







一.简介
二.安装部署
三.运行hadoop例子并测试部署环境
四.注意的地方
一.简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据,则MapReduce为海量的数据提供了计算。Hadoop 容易开发和运行处理大规模数据的平台。
HDFS是Java语言开发,因此任何支持Java的机器都可以部署Namenode或Datanode,HDFS采用master/slave架构,一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。如图所示所示:
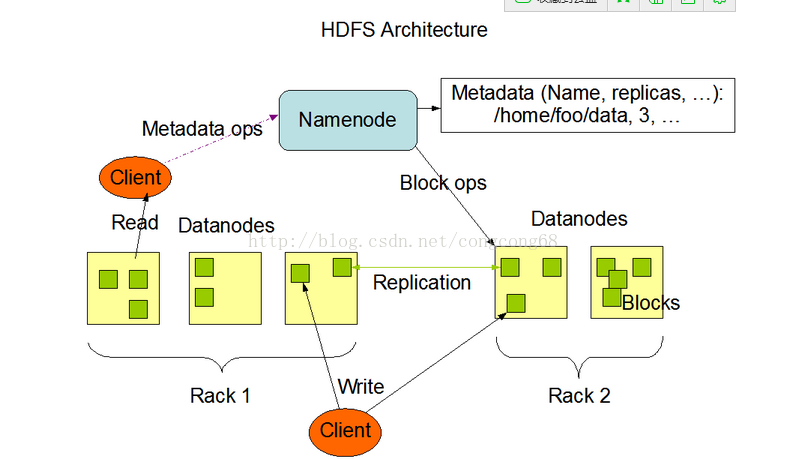
Hadoop Map/Reduce是一个使用简易的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。一个Map/Reduce 作业(job) 通常会把输入的数据集切分为若干独立的数据块,由 map任务(task)以完全并行的方式处理它们。框架会对map的输出先进行排序, 然后把结果输入给reduce任务。通常作业的输入和输出都会被存储在文件系统中。 整个框架负责任务的调度和监控,以及重新执行已经失败的任务。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
1.高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
2.高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
3.高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
4.高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
5.低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop 伪分布式模式是在单机上模拟 Hadoop 分布式,条件有限,所以linux虚拟机上部署Hadoop 伪分布式模式来模拟 Hadoop 分布式。
二.安装部署
Linux虚拟机上JDK安装配置,这里就不介绍,我之前文章有介绍过了。
第一步:ssh无密码验证配置
1.查看一下SSH是否有安装

2.基于空口令创建一个新的SSH密钥,启用无密码登录
#ssh-keygen -t rsa -P '' -f~/.ssh/id_rsa
#cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys
3.测试一下是否需要密码登陆
#ssh localhost 如图所示:

