









深度学习之卷积神经网络
1、前言
在卷积神经网络之前,较流行的是多层感知机,多层感知机适合处理表格数据,其中行对应样本,列对应特征。对于表格数据,我们寻 找的模式可能涉及特征之间的交互,但是我们不能预先假设任何与特征交互相关的先验结构。此时,多层感知机可能是最好的选择,然而对于高维感知数据,这种缺少结构的网络可能会变得不实用。
多层感知机零实现和简易版的基本代码
# file:多层感知机零实现和简洁版.py
import torch
from d2l import torch as d2l
from torch import nn
# 1、导入数据
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 2、初始化模块,两层模型的权重和偏置初始化
num_inputs, num_outputs, num_hidden = 784, 10, 256
w1 = nn.Parameter(torch.randn(num_inputs, num_hidden, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hidden, requires_grad=True))
w2 = nn.Parameter(torch.randn(num_hidden, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [w1, b1, w2, b2]
# 3、定义relu函数
def relu(x):
a = torch.zeros_like(x)
return torch.max(x, a)
# 4、定义模型
def net(x):
x = x.reshape((-1, num_inputs))
H = relu(x @ w1 + b1)
return (H @ w2 + b2)
# 5、定义损失函数
loss = nn.CrossEntropyLoss(reduction='none')
# 6、进行模型训练
num_epochs, lr = 10, 0.1 # 确定迭代次数和学习率
updater = torch.optim.SGD(params=params, lr=lr) # 参数和学习率的选定
d2l.train_ch3(net=net, train_iter=train_iter, test_iter=test_iter, loss=loss, num_epochs=num_epochs,
updater=updater) # 模型训练
d2l.predict_ch3(net,test_iter=test_iter)
# file:多层感知机简洁版.py
import torch
from d2l import torch as d2l
from torch import nn
# 添加了2个全连接层(之前只添加了1个全连接层。第一层是隐藏层,它包含256个隐藏单元,并使用了ReLU激活函数。第二层是输出层,将数据平铺
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 10))
# 初始化权重
def init_weight(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight,std= 0.01)
# 使得这个容器应用该函数
net.apply(init_weight)
batch_size, lr, num_epochs = 256, 0.1, 10
# 获取数据
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 损失函数定义
loss = nn.CrossEntropyLoss(reduction='none')
# 优化策略,使用梯度下降
updater = torch.optim.SGD(net.parameters(), lr=lr)
#模型进行训练
d2l.train_ch3(net=net, train_iter=train_iter, test_iter=test_iter, loss=loss, num_epochs=num_epochs, updater=updater)
