







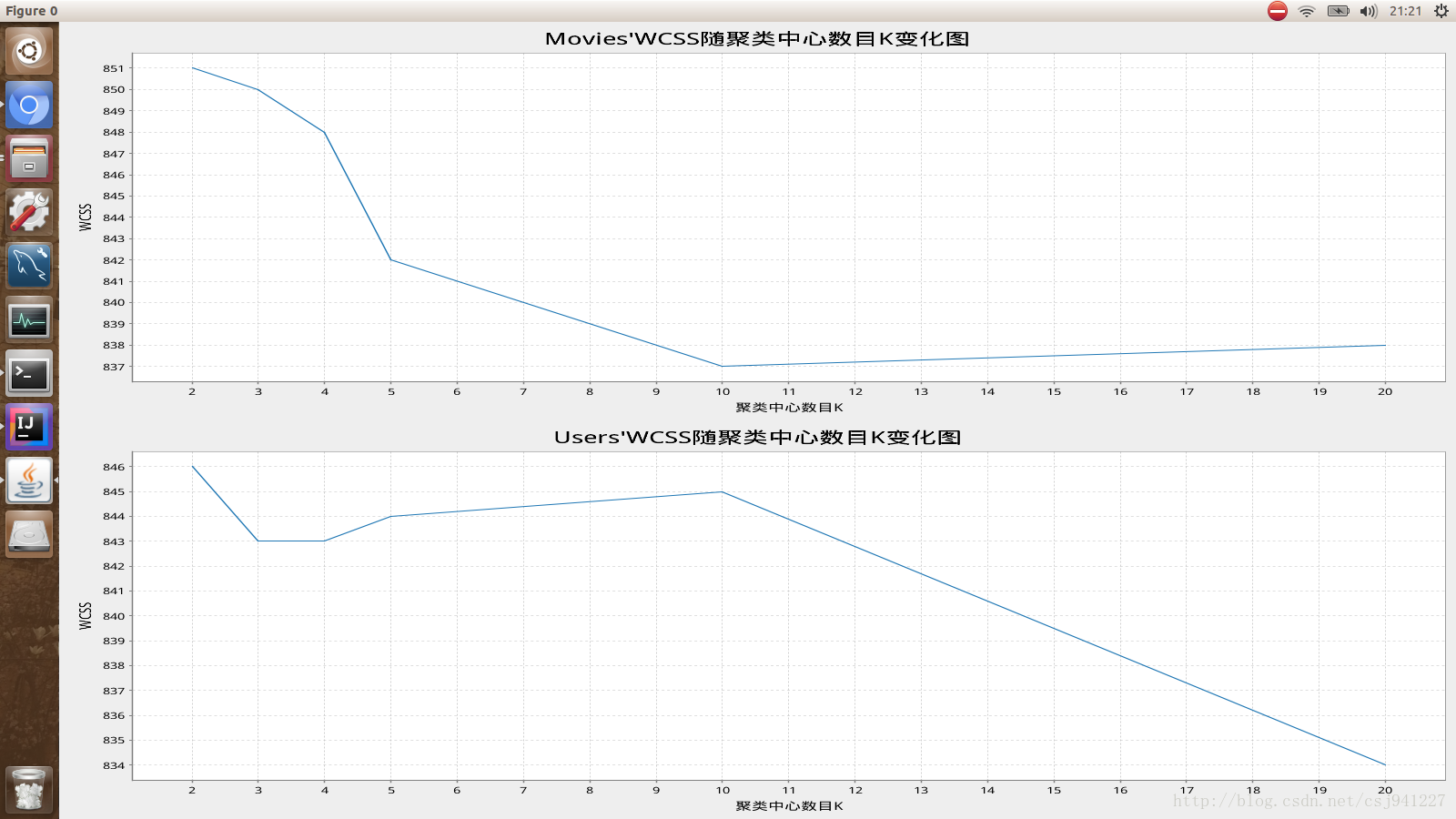
import breeze.plot.{Figure, hist, plot} import org.apache.spark.mllib.clustering.KMeans import org.apache.spark.mllib.linalg.Vectors import org.apache.spark.mllib.linalg.distributed.RowMatrix import org.apache.spark.mllib.recommendation.{ALS, Rating} import org.apache.spark.{SparkConf, SparkContext} object 聚类 { def main(args: Array[String]): Unit = { //连接SparkMaster val conf = new SparkConf().setAppName("Spark机器学习:聚类").setMaster("local") val sc = new SparkContext(conf) val movies = sc.textFile("file:///home/chenjie/ml-100k/u.item") println(movies.first()) //1|Toy Story (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Toy%20Story%20(1995)|0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0 val genres = sc.textFile("file:///home/chenjie/ml-100k/u.genre") genres.foreach(println) /*unknown|0 Action|1 Adventure|2 Animation|3 Children's|4 Comedy|5 Crime|6 Documentary|7 Drama|8 Fantasy|9 Film-Noir|10 Horror|11 Musical|12 Mystery|13 Romance|14 Sci-Fi|15 Thriller|16 War|17 Western|18*/ val genreMap = genres.filter(! _.isEmpty) .map(line => line.split("\\|")) .map(array => (array(1), array(0))) .collectAsMap() println(genreMap) //Map(2 -> Adventure, 5 -> Comedy, 12 -> Musical, 15 -> Sci-Fi, 8 -> Drama, 18 -> Western, 7 -> Documentary, 17 -> War, 1 -> Action, 4 -> Children's, 11 -> Horror, 14 -> Romance, 6 -> Crime, 0 -> unknown, 9 -> Fantasy, 16 -> Thriller, 3 -> Animation, 10 -> Film-Noir, 13 -> Mystery) val titlesAndGenres = movies.map(_.split("\\|")).map{ array => //1|Toy Story (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Toy%20Story%20(1995)|0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0 val genres = array.toSeq.slice(5, array.size) //0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0 val genresAssigned = genres.zipWithIndex.filter{ case (g, idx) => // g:0|0|0|1|1|1|0|0|0|0| 0| 0| 0| 0| 0| 0| 0| 0| 0 //idx:0|1|2|3|4|5|6|7|8|9|10|11|12|13|14|15|16|17|18 g == "1" }.map{ case (g, idx) => // g:|1|1|1 //idx:|3|4|5 //3 -> Animation 4 -> Children's 5 -> Comedy genreMap(idx.toString) //Animation Children's Comedy } (array(0).toInt, (array(1), genresAssigned)) //(1,(Toy Story (1995),ArrayBuffer(Animation, Children's, Comedy))) } println(titlesAndGenres.first()) //(1,(Toy