这说明已经安装成功,第一次登录时会询问你是否继续链接,输入yes即可进入。
说明:
因为在Hadoop的安装过程中,如果不配置无密码登录,每次启动Hadoop,需要输入密码登陆到DataNode,我们通常会做集群,所以这样就不方便我们操作。
第二步:部署hadoop
1.下载 http://hadoop.apache.org/
我们这边下载的是hadoop-2.6.0.tar.gz
2.mkdir /usr/local/hadoop
3.#tar -zxvf hadoop-2.6.0.tar.gz//解压
4.#vi /etc/profile //配置hadoop
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.6.0
export PATH=$HADOOP_HOME/bin:$PATH
export HADOOP_LOG_DIR=${HADOOP_HOME}/logs
#source/etc/profile //使配置生效5.配置core-site.xml,hdfs-site.xml及mapred-site.xml
#cd hadoop-2.6.0//进入hadoop解压的目录
etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.74.129:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop-2.6.0/tmp</value>
</property>
</configuration>
etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/hadoop-2.6.0/hdfs/name</value>
<description>对namenode存储路径</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/hadoop-2.6.0/hdfs/data</value>
<description>对datanode存储路径</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://192.168.74.129:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/usr/local/hadoop/hadoop-2.6.0/mapred/local</value>
<description>存储mapred自己使用的路径</description>
</property>
<property>
<name>mapred.system.dir</name>
<value>/usr/local/hadoop/hadoop-2.6.0/mapred/system</value>
<description>存储mapred系统级别的路径,可以共享</description>
</property>
</configuration>
#vi etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_67
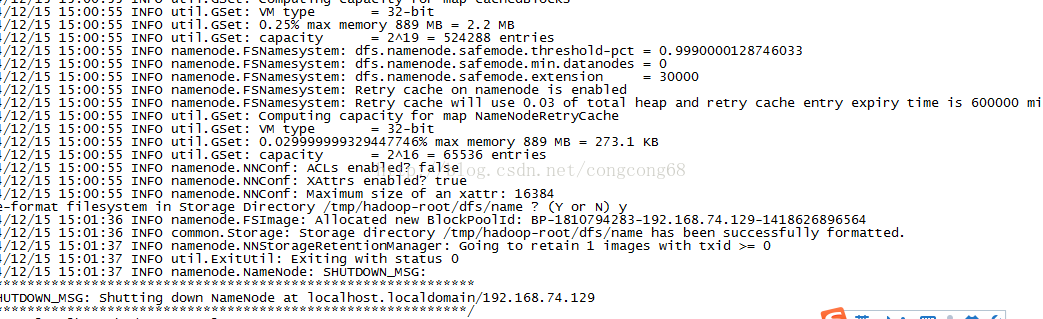
7.#hadoop namenode -format //格式化HDFS文件系统以创建一个空大文件系统。
执行成功如图所示:
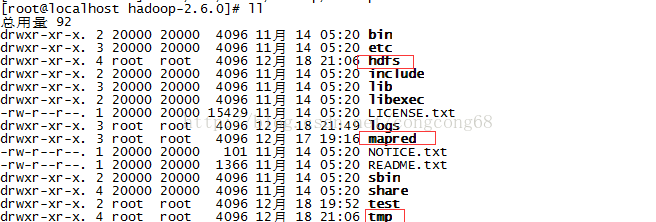
生成core-site.xml,hdfs-site.xml及mapred-site.xml对应的目录,如图所示:
第三步:启动hadoop服务
1.#sbin/start-all.sh //启动 sbin/stop-all.sh //关闭