实际上,对于load_data_fashion_mnist这样的数据集,实际上该数据集是图像数据集,其中包含了70,000个灰度图像,每个图像大小为28x28像素,表示了10个类别的服装。尽管多层感知机可以处理这种图像数据(通过将其展平为一维向量),但通常我们不会直接将图像数据作为一维向量输入到多层感知机中,原因有以下几点:
-
空间信息丢失:将图像展平为一维向量会丢失图像中的空间结构信息,这对于理解图像内容是不利的。
-
计算效率:直接处理高维输入(如784维,对于28x28的图像)的多层感知机需要更多的计算资源,并且可能更容易出现过拟合。
-
模型性能:对于图像数据,卷积神经网络(Convolutional Neural Networks, CNNs)通常能提供更好的性能,因为它们能够利用图像中的局部空间结构,并通过卷积层自动提取特征。‘
2、CNN(卷积神经网络)
为了解决多层感知机在处理图像方面时的局限性,研究人员便引入了卷积神经网络(CNN)。
全连接层:在全连接层中,当前层的每个神经元都与前一层的所有神经元相连接。这种连接方式意味着如果前一层有n个神经元,当前层有m个神经元,那么两层之间将有n*m个权重参数,以及m个偏置参数(如果考虑偏置的话)。
卷积层:在CNN中,卷积操作是通过一个可学习的卷积核(或称为滤波器)在输入数据(通常是多维数组,如图像)上滑动并进行加权求和来完成的。每个卷积核都负责检测输入数据中的特定特征,如边缘、纹理等。卷积操作具有两个关键特性:局部连接和权重共享。
1、图像卷积
1)互相关计算
核函数:通常被称为卷积核(Convolution Kernel)或滤波器(Filter),是CNN中的一个关键组成部分。卷积核在CNN中扮演着特征提取器的角色,通过在输入数据(如图像)上进行滑动窗口操作,执行卷积运算来提取图像中的局部特征。
补充:图像一般包含三个通道/三种原色(红色、绿色和蓝色)。实际上,图像不是二维张量,而是一个由高度、宽度和颜色组成的三维张量,比如包含1024 × 1024 × 3个像素。前两个 轴与像素的空间位置有关,而第三个轴可以看作每个像素的多维表示。因此,我们将X索引为[X]i,j,k。由此卷积相应地调整为[V]a,b,c,而不是[V]a,b。
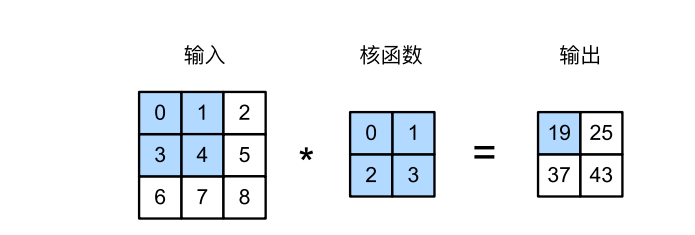
图1
输入是高度为3、宽度为3的二维张量(即形状为3 × 3)。卷积核的高度和宽度都是2,而卷积核窗口(或卷积窗口) 的形状由内核的高度和宽度决定(即2 × 2)。实际上,输入是照片的像素,暂不将照片看成三维(即通道)。
二维互相关运算中,阴影部分是第一个输出元素,以及用于计算输出的输入张量元素和核张量元素: 0 × 0 + 1 × 1 + 3 × 2 + 4 × 3 = 19,以此类推,计算出输出张量的四个元素。
0 × 0 + 1 × 1 + 3 × 2 + 4 × 3 = 19, 1 × 0 + 2 × 1 + 4 × 2 + 5 × 3 = 25,
3 × 0 + 4 × 1 + 6 × 2 + 7 × 3 = 37, 4 × 0 + 5 × 1 + 7 × 2 + 8 × 3 = 43.
理论理解后,则通过代码来实现该功能。
# X表示原函数,W表示卷积层的核函数,权重函数
import torch
def cord(X, W):
h, w = X.shape # 矩阵X的长和宽
h1, w1 = W.shape # 矩阵W的长和宽
# 默认步长为1,边缘填充为0,计算需要填充的长和宽
h2, w2 = h - h1 + 1, w - w1 + 1
# 定义长h2,宽w2,初始化全为零的矩阵
y = torch.zeros((h2, w2))
# 先行遍历,再列遍历
for i in range(w2):
for j in range(h2):
y[i, j] = (X[i:i + h1, j:j + w1] * W).sum()
return y
X = torch.tensor([
[1, 1, 1, 0, 0],
[0, 1, 1, 1, 0],
[0, 0, 1, 1, 1],
[0, 0, 1, 1, 0],
[0, 1, 1, 0, 0]])
K = torch.tensor([[1,0,1], [0,1,0],[1,0,1]])
result = cord(X, K)
print(result)
# 输出结果
tensor([[4., 3., 4.],
[2., 4., 3.],
[2., 3., 4.]])
