







决策数(Decision Tree)在机器学习中也是比较常见的一种算法,属于监督学习中的一种。看字面意思应该也比较容易理解,相比其他算法比如支持向量机(SVM)或神经网络,似乎决策树感觉“亲切”许多。
- 优点:计算复杂度不高,输出结果易于理解,对中间值的缺失值不敏感,可以处理不相关特征数据。
- 缺点:可能会产生过度匹配的问题。
- 使用数据类型:数值型和标称型。
简单介绍完毕,让我们来通过一个例子让决策树“原形毕露”。
一天,老师问了个问题,只根据头发和声音怎么判断一位同学的性别。
为了解决这个问题,同学们马上简单的统计了7位同学的相关特征,数据如下:
| 头发 | 声音 | 性别 |
|---|---|---|
| 长 | 粗 | 男 |
| 短 | 粗 | 男 |
| 短 | 粗 | 男 |
| 长 | 细 | 女 |
| 短 | 细 | 女 |
| 短 | 粗 | 女 |
| 长 | 粗 | 女 |
| 长 | 粗 | 女 |
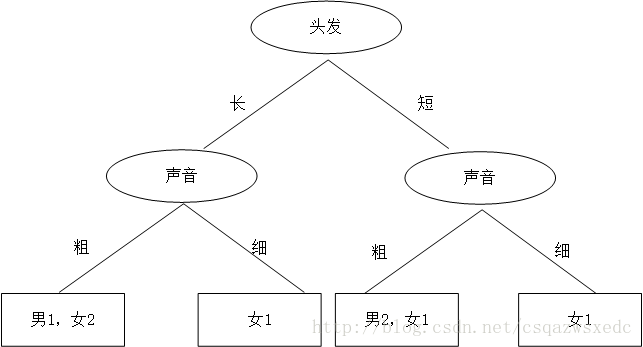
机智的同学A想了想,先根据头发判断,若判断不出,再根据声音判断,于是画了一幅图,如下:
于是,一个简单、直观的决策树就这么出来了。头发长、声音粗就是男生;头发长、声音细就是女生;头发短、声音粗是男生;头发短、声音细是女生。
原来机器学习中决策树就这玩意,这也太简单了吧。。。
这时又蹦出个同学B,想先根据声音判断,然后再根据头发来判断,如是大手一挥也画了个决策树:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