2.#jps//验证一下
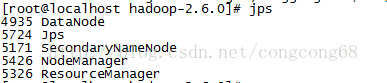
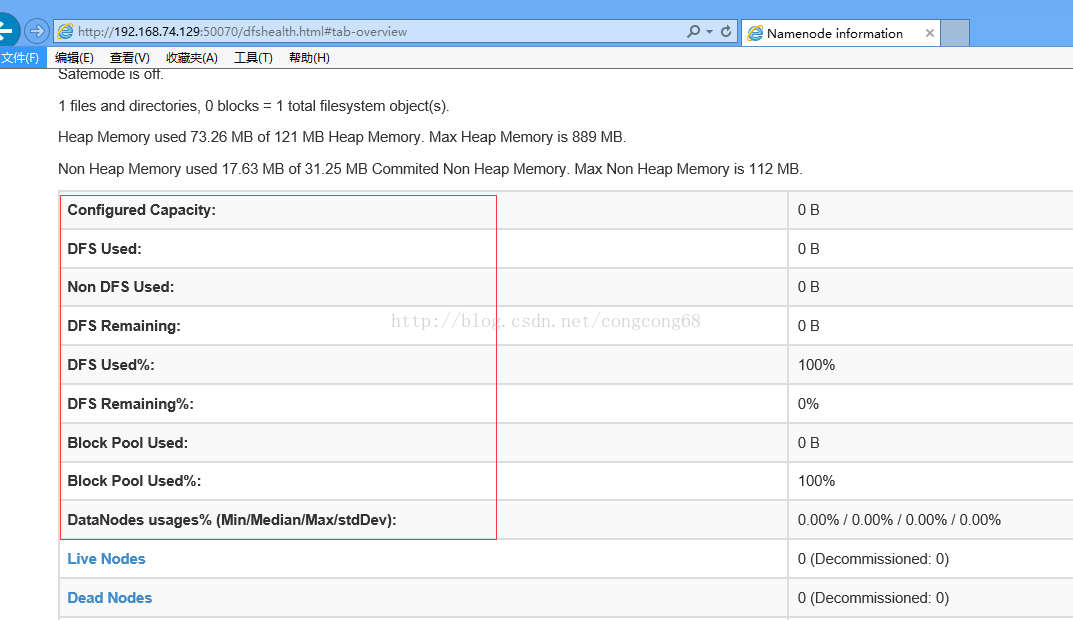
3.在浏览器查看hadoop信息
http://192.168.74.129:50070
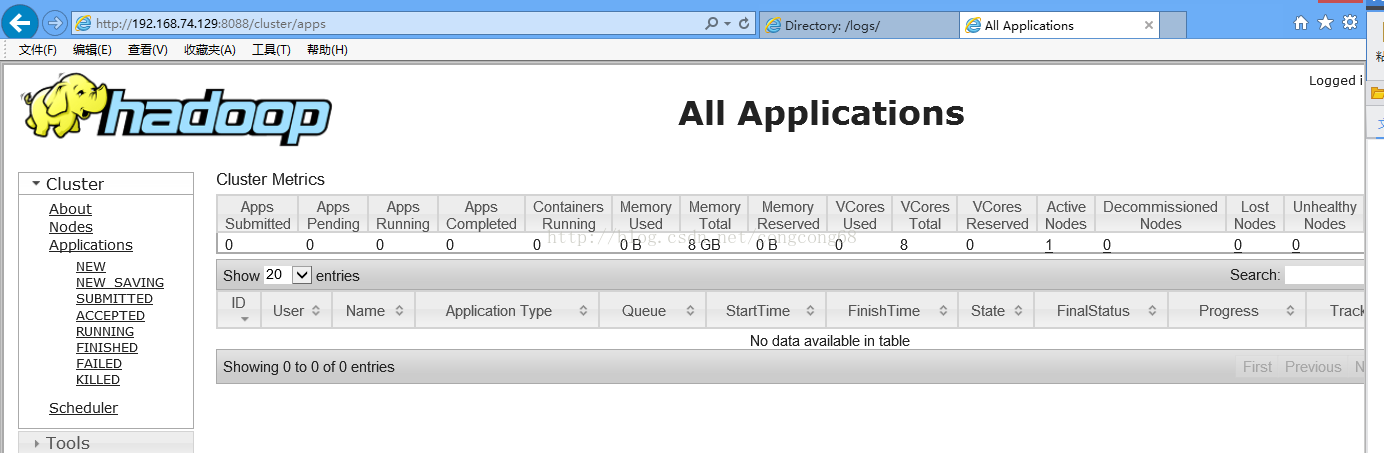
http://192.168.74.129:8088 hadoop管理页面
4.可以在 cd /usr/local/hadoop/hadoop-2.6.0/logs 查看日志

三.运行hadoop例子并测试部署环境
1.我们从官方网的例子来运行一下,看看我们部署的hadoop环境是否正确,统计数代码如下:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
上传到hadoop解压的目录,如图所示:
2.查看有没有目录
#hadoop fs –ls //刚部署完,我们还没创建目录,所以会显示没目录如图所示:

3.我们新建一个file0.txt文本,输入内容,也就是我们要统计的单词,如图所示:

4.创建输入和输出目录
先在hdfs上建个文件夹
#bin/hdfs dfs -mkdir –p /user/root/input
#bin/hdfs dfs -mkdir -p /user/root/output
5.把要统计的文本上传到hdfs的输入目录下
# bin/hdfs dfs -put/usr/local/hadoop/hadoop-2.6.0/test/* /user/root/input //把tes/file0文件上传到hdfs的/user/root/input中
6.查看
#bin/hdfs dfs -cat /user/root/input/file0

