







1、oracle 的日志分3类:
警告日志-=Alert log files ;
跟踪日志--Trace files用户和进程);
重做日志--redo log 录数据库的更改)。
redo log file 重做日志文件,包括:
归档(archive)重做日志文件---------归档重做日志,简称归档日志,指当条件满足时,Oracle将在线重做日志以文件形式保存到硬盘(持久化)
在线(online)重做日志文件 -------又称联机重做日志,指Oracle以SQL脚本的形式实时记录数据库的数据更新,换句话说,实时保存已执行的SQL脚本到在线日志文件中(按特定的格式)。
Oracle 11g默认对于每个数据库实例,建立3个在线日志组,每组一个日志文件,文件名称为REDO01.LOG,REDO02.LOG和REDO03.LOG。(用户可以通过视图操作添加/修改/删除日志组和日志文件来自定义在线重做日志)
每组内的日志成员文件的内容完全相同,且保存在不同的位置,用于磁盘日志镜像,以做多次备份提高安全性。默认情况这3组通常只有一组处于活动状态,不断地同步写入已操作的脚本,当日志文件写满时(达到指定的空间配额),如果当前数据库处于归档模式,则将在线日志归档到硬盘,成为归档日志;若当前数据库处于非归档模式,则不进行归档操作,而当前在线日志的内容会被下一次重新写入覆盖而无法保存。因此,通常数据库在运行时,是处于归档模式下的,以保存数据更新的日志。
当前归档日志组写满后,Oracle会切换到下一日志组,继续写入,就这样循环切换;当处于归档模式下,切换至原已写满的日志组,若该日志组归档完毕则覆盖写入,若没有则只能使用日志缓冲区,等待归档完毕之后才能覆盖写入。当然,处于非归档模式下是直接覆盖写入的。
Oracle提供了2个视图用于维护在线重做日志:V$LOG和V$LOGFILE,我们可以通过这两个视图查看和修改在线日志。
关于V$LOG视图的详细属性字段可Oracle 11g的官方文档:
http://download.oracle.com/docs/cd/B28359_01/server.111/b28320/dynviews_2029.htm
关于V$LOGFILE视图的详细属性字段可Oracle 11g的官方文档:
http://download.oracle.com/docs/cd/B28359_01/server.111/b28320/dynviews_2031.htm
通过v$logfile视图查询在线日志文件信息:
SQL> SELECT * FROM v$logfile ORDER BY group#;
GROUP# TATUS TYPE MEMBER IS_RECOVERY_DEST_FILE
1 ONLINE E:\APP\ADMINISTRATOR\ORADATA\ORCL\REDO01.LOG NO
2 ONLINE E:\APP\ADMINISTRATOR\ORADATA\ORCL\REDO02.LOG NO
3 ONLINE E:\APP\ADMINISTRATOR\ORADATA\ORCL\REDO03.LOG NO
通过v$log视图查询在线日志的总体信息:
SQL> SELECT * FROM v$log;
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARCHIVED STATUS FIRST_CHANGE# FIRST_TIME
1 1 49 52428800 1 NO CURRENT 1466615 07-1月 -11
2 1 47 52428800 1 YES INACTIVE 1434125 06-1月 -11
3 1 48 52428800 1 YES INACTIVE 1460403 07-1月 -11
