







目录
引言
Hadoop生态的搭建有本地模式、伪分布模式、集群模式(3台机器)三种安装模式,本篇文章将详细介绍Hadoop3.3的伪分布安装模式。
实验目的及准备
一、完成Hadoop3.3伪分布安装
二、在Linux中配置jdk1.8环境变量
三、配置主机的免密钥登录
准备:MobaXterm、Centos7系统、jdk-8u112-linux-x64.tar.gz、Hadoop3.3
实验步骤
一、启动虚拟机master节点,连接至mobaXterm的远程终端:
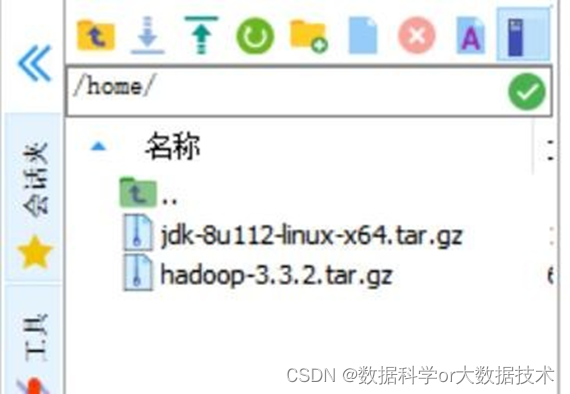
二、上传Hadoop3.3.2以及jdk安装包至主节点的/home路径下(该安装包在CSDN中都可以搜寻到,作者无法重复上传):
三、解压缩Hadoop以及jdk的安装包至/opt目录下:
cd /home
tar -zxvf jdk-8u112-linux-x64.tar.gz -C /opt/
tar -zxvf hadoop-3.3.2.tar -C /opt/四、解压完成后,配置JDK环境变量并进行测试:
vi /etc/profile
#添加以下内容后保存退出:
export JAVA_HOME=/opt/jdk1.8.0_112 export JRE_HOME=/opt/jdk1.8.0_112/jre
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#生效:
source /etc/profile
输入以下命令进行jdk安装成功的测试,出现1.8.0的jdk版本号即为安装成功:
java -version五、配置master节点并完成伪分布安装(共配置六个文件):
1.配置Hadoop-env.sh
cd /opt/hadoop-3.3.2/etc/hadoop
vi hadoop-env.sh
修改 JAVA_HOME 后保存退出:

2.配置core-site.xml
配置该文件,指定HDFS的namenode地址,value值是主机名加端口号,该实验中主机使用master节点的ip地址,请注意修改:
cd /opt/hadoop-3.3.2/etc/hadoop/
vi core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://10.244.1.3:9000</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://10.244.1.3:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadooptmp</value>
</property>截图如下:

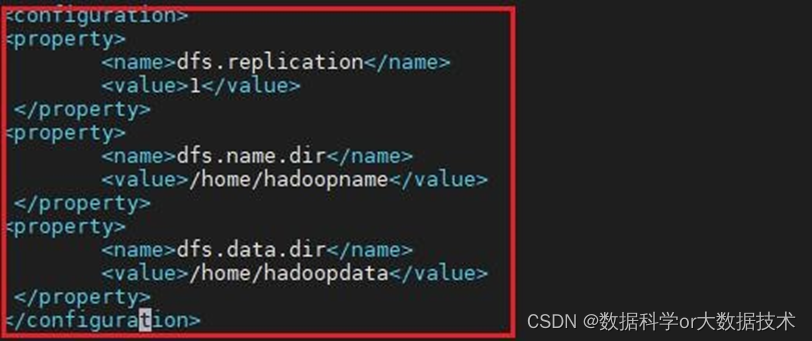
3.配置hdfs-site.xml:
配置该文件,指定HDFS保存数据的副本数量,伪分布模式下只有一个节点,所以此处为:1
cd /opt/hadoop-3.3.2/etc/hadoop/
vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoopname</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoopdata</value>
</property>
截图如下:
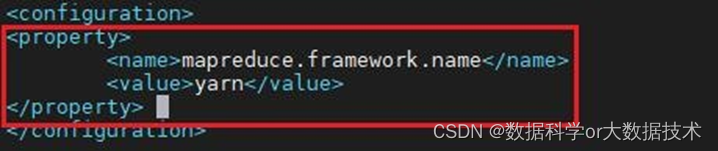
4.配置mapred-site.xml
cd /opt/hadoop-3.3.2/etc/hadoop/
vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
截图如下:
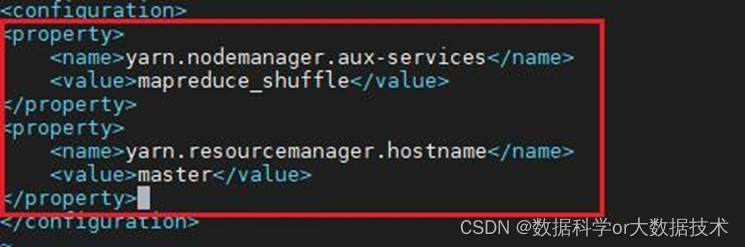
5.配置yarn-site.xml文件:
添加两个属性,第一个告诉nodemanager获取数据的方式为:shuffle;第二个告诉resourcemanager安装的主机(hostname)。
cd /opt/hadoop-3.3.2/etc/hadoop/
vi yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
截图如下:
6.配置etc/profile文件:
cd /opt/hadoop-3.3.2/etc/hadoop/
vi /etc/profile
export HADOOP_HOME=/opt/hadoop-3.3.2
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile
截图如下:

六、配置主机的免密钥登录
配置本地免密钥登录:
cd /root
#如果本机没有登录过其他机器时,本地是没有/root/.ssh 文件夹的,只需要:ssh master 登录一次,就会自动创建了。
cd .ssh
ssh-keygen -t rsa
cat id_rsa.pub >> authorized_keys
#测试免输入密码:
ssh master
截图如下:

七、初始化Hadoop
初始化之前,cd /opt/hadoop-3.3.2/sbin/,进入 sbin 目录,在 start-dfs.sh,stop-dfs.sh, start-yarn.sh,stop-yarn.sh 四个文件顶部添加参数,之后就可以使用 root 账号登陆 hdfs 和 yarn 了。
vim start-dfs.sh 和 vim stop-dfs.sh
#添加以下内容
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
在start-dfs.sh以及stop-dfs.sh两个文件顶部添加如下参数:

同理,在start-yarn.sh以及stop-yarn.sh两个文件顶部添加如下参数:
vim start-yarn.sh 和 vim stop-yarn.sh
#添加以下内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root截图如下:

接下来开始初始化:
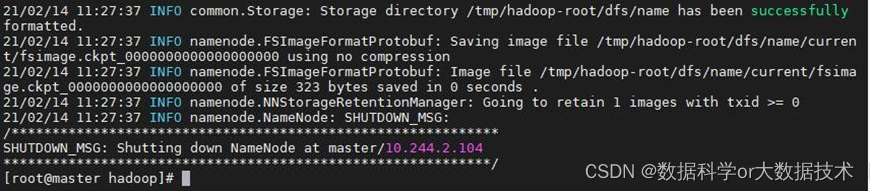
先格式化:在/opt/hadoop-3.3.2/etc/hadoop/ 路径下输入命令
cd /opt/hadoop-3.3.2/etc/hadoop/ hadoop namenode -format输入后截图如下:
八、启动Hadoop并进行测试
start-dfs.sh
start-yarn.sh启动成功截图如下:

测试相关HDFS命令:
列出HDFS目录下所有的文件
hadoop fs -ls /在HDFS目录上新建一个test文件夹:
hadoop fs -mkdir /test再次列出HDFS目录下所有文件
hadoop fs -ls /截图如下:

登录namenode的HTTP前端web网页UI(port:9870),查看该网页前,请关闭防火墙(systemctl stop firewalld)
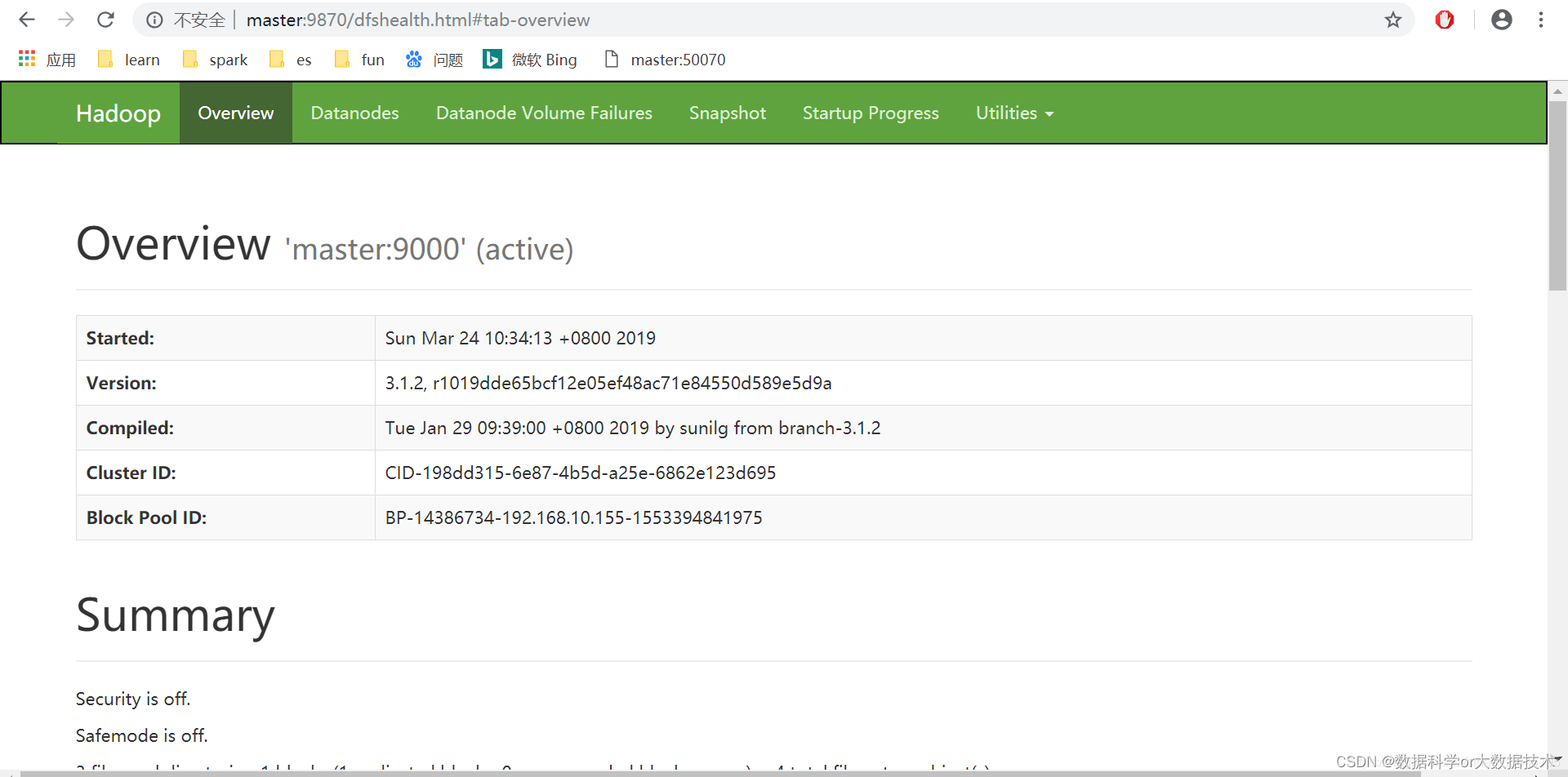
以上就是Hadoop3.3的伪分布安装搭建以及测试流程。
















 2528
2528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