2)学习卷积核
针对于上文中的K(滤波器)是给定的参数,但是在卷积神经网络中,我们希望这个参数只需要给定初始值,在模型训练过程中,不断更新其参数。当有了更复杂数值的卷积核,或者连续的卷积层时,我们不可能手动设计滤波器。那么我们是否可以学习由X生成Y的卷积核呢? 现在让我们看看是否可以通过仅查看“输入‐输出”对来学习由X生成Y的卷积核。先构造一个卷积层,并 将其卷积核初始化为随机张量。接下来,在每次迭代中,我们比较Y与卷积层输出的平方误差,然后计算梯度来更新卷积核。为了简单起见,在此使用内置的二维卷积层,并忽略偏置。
import torch
from torch import nn
def cord(X, K):
# 计算两个矩阵实现互算,X是随机矩阵,K是权重
h, d = K.shape
# 假设每次步长为1,零补充为零
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - d + 1))
# 循环遍历整个Y并与K相乘
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i + h, j:j + d] * K).sum()
return Y
# 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核
conv2d = nn.Conv2d(1, 1, kernel_size=(1, 2), bias=False)
# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
# 其中批量大小和通道数都为1
X = torch.ones((6, 8))
X[:, 2:6] = 0
# 真实参数为k1.0 -1.0
K = torch.tensor([[2.0, -2.0]])
Y = cord(X, K)
x = X.reshape((1, 1, 6, 8))
y = Y.reshape((1, 1, 6, 7))
etha = 3e-2 # 学习率
for i in range(50):
# 获得随机的参数
y_hat = conv2d(x)
# 使用均方差计算loss损失函数
loss = (y_hat - y) ** 2
# 梯度归零
conv2d.zero_grad()
# 反向传播
loss.sum().backward()
# 更新权重
conv2d.weight.data[:]-=etha*conv2d.weight.grad
if (i+1)%2==0:
print(f'epoch:{i+1},loss:{loss.sum():.4f},weight:{conv2d.weight.data}')
# 通过训练后得到的k
print(conv2d.weight.data.reshape(1,2))
**补充:**互相关运算(卷积)是通过卷积核将输入图片通过卷积层转换为输出特征图,实现了从输入x(即输入特征图)到输出y(即输出特征图)的转换,并在此过程中完成了特征提取的任务。实际上,当卷积核在输入特征图上滑动时,它会与输入特征图上的局部区域(即感受野)进行逐元素的乘法和加法运算(实际上是互相关运算),从而生成输出特征图上的一个元素。这个过程会重复进行,直到卷积核遍历了整个输入特征图,从而生成完整的输出特征图。
图2
3)填充和步幅
在经过一次卷积层后,是否会有注意到边缘数据只访问了一次,而中间的数据访问了多次?如图1中,以第一行为例,0,2作为边缘数据只访问到了一次,而1作为中间数据访问了两次,这样是否会对特征提取有影响呢?答案固然是有影响的,每经过一次卷积层,边缘数据便会少算一次,那经过多层卷积层,就会损失很多边缘信息,这对后续特征提取以及池化层造成不可挽回的后果。
那如何解决边缘数据缺失的问题呢?解决这个问题的简单方法即为填充(padding):在输入图像的边界填充元素(通常填充元素是0)例如,在 图3中, 我们将3×3输入填充到5×5,那么它的输出就增加为4×4。阴影部分是第一个输出元素以及用于输出计算 的输入和核张量元素:0×0+0×1+0 ×2+0×3 = 0。