当然,还可以通过ALTER DATABASE ADD 、delete等命令增加/修改/删除在线日志或日志组,具体操作可查看http://blog.csdn.net/changyanmanman/article/details/7295502
重做日志的简单原理:在数据更新操作commit前,将更改的SQL脚本写入重做日志。主要用于数据库的增量备份和增量恢复。 重做日志直接对应于硬盘的重做日志文件(有在线和归档二种),重做日志文件以组(Group)的形式组织,一个重做日志组包含一个或者多个日志文件。
如果数据库所在主机掉电,导致实例失败,Oracle 会使用在线重做日志将系统恰好恢复到掉电之前的那个时间点(实例恢复)。
如果磁盘驱动器出现故障(这是一个介质失败),Oracle 会使用归档重做日志以及在线重日志将该驱动器上的数据备份恢复到适当的时间点。
另外,如果你“无意地”截除了一个表,或者删除了某些重要的信息,然后提交了这个操作,那么可以恢复受影响数据的一个备份,并使用在线和归档重做日志文件把它恢复到这个“意外”发生前的时间点。
归档重做日志文件实际上就是已填满的“旧”在线重做日志文件的副本。系统将日志文件填满时,ARCH进程会在另一个位置建立在线重做日志文件的一个副本,也可以在本地和远程位置上建立多个另外的副本。如果由于磁盘驱动器损坏或者其他物理故障而导致失败,就会用这些归档重做日志文件来执行介质恢复。Oracle 拿到这些归档重做日志文件,并把它们应用于数据文件的备份,使这些数据文件能“赶上”数据库的其余部分。归档重做日志文件是数据库的事务历史。
要查看生成的redo 量相当简单,。我使用了SQL*Plus 的内置特性AUTOTRACE。不过AUTOTRACE 只能用于简单的DML,对其他操作就力所不能及了,例如,它无法查看一个存储过程调用做了什么。为此,我们需要访问两个动态性能视图:
V$MYSTAT:其中有会话的提交信息。
V$STATNAME:这个视图能告诉我们V$MYSTAT 中的每一行表示什么(所查看的统计名)。
2、redo和undo是如何协作的:
先说一个有意思的问题,undo信息存储在undo表空间和undo段中,但是他们也收到redo的保护,什么意思呢?就是说,undo信息的写入,修改也会通过redo日志记录下来。oracle数据库会把undo信息当做表数据或者索引数据一样来使用,将undo数据增加到undo段中,也会用到数据缓冲区的缓存。
下面具体分析一个操作过程,下面三句语句挨着执行:
insert into t (x,y) valus(1,1);
update t set x=x+1 where x=1;
delete from t where x=2;
对于第一条语句,执行插入后,其系统状态如图所示:
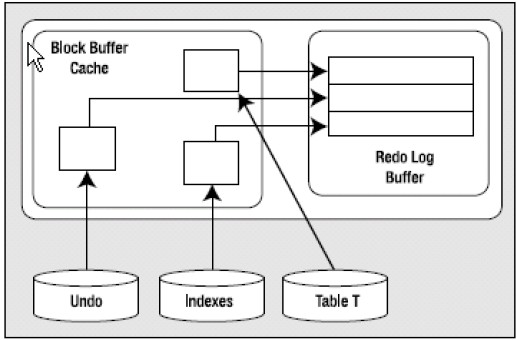
这里数据缓存里有一些应经修改的索引,表,还有undo块,此时在redo log 缓存里创建了对应的保护条目。
假想场景:此时系统崩溃。。。
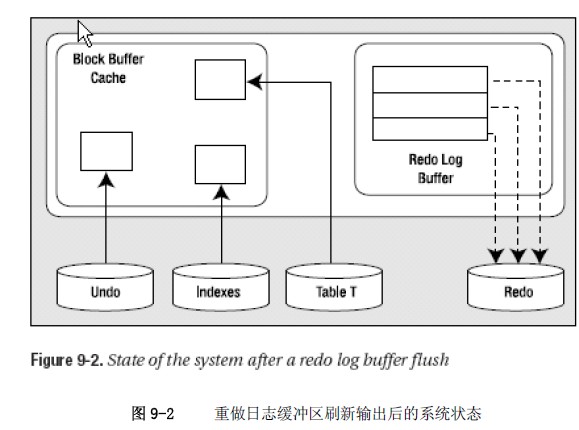
若此时系统崩溃,没有执行提交,也没有隐式提交,oracle将刷新SGA,此时的redo log还没有提交,数据更没有刷新输出到磁盘上,所以此时崩溃,根本不需要(也没有办法)来进行redo或者undo的恢复,就相当于这句话还没有执行。
假想场景:缓冲区缓存现在已经满了。。。
update t set x=x+1 where x=1;
update所带来的工作与insert大体一样,不过update生成的undo量更大,由于需要更新,所以需要将之前的映像也保存下来。