Story (1995),ArrayBuffer(Animation, Children's, Comedy))) val rawData = sc.textFile("file:///home/chenjie/ml-100k/u.data") val rawRatings = rawData.map(_.split("\t").take(3)) val ratings = rawRatings.map{ case Array(user, movie, rating) => Rating(user.toInt, movie.toInt, rating.toDouble) } ratings.cache() val alsModel = ALS.train(ratings, 50, 10, 0.1) //最小二乘法返回两个键值RDD user-Features 和 product-Features //键分别是用户ID或者电影ID,值为相关因素 //现在提取相关因素并转换到MLlib的Vector中作为聚类模型的输入 val movieFactors = alsModel.productFeatures.map{ case (id, factor) => (id, Vectors.dense(factor)) } val movieVectors = movieFactors.map(_._2) val userFactors = alsModel.userFeatures.map{ case (id, factor) => (id, Vectors.dense(factor)) } val userVectors = userFactors.map(_._2) val movieMatrix = new RowMatrix(movieVectors) val movieMatrixSummary = movieMatrix.computeColumnSummaryStatistics() val userMatrix = new RowMatrix(userVectors) val userMatrixSummary = userMatrix.computeColumnSummaryStatistics() println("Movie factors mean :" + movieMatrixSummary.mean) println("Movie factors variance :" + movieMatrixSummary.variance) println("User factors mean :" + userMatrixSummary.mean) println("User factors variance :" + userMatrixSummary.variance) //观察输入数据的相关因素特征向量的分布,以便判断是否需要进行归一化 //没有发现特别的离群点,则不会影响聚类结果,因此没有必要进行归一化 val numCluster = 5//K val numIterations = 10//最大迭代次数 val numRuns = 3//训练次数 val movieClusterModel = KMeans.train(movieVectors, numCluster, numIterations, numRuns) println(movieClusterModel) val movieClusterModelConverged = KMeans.train(movieVectors, numCluster, numIterations, 100) println(movieClusterModelConverged) //7、4 使用聚类模型进行预测 val movie1 = movieVectors.first() val movieCluster = movieClusterModel.predict(movie1) println("预测一个:" + movieCluster) val predictions = movieClusterModel.predict(movieVectors) println("预测一堆:" + predictions.take(5).mkString(",")) import breeze.linalg._ import breeze.numerics.pow def computeDistance(v1: DenseVector[Double], v2: DenseVector[Double]) = pow(v1 - v2, 2).sum //用MovieLens数据集解释类别预测 val titlesWithFactors = titlesAndGenres.join(movieFactors) val movieAssigned = titlesWithFactors.map{ case (id, ((title, genres), vector)) => val pred = movieClusterModel.predict(vector) val clusterCentre = movieClusterModel.clusterCenters(pred) val dist = computeDistance(DenseVector(clusterCentre.toArray), DenseVector(vector.toArray)) (id, title, genres.mkString(" "), pred, dist) } val clusterAssignments = movieAssigned.groupBy{ case (id, title, genres, cluster, dist) => cluster} .collectAsMap() for ( (k, v) <- clusterAssignments.toSeq.sortBy(_._1)){ println(s"Cluster $k") val m = v.toSeq.sortBy(_._5) println(m.take(20).map{ case (_, title, genres, _, d) => (title, genres, d) }.mkString("\n")) println("========\n") } //7、5 评估聚类模型的性能 //7、5、1 内部评价指标 //WCSS Davies-Bouldin指数 Dunn指数 轮廓系数 //7、5、2 外部评价指标 // Rand measure、 F-measure、Kaccard index等 //7、5、3 使用MLlib提供的函数 val movieCost = movieClusterModel.computeCost(movieVectors) println("WCSS for movies : " + movieCost) //7、6 聚类模型参数调优 //通过交叉验证选择K val trainTestSplitMovies = movieVectors.randomSplit(Array(0.6, 0.4), 123) val trainMovies = trainTestSplitMovies(0) val testMovies = trainTestSplitMovies(1) val costsMovies = Seq(2, 3, 4, 5, 10, 20).map{ k => (k, KMeans.train(trainMovies, numIterations, k, numRuns).computeCost(testMovies))} println("Movie clustering cross-validation:") costsMovies.foreach{ case (k, cost) => println(f"WCSS for K=$k id $cost%2.4f")} val x_p_1 = costsMovies.map{ case(value,count) => value.toInt}.toSeq val y_p_1 = costsMovies.map{ case(value,count) => count.toInt}.toSeq val f = Figure() val p1 = f.subplot(2,1,0)//2行1列第0个 p1.title = "Movies'WCSS随聚类中心数目K变化图" p1 += plot(x_p_1, y_p_1) p1.xlabel = "聚类中心数目K" p1.ylabel = "WCSS" val trainTestSplitUsers = userVectors.randomSplit(Array(0.6, 0.4), 123) val trainUsers = trainTestSplitMovies(0) val testUsers = trainTestSplitMovies(1) val costsUsers = Seq(2, 3, 4, 5, 10, 20).map{ k => (k, KMeans.train(trainUsers, numIterations, k, numRuns).computeCost(testUsers))} println("Users clustering cross-validation:") costsUsers.foreach{ case (k, cost) => println(f"WCSS for K=$k id $cost%2.4f")} val x_p_2 = costsUsers.map{ case(value,count) => value.toInt}.toSeq val y_p_2 = costsUsers.map{ case(value,count) => count.toInt}.toSeq val p2 = f.subplot(2,1,1)//2行1列第0个 p2.title = "Users'WCSS随聚类中心数目K变化图" p2 += plot(x_p_2, y_p_2) p2.xlabel = "聚类中心数目K" p2.ylabel = "WCSS" } }














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