在前面的例子中,我们默认每次滑动一个元素。但是,有时候为了高效计算或是缩减采样次数,卷积窗口可以跳过中间位置,每次滑动多个元素。 我们将每次滑动元素的数量称为步幅(stride)。到目前为止,我们只使用过高度或宽度为1的步幅,那么如何使用较大的步幅呢?则是调整stride的大小,使得它一次可跳过多个像素点运算。
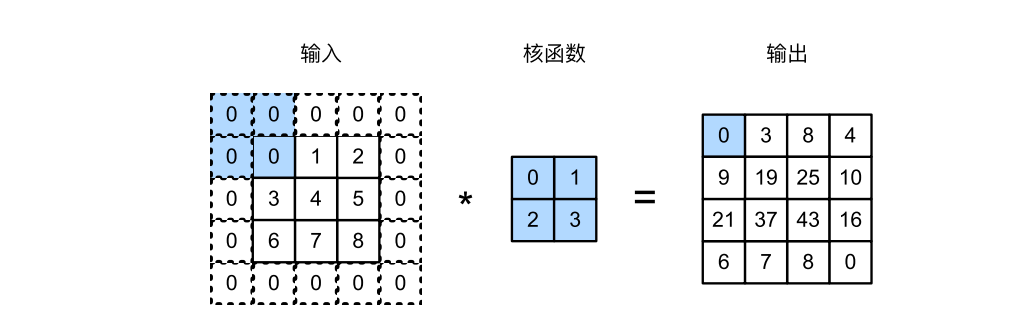
代码实现:
import torch
import torch.nn.functional as F
# padding表示外围零填充的次数,stride表示步幅,默认零填充为1,步幅为1
def cord(X, K, padding=1,stride=1):
h, d = K.shape
x_h, x_d = X.shape
x_h1 = int((x_h + padding * 2 - h )/stride+1)
x_d1 = int((x_d + padding * 2 - d )/stride+1)
# 零填充
X_padded = F.pad(X, (padding, padding, padding, padding), mode='constant', value=0)
print(X_padded)
Y = torch.zeros((x_h1, x_d1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X_padded[i*stride:i*stride + h, j*stride:j*stride + d] * K).sum()
return Y
X = torch.arange(0, 9).reshape(3, 3)
K = torch.arange(0, 4).reshape(2, 2)
# 默认padding=1,stride=1
print(cord(X,K))
# 默认padding=1,stride=2
print(cord(X, K,stride=2))
# 输出结果
tensor([[ 0., 3., 8., 4.],
[ 9., 19., 25., 10.],
[21., 37., 43., 16.],
[ 6., 7., 8., 0.]])
tensor([[ 0., 8.],
[21., 43.]])
简便方法
直接在conv2d中定义卷积核大小,padding大小,stride大小。输入数据的规格是8x8的,输出规格也是8x8的,在该实例中padding=1,stride=1,假设输入规格的高为x_h,输出规格的高为 y h y_h yh,卷积核的高为 k h k_h kh,经过计算可知
$y_h= \left\lceil \frac{x_h + 2 \times \text{padding} - k_h}{\text{stride}}\right\rceil + 1 $
import torch
from torch import nn
# 为了方便起见,我们定义了一个计算卷积层的函数。
# 此函数初始化卷积层权重,并对输入和输出提高和缩减相应的维数
def comp_conv2d(conv2d, X):
# 这里的(1,1)表示批量大小和通道数都是1
X = X.reshape((1, 1) + X.shape)
Y = conv2d(X)
# 省略前两个维度:批量大小和通道
return Y.reshape(Y.shape[2:])
# 请注意,这里每边都填充了1行或1列,因此总共添加了2行或2列
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1,stride=1)
X = torch.rand(size=(8, 8))
print(X.shape)
Y=comp_conv2d(conv2d, X)
print(Y.shape)
# 输出
torch.Size([8, 8])
torch.Size([8, 8])
2、多输入多输出通道
目前为止,仅展示了单个输入和单个输出通道的简单例子,这样使得我们可以将输入、卷积核和输出作为二维张量进行运算。但实际上,彩色图像具有标准的RGB图像来表示红、绿、蓝。当我们添加通道时,我们的输入和隐藏的表示都变成了三维张量。例如,每个RGB输入图像具有3 × h × w的 形状。我们将这个大小为3的轴称为通道(channel)维度。本节将更深入地研究具有多输入和多输出通道的卷积核。
