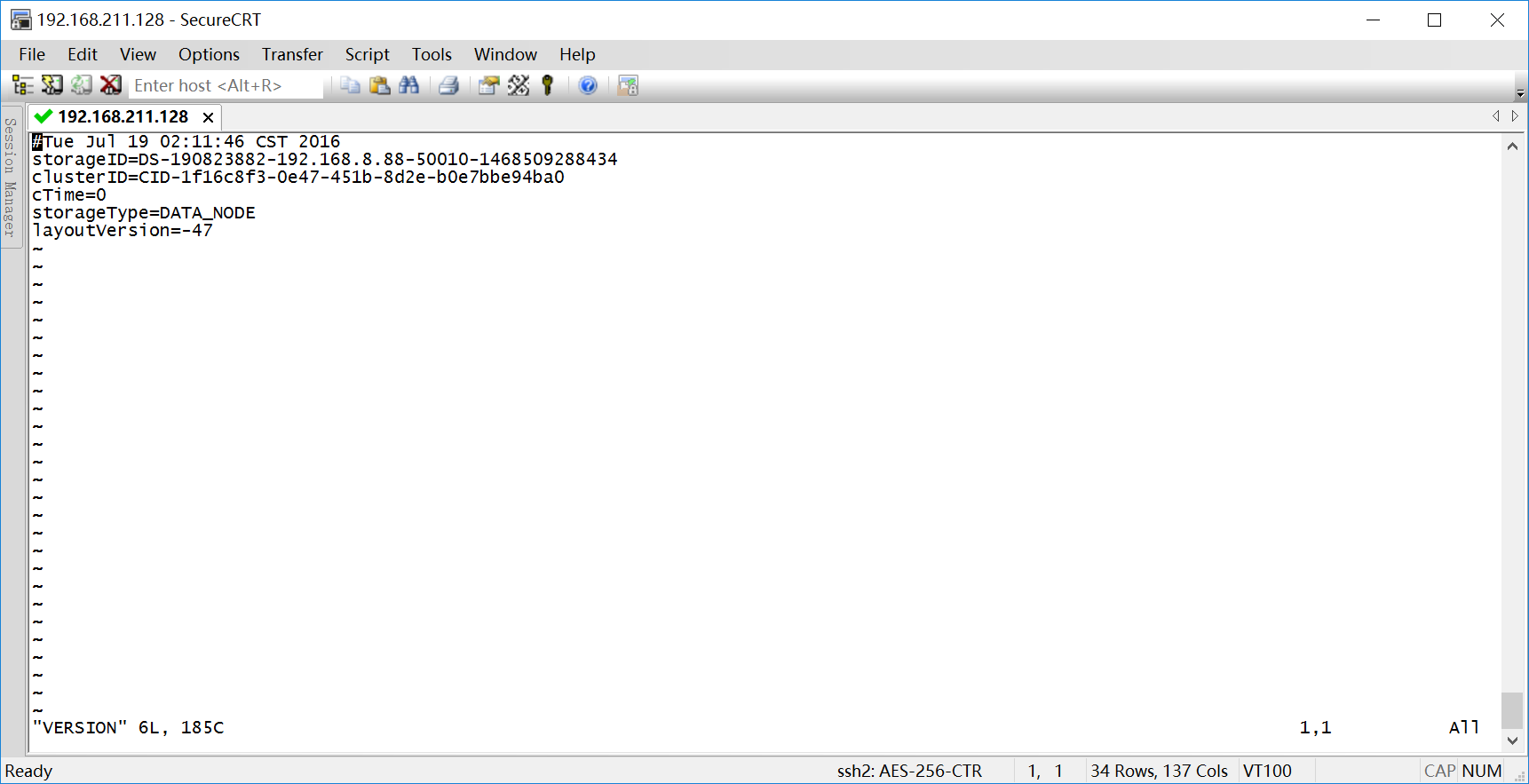
重启后产生了新的问题,使用jps查看hadoop进程发现datanode没有启动。以前也遇到过,是因为在配置文件中dfs.name.dir的路径下的/current/VERSION中每次格式化VERSION的clusterID会产生一个新的ID。
解决办法为:
查看hadoop目录下log目录下datanode相关的log文件,

找到namenode下面的clusterID,

修改dfs.name.dir/current/VERSION 里面的clusterID使二者一致。修改后保存重启服务即可。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