块缓冲区缓存中会有更多新的undo 段块。为了撤销这个更新,如果必要,已修改的数据库表和索引块也会放在缓存中。我们还生成了更多的重做日志缓存区条目。下面假设前面的插入语句生成了一些重做日志,其中有些重做日志已经刷新输出到磁盘上,有些还放在缓存中。
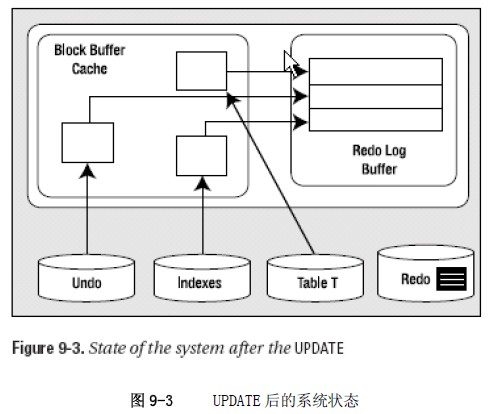
假想场景:此时系统崩溃。。。
撤销段在撤销表空间中,这个表空间是在oracle创建数据库时分配好的,重启的时候oracle首先去读取重做日志(redo log),找到你对应事务的重做日志条目,这时,再根据当前系统的状态,首先会前滚,注意是前滚,例如这个事务从9点执行到10点,本打算在10点提交,可是9:50系统崩了,可能重做日志归档到了9点45之前的,但是数据缓冲区中的数据块还没有写到磁盘上,磁盘上可能才写到9点40的时候的数据块,这个时候重启数据库,首先要前滚数据,即从9:40滚到9:45.滚到9点45一看,他妈的原来还有一些事务没提交(注意,也有一些事务已经提交了,那就不用管了,也不用回滚了),唉。。那就再把没有提交的事务回滚吧,这时,oracle数据库利用刚才前滚在数据缓冲区构建的undo块(如果不够,还有undo表空间里的undo块也调进来),把数据恢复到这是事务开始的时候,就是9点的时候。
至于你说的原理,我个人觉得都对,我上面一段话就是你说的第二种说法,第一种说法是跟深层的解释,我在上文中说了一句“如果不够,还有undo表空间里的undo块也调进来”那具体怎么调进来呢?就是你说的,将那些undo块对应的事务标记为dead,然后再去回滚这个事务。。。
看下面的一个提问:我在上面给他做的回答。。
实例失败后,未提交的事务是要用undo来回滚的,回滚的数据来自撤销段,撤销段来自谁?
在网上查了一下,
第一种说法:撤销数据放在撤销段中,撤销段中标记这个事务将仍为激活状态,在数据库重新启动过程中,后台进程SMON会扫描undo segment header,将发现上面的执行语句还是处于激活状态,于是, 将这些未提交的活动事务标志为dead。数据库后,后台进程SMON发现dead事务,根据情况去逐步回滚。
第二种说法:利用redo中写入的undo数据进行回滚?哪一个正确?
3、commit工作到底做了什么?
为什么COMMIT 的响应时间相当“平”,而不论事务大小呢?在数据库中执行COMMIT 之前,困难的工作都已经做了。我们已经修改了数据库中的数据,所以99.9%的工作都已经完成。例如,已经发生了以下操作:
已经在SGA 中生成了undo 块。
已经在SGA 中生成了已修改数据块。
已经在SGA 中生成了对于前两项的缓存redo。
取决于前三项的大小,以及这些工作花费的时间,前面的每个数据(或某些数据)可能已经刷新输出到磁盘。已经得到了所需的全部锁。
执行commit要进行如下工作:
为事务生成一个SCN(如果你还不熟悉SCN,起码要知道,SCN 是Oracle 使用的一种简单的计时机制,用于保证事务的顺序,并支持失败恢复。SCN 还用于保证数据库中的读一致性和检查点。可以把SCN 看作一个钟摆,每次有人COMMIT 时,SCN 都会增1) 在为该事务指定的回退段中的内部事务表内记录下这个事务已经被提交,并且生成一个惟一的SCN记录在内部事务表中,用于惟一标识这个事务。 (可以这么理解,就是在undo段里有一个内部事务表,什么是事务表呢?可以看看这个参考:在rollback undo 回退段中的数据是以“回退条目”方式存储(undo段内的存储方式)。回退条目=块信息(在事务中发生改动的块的编号)+在事务提交前存储在块中的数据(原数据) 在每一个回退段中oracle都为其维护一张“事务表”(每个undo段都有一张事务表) 在事务表中记录着与该回退段中所有回退条目相关的事务编号(事务SCN&回退条目) redo 重做记录由一组“变更向量”组成。每个变更变量中记录了事务对数据库中某个块所做的修改。)