1)多输入通道
当输入包含多个通道时,需要构造一个与输入数据具有相同输入通道数的卷积核,以便与输入数据进行互相关运算。假设输入的通道数为 c i c_i ci,那么卷积核的输入通道数也需要为 c i c_i ci。如果卷积核的窗口形状是 k h k_h kh × k w k_w kw,那么当 c i c_i ci = 1时,我们可以把卷积核看作形状为 k h k_h kh × k w k_w kw的二维张量。
# 多输入,假设只有一个通道
import torch
from d2l import torch as d2l
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
def mult(X,K):
return sum(d2l.corr2d(x,k) for x,k in zip(X,K))
print(mult(X,K))
#实际上corr2d的底层逻辑与二维互相关运算类似,两种操作都考研
def cord(X, W):
h, w = X.shape # 矩阵X的长和宽
h1, w1 = W.shape # 矩阵W的长和宽
# 默认步长为1,边缘填充为0,计算需要填充的长和宽
h2, w2 = h - h1 + 1, w - w1 + 1
# 定义长h2,宽w2,初始化全为零的矩阵
y = torch.zeros((h2, w2))
# 先行遍历,再列遍历
for i in range(w2):
for j in range(h2):
y[i, j] = (X[i:i + h1, j:j + w1] * W).sum()
return y
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
def mult(X,K):
return sum(cord(x,k) for x,k in zip(X,K))
print(mult(X,K))
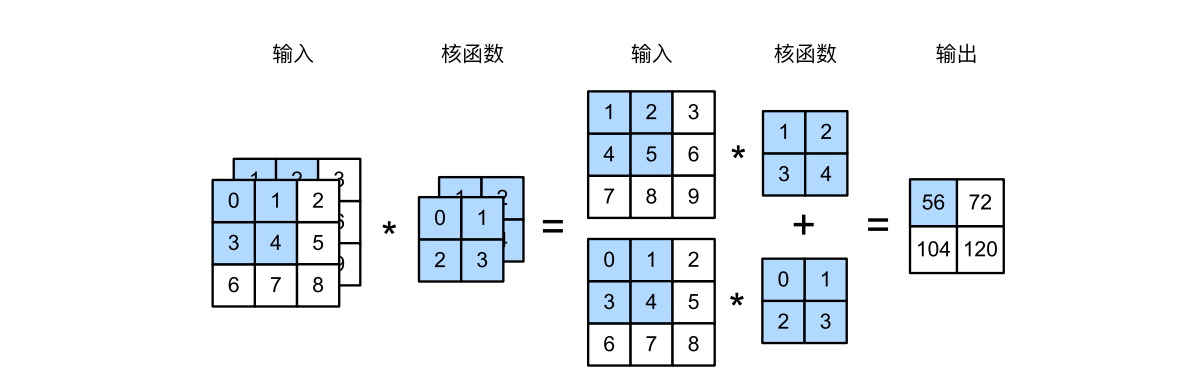
2)多输出通道
到目前为止,不论有多少输入通道,我们还只有一个输出通道。在最流行的神经网络架构中,随着神经网络层数的加深,我们常会增加输出通道的维数,通过减少空间分辨率以获得更大的通道深度。直观地说,我们可以将每个通道看作对不同特 征的响应。而现实可能更为复杂一些,因为每个通道不是独立学习的,而是为了共同使用而优化的。因此,多 输出通道并不仅是学习多个单通道的检测器。
用 c i c_i ci和 c o c_o co分别表示输入和输出通道的数目,并让 k h k_h kh和 k w k_w kw为卷积核的高度和宽度。为了获得多个通道的输出,我 们可以为每个输出通道创建一个形状为 c i × k h × k w c_i × k_h × k_w ci×kh×kw的卷积核张量,这样卷积核的形状是 c o × c i × k h × k w c_o × c_i × k_h × k_w co×ci×kh×kw。在 互相关运算中,每个输出通道先获取所有输入通道,再以对应该输出通道的卷积核计算出结果。
# 多通道
def corr2d_mult2(X, K):
# 迭代“K”的第0个维度,每次都对输入“X”执行互相关运算。
# 最后将所有结果都叠加在一起
return torch.stack([mult(X, k) for k in K], 0)
# 将原来的一个通道转换为三通道
K = torch.stack((K, K + 1, K + 2), 0)
# 每增加一个通道,将里面的数加1
print(K)
# K的四维表示
print(K.shape)
# 运算结果
print(corr2d_mult2(X,K))
"""
输出结果:
tensor([[[[0., 1.],
[2., 3.]],
[[1., 2.],
[3., 4.]]],
[[[1., 2.],
[3., 4.]],
[[2., 3.],
[4., 5.]]],
[[[2., 3.],
[4., 5.]],
[[3., 4.],
[5., 6.]]]])
