







 本文介绍了卷积神经网络(CNN)的基本结构和层次,包括输入层、卷积层、激励层、池化层、归一化层等,并详细解释了卷积核的概念和参数共享。同时,探讨了Batch Normalization和Local Response Normalization的作用,以及Tensorflow中实现CNN的主要函数和参数说明。最后,展示了如何使用Tensorflow构建一个简单的CNN模型进行手写数字识别。
本文介绍了卷积神经网络(CNN)的基本结构和层次,包括输入层、卷积层、激励层、池化层、归一化层等,并详细解释了卷积核的概念和参数共享。同时,探讨了Batch Normalization和Local Response Normalization的作用,以及Tensorflow中实现CNN的主要函数和参数说明。最后,展示了如何使用Tensorflow构建一个简单的CNN模型进行手写数字识别。
一、CNN的引入
在人工的全连接神经网络中,每相邻两层之间的每个神经元之间都是有边相连的。当输入层的特征维度变得很高时,这时全连接网络需要训练的参数就会增大很多,计算速度就会变得很慢,例如一张黑白的 28×28 的手写数字图片,输入层的神经元就有784个,如下图所示:

若在中间只使用一层隐藏层,参数 w 就有
而在卷积神经网络(Convolutional Neural Network,CNN)中,卷积层的神经元只与前一层的部分神经元节点相连,即它的神经元间的连接是非全连接的,且同一层中某些神经元之间的连接的权重 w 和偏移
卷积神经网络CNN的结构一般包含这几个层:
- 输入层:用于数据的输入
- 卷积层:使用卷积核进行特征提取和特征映射
- 激励层:由于卷积也是一种线性运算,因此需要增加非线性映射
- 池化层:进行下采样,对特征图稀疏处理,减少数据运算量。
- 全连接层:通常在CNN的尾部进行重新拟合,减少特征信息的损失
- 输出层:用于输出结果
当然中间还可以使用一些其他的功能层:
- 归一化层(Batch Normalization):在CNN中对特征的归一化
- 切分层:对某些(图片)数据的进行分区域的单独学习
- 融合层:对独立进行特征学习的分支进行融合
二、CNN的层次结构
输入层:
在CNN的输入层中,(图片)数据输入的格式 与 全连接神经网络的输入格式(一维向量)不太一样。CNN的输入层的输入格式保留了图片本身的结构。
对于黑白的 28×28 的图片,CNN的输入是一个 28×28 的的二维神经元,如下图所示:
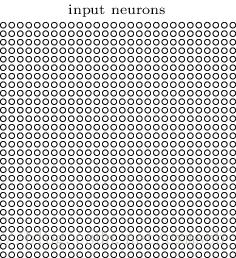
而对于RGB格式的 28×28 图片,CNN的输入则是一个 3×28×28 的三维神经元(RGB中的每一个颜色通道都有一个 28×28 的矩阵),如下图所示:

卷积层:
在卷积层中有几个重要的概念:
- local receptive fields(感受视野)
- shared weights(共享权值)
假设输入的是一个 28×28 的的二维神经元,我们定义 5×5 的 一个 local receptive fields(感受视野),即 隐藏层的神经元与输入层的 5×5 个神经元相连,这个5*5的区域就称之为Local Receptive Fields,如下图所示:

可类似看作:隐藏层中的神经元 具有一个固定大小的感受视野去感受上一层的部分特征。在全连接神经网络中,隐藏层中的神经元的感受视野足够大乃至可以看到上一层的所有特征。
而在卷积神经网络中,隐藏层中的神经元的感受视野比较小,只能看到上一次的部分特征,上一层的其他特征可以通过平移感受视野来得到同一层的其他神经元,由同一层其他神经元来看:

设移动的步长为1:从左到右扫描,每次移动 1 格,扫描完之后,再向下移动一格,再次从左到右扫描。
具体过程如动图所示:
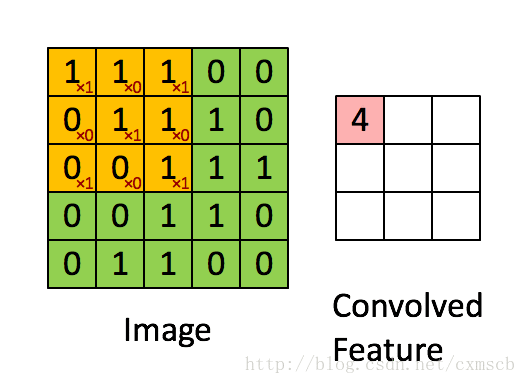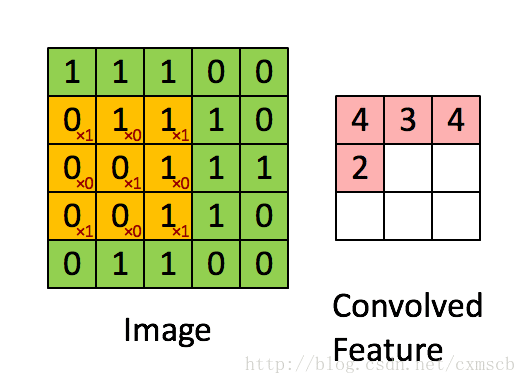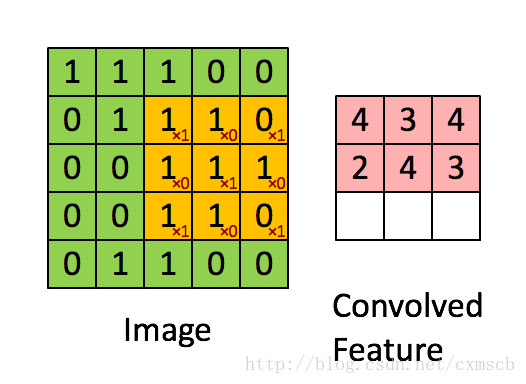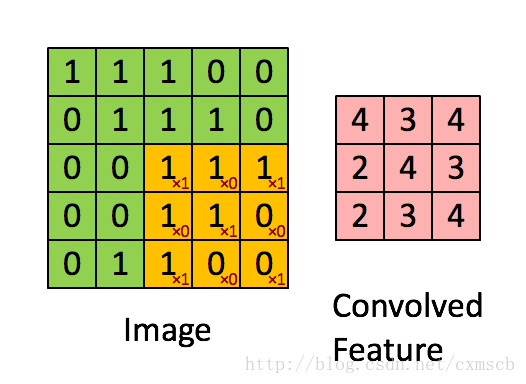

可看出 卷积层的神经元是只与前一层的部分神经元节点相连,每一条相连的线对应一个权重 w 。
一个感受视野带有一个卷积核,我们将 感受视野 中的权重
卷积核的大小由用户来定义,即定义的感受视野的大小;卷积核的权重矩阵的值,便是卷积神经网络的参数,为了有一个偏移项 ,卷积核可附带一个偏移项
因此 感受视野 扫描时可以计算出下一层神经元的值为:
对下一层的所有神经元来说,它们从不同的位置去探测了上一层神经元的特征。
我们将通过 一个带有卷积核的感受视野 扫描生成的下一层神经元矩阵 称为 一个feature map (特征映射图),如下图的右边便是一个 feature map:
因此在同一个 feature map 上的神经元使用的卷积核是相同的,因此这些神经元 shared weights,共享卷积核中的权值和附带的偏移。一个 feature map 对应 一个卷积核,若我们使用 3 个不同的卷积核,可以输出3个feature map:(感受视野:5×5,布长stride:1)
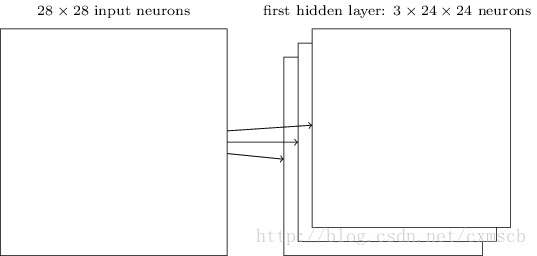
因此在CNN的卷积层,我们需要训练的参数大大地减少到了 (5×5+1)×3=78 个。
假设输入的是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 290
290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