7.编译我们刚才写的统计Java类WordCount.java
#bin/hadoop com.sun.tools.javac.Main WordCount.java
8.编译好的WordCount.class创建一个 jar
jar cf wc.jar WordCount*.class
9.执行统计
#bin/hadoop jar wc.jar WordCount /user/root/input/user/root/output/count
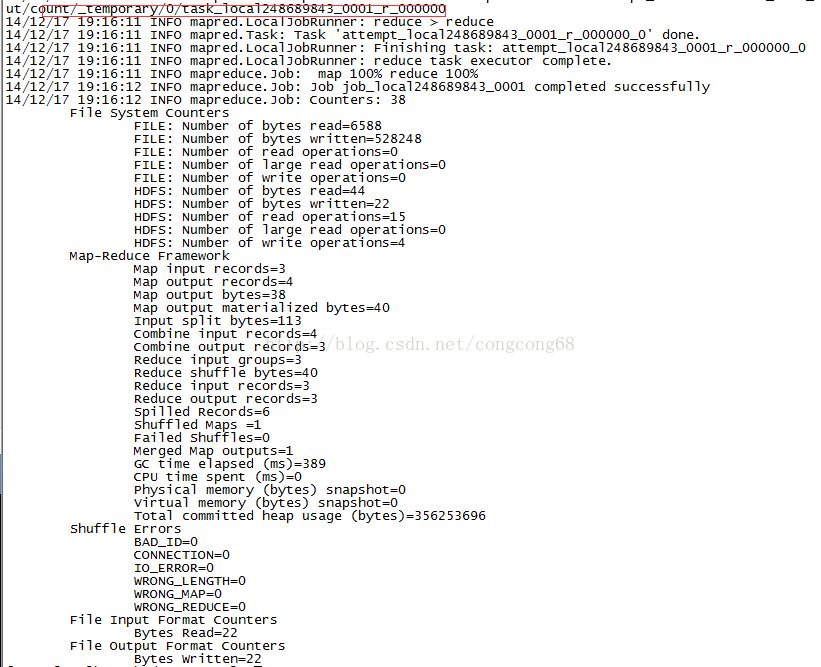
10.查看输出output
#bin/hdfs dfs -cat/user/root/output/count/part-r-00000

四.注意的地方
1.#hadoop namenode -format格式化时,HostName配置不对时,会报这个错误,如图所示:
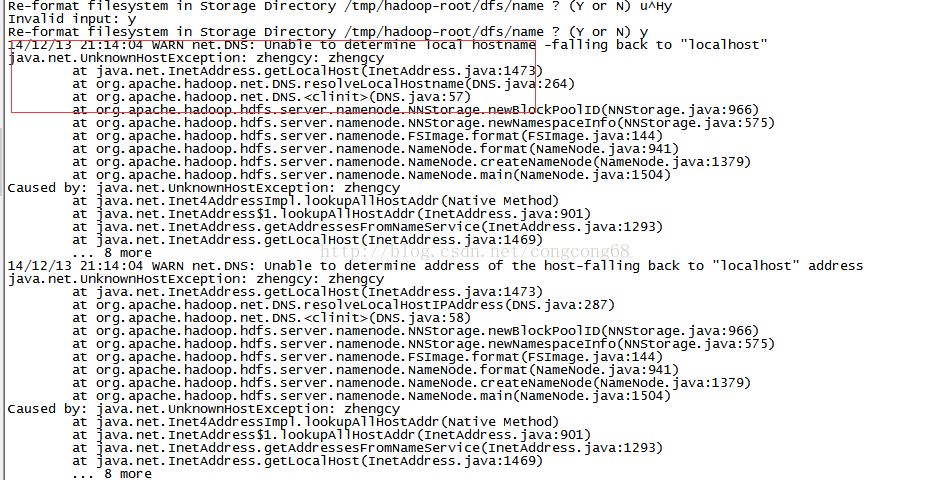
分析:
#hsotname

这时在/etc/hosts文件中找不到对应的这个hostname

解决方法:
1)vi /etc/hosts //修改设置的ip

2)#vi /etc/sysconfig/network //修改hostname

3)/etc/rc.d/init.d/network restart //重启一下
如果没修改过来,就重启一下Linux虚拟机
2.#hadoop fs –ls会出现
Java HotSpot(TM) Server VM warning: Youhave loaded library/usr/local/hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might havedisabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix thelibrary with 'execstack -c <libfile>', or link it with '-z noexecstack'.

解决:
#vi /etc/profile
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
#source /etc/profile
在执行一下hadoop fs –ls就不会出现这样的问题,如图所示:
















 1223
1223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