LGWR 将所有余下的缓存重做日志条目写到磁盘,并把SCN 记录到在线重做日志文件中。这一步就是真正COMMIT。如果出现了这一步,即已经提交。事务条目会从V$TRANSACTION 中“删除”,这说明我们已经提交。
V$LOCK 中记录这我们的会话持有的锁,这些所都将被释放,而排队等待这些锁的每一个人都会被唤醒,可以继续完成他们的工作。
如果事务修改的某些块还在缓冲区缓存中,则会以一种快速的模式访问并“清理”。块清除(Block cleanout)是指清除存储在数据库块首部的与锁相关的信息。实质上讲,我们在清除块上的事务信息,这样下一个访问这个块的人就不用再这么做了。我们采用一种无需生成重做日志信息的方式来完成块清除,这样可以省去以后的大量工作(在下面的“块清除”一节中将更全面地讨论这个问题)。
可以看到,处理COMMIT 所要做的工作很少。其中耗时最长的操作要算LGWR 执行的活动(一般是这样),因为这些磁盘写是物理磁盘I/O。不过,这里LGWR 花费的时间并不会太多,之所以能大幅减少这个操作的时间,原因是LGWR 一直在以连续的方式刷新输出重做日志缓冲区的内容。在你工作期间,LGWR 并非缓存这你做的所有工作;实际上,随着你的工作的进行,LGWR 会在后台增量式地刷新输出重做日志缓冲区的内容。这样做是为了避免COMMIT 等待很长时间来一次性刷新输出所有的redo。
因此,即使我们有一个长时间运行的事务,但在提交之前,它生成的许多缓存重做日志已经刷新输出到磁盘了(而不是全部等到提交时才刷新输出)。这也有不好的一面,COMMIT 时,我们必须等待,直到尚未写出的所有缓存redo 都已经安全写到磁盘上才行。也就是说,对LGWR 的调用是一个同步(synchronous)调用。尽管LGWR 本身可以使用异步I/O 并行地写至日志文件,但是我们的事务会一直等待LGWR 完成所有写操作,并收到数据都已在磁盘上的确认才会返回。
我说过,LGWR 是一个同步调用,我们要等待它完成所有写操作。在Oracle 10g Release 1 及以前版本中,除PL/SQL 以外的所有编程语言都是如此。PL/SQL 引擎不同,要认识到直到PL/SQL 例程完成之前,客户并不知道这个PL/SQL 例程中是否发生了COMMIT,所以PL/SQL 引擎完成的是异步提交。它不会等待LGWR 完成;相反,PL/SQL 引擎会从COMMIT 调用立即返回。不过,等到PL/SQL 例程完成,我们从数据库返回客户时,PL/SQL 例程则要等待LGWR 完成所有尚未完成的COMMIT。因此,如果在PL/SQL 中提交了100 次,然后返回客户,会发现由于存在这种优化,你只会等待LGWR 一次,而不是100 次。这是不是说可以在PL/SQL 中频繁地提交呢?这是一个很好或者不错的主意吗?不是,绝对不是,在PL/SQ;中频繁地提交与在其他语言中这样做同样糟糕。指导原则是,应该在逻辑工作单元完成时才提交,而不要在此之前草率地提交。
4、rollback工作到底做了什么?
Oracle通过使用undo段中的undo条目,撤销事务中所有SQL语句对数据库所做的修改,其完成方式如下:
从undo 段读回数据,然后实际上逆向执行前面所做的操作,并将undo 条目标记为已用。如果先前插入了一行,ROLLBACK 会将其删除。如果更新了一行,回滚就会取消更新。如果删除了一行,回滚将把它再次插入。会话持有的所有锁都将释放,如果有人在排队等待我们持有的锁,就会被唤醒。














 3730
3730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