torch.Size([3, 2, 2, 2])
tensor([[[ 56., 72.],
[104., 120.]],
[[ 76., 100.],
[148., 172.]],
[[ 96., 128.],
[192., 224.]]])
"""
多输入多输出通道可以用来扩展卷积层的模型。
3、汇聚层(池化层)
通常当我们处理图像时,我们希望逐渐降低隐藏表示的空间分辨率、聚集信息,这样随着我们在神经网络中层叠的上升,每个神经元对其敏感的感受野(输入)就越大。
感受野解释:
卷积神经网络中,越深层的神经元看到的输入区域越大,如下图所示,kernel_size 均为3×3,stride均为1,绿色标记的是Layer2每个神经元看到的区域,黄色标记的是Layer3 看到的区域,具体地,Layer2每个神经元可看到Layer1上3×3 大小的区域,Layer3 每个神经元看到Layer2 上3×3 大小的区域,该区域可以又看到Layer1上5×5 大小的区域。
简单讲:Layer3中的黄色数据由Layer2黄色数据而来,Layer2的3x3黄色区域来自于LAYER1的5x5黄色数据,Layer2中的绿色数据由Layer1绿色数据而来。由此,对于Layer3黄块而言,它在Layer2感受野为3x3黄色区,在Layer1感受野为5x5黄色区。
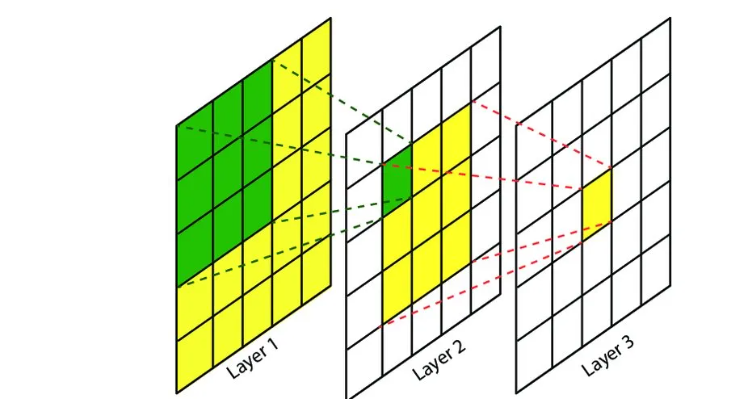
而我们的机器学习任务通常会跟全局图像的问题有关(例如,“图像是否包含一只猫呢?”),所以我们最后一层的神经元应该对整个输入的全局敏感。通过逐渐聚合信息,生成越来越粗糙的映射,最终实现学习全局表示的目标,同时将卷积图层的所有优势保留在中间层。
最大汇聚层和平均汇聚层
与卷积层类似,汇聚层(池化层)运算符由一个固定形状的窗口组成,该窗口根据其步幅大小在输入的所有区域上滑动, 为固定形状窗口(有时称为汇聚窗口)遍历的每个位置计算一个输出。然而,不同于卷积层中的输入与卷积核之间的互相关计算,汇聚层不包含参数。相反,池运算是确定性的,我们通常计算汇聚窗口中所有元素的最大值或平均值。这些操作分别称为最大汇聚层(maximum pooling)和平均汇聚层(average pooling)。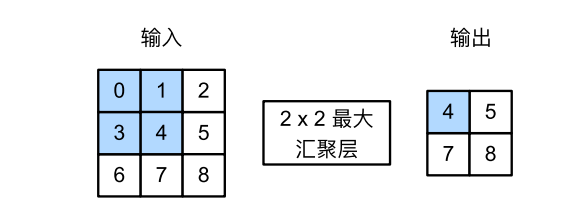
汇聚窗口形状为 2 × 2 的最大汇聚层。着色部分是第一个输出元素,以及用于计算这个输出的输入元素: max(0, 1, 3, 4) = 4。这四个元素为每个汇聚窗口中的最大值:
max(0, 1, 3, 4) = 4, max(1, 2, 4, 5) = 5,
max(3, 4, 6, 7) = 7, max(4, 5, 7, 8) = 8。
汇聚窗口形状为p × q的汇聚层称为p × q汇聚层,汇聚操作称为p × q汇聚。
最大汇聚层:每次选择汇聚窗口p x q内最大值
平均汇聚层:将汇聚窗口 p x q中所有数据加在一起,求平均数后作为输出数据
最大汇聚
优势:
- 特征保留:能够很好地保留图像中的显著特征,如边缘和纹理,这对于目标检测和边缘检测等任务非常有用。
- 平移不变性:由于只关注最大值,因此对图像中的小位移具有较好的鲁棒性。
劣势:
- 信息损失:在池化过程中,非最大值的信息会被丢弃,可能导致部分有用信息的损失。
平均汇聚
优势:
- 背景保留:能够保留图像中的背景信息,减少噪声的干扰,对于图像分类和模式识别等任务效果较好。
- 平滑效果:通过计算平均值,可以平滑图像特征,减少图像中的突变和噪声。
劣势:
- 细节模糊:由于平均汇聚会平滑图像特征,因此可能会使图像中的细节变得模糊。
代码实现
import torch
def pool2d(X, pool_size, mode='max'):
# 确保输入是浮点数
X = X.float()
pool_h, pool_w = pool_size
Y = torch.zeros(X.shape[0] - pool_h + 1, X.shape[1] - pool_w + 1)
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i:i + pool_h, j:j + pool_w].max()
if mode == 'avg':
Y[i, j] = X[i:i + pool_h, j:j + pool_w].mean()
return Y
X = torch.arange(0, 9).reshape(3, 3)
print(X)
result=pool2d(X,(2,2))
print(result)
result=pool2d(X,(2,2),'avg')
print(result)
"""
输出结果
tensor([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
tensor([[4., 5.],
[7., 8.]])
tensor([[2., 3.],
[5., 6.]])
