







这两天用虚拟机搭建了hadoop集群环境,创建了三台虚拟机hadoop01,hadoop02,hadoop03,hadoop01代表Master,hadoop02以及hadoop03作为 Slave 节点。三台虚拟机都是centos7最小化安装。hadoop版本用的最新的版本2.7.2。
开始一切都很顺利,启动hadoop集群也成功启动,运行jps,三个节点对应的进程都成功启动,但是检查集群状态时发现live node 为0(如图)。
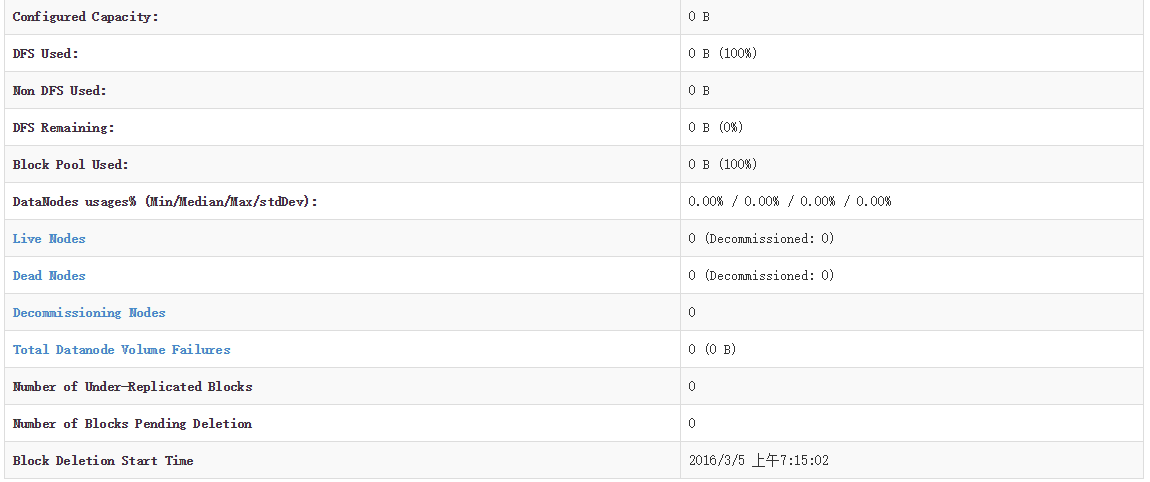
这个就让人很郁闷了,检查了下 Slave 节点日志,发现一些异常的地方:
2016-03-05 07:34:23,972 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: hadoop01/192.168.116.101:9000
2016-03-05 07:34:29,980 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: hadoop01/192.168.116.101:9000. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2016-03-05 07:34:30,985 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: hadoop01/192.168.116.101:9000.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1802
1802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