"""
池化层也具有填充和步幅、多通道等特性,在此不过多讲解。
3、cnn总结
CNN(Convolutional Neural Network,卷积神经网络)是一种特殊的神经网络,特别适用于处理具有网格结构的数据,如图像数据。
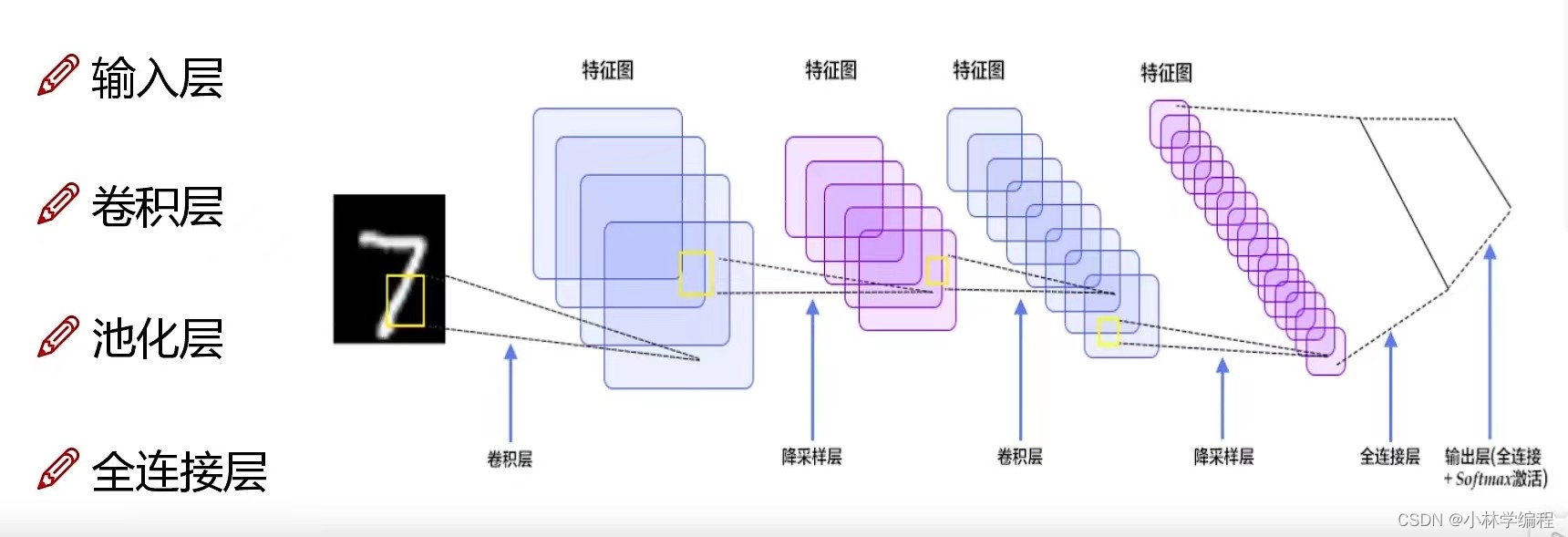
1一、CNN的基本组成
CNN主要由以下几个部分组成:
- 卷积层(Convolutional Layer)
- 功能:负责提取图像中的局部特征。
- 特点:
- 平移不变性:无论特征在图像中的哪个位置,卷积层都能识别出来。
- 局部性:卷积层只关注图像的局部区域,通过多个卷积核来提取不同的特征。
- 运算方式:卷积层通过对输入图像和卷积核进行互相关运算(实际上,在深度学习中,卷积运算通常被实现为互相关运算,因为它们在数学上是等价的,且互相关运算更容易实现),并加上偏置项,得到输出特征图(Feature Map)。
- 池化层(Pooling Layer) 也可认为是降采样层
- 功能:用于降低数据的维度,减少计算量,同时保留重要特征。
- 常见的池化方式:
- 最大池化(Max Pooling):选取每个池化区域内的最大值作为输出。
- 平均池化(Average Pooling):计算每个池化区域内的平均值作为输出。
- 全连接层(Fully Connected Layer)
- 功能:将前面层提取的特征进行整合,并通过分类器(如softmax)进行分类或识别。
- 特点:全连接层的每个神经元都与前一层的所有神经元相连,因此参数数量较多,容易产生过拟合现象。
2、CNN的工作原理
CNN通过前向传播和反向传播两个过程来训练模型:
- 前向传播
- 输入图像经过多个卷积层和池化层的堆叠处理,逐步提取出图像的高级特征。
- 提取的特征被送入全连接层进行分类或识别。
- 最终,全连接层的输出即为CNN的预测结果。
- 反向传播
- 根据预测结果与实际值之间的误差,计算损失函数的梯度。
- 通过链式法则将梯度逐层反向传播至卷积层和全连接层。
- 根据梯度信息更新各层的参数,以减小损失函数的值。















 3164
3164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









