







驱动程序完全隐藏了设备工作的细节. 用户的活动通过一套标准化的调用来进行,这些调用与特别的驱动是独立的; 设备驱动的角色就是将这些调用映射到作用于实际硬件的和设备相关的操作上.
驱动应当做到使硬件可用, 将所有关于如何使用硬件的事情留给应用程序. 一个驱动,如果它提供了对硬件能力的存取, 没有增加约束,就是灵活的.
内核的划分
尽管不同内核任务间的区别常常不是能清楚划分, 内核的角色可以划分成下列几个部分:
(1)进程管理: 内核负责创建和销毁进程, 并处理它们与外部世界的联系(输入和输出). 不同进程间通讯(通过信号, 管道, 或者进程间通讯原语)对整个系统功能来说是基本的, 也由内核处理. 另外, 调度器, 控制进程如何共享 CPU, 是进程管理的一部分. 更通常地, 内核的进程管理活动实现了多个进程在一个单个或者几个 CPU 之上的抽象.
(2)内存管理: 计算机的内存是主要的资源, 处理它所用的策略对系统性能是至关重要的. 内核为所有进程的每一个都在有限的可用资源上建立了一个虚拟地址空间. 内核的不同部分与内存管理子系统通过一套函数调用交互, 从简单的 malloc/free 对到更多更复杂的功能.
(3)文件系统: Unix 在很大程度上基于文件系统的概念; 几乎 Unix 中的任何东西都可看作一个文件. 内核在非结构化的硬件之上建立了一个结构化的文件系统, 结果是文件的抽象非常多地在整个系统中应用. 另外, Linux 支持多个文件系统类型, 就是说, 物理介质上不同的数据组织方式. 例如, 磁盘可被格式化成标准 Linux 的 ext3 文件系统, 普遍使用的 FAT 文件系统, 或者其他几个文件系统.
(4)设备控制: 几乎每个系统操作最终都映射到一个物理设备上. 除了处理器, 内存和非常少的别的实体之外, 全部中的任何设备控制操作都由特定于要寻址的设备相关的代码来进行. 这些代码称为设备驱动. 内核中必须嵌入系统中出现的每个外设的驱动, 从硬盘驱动到键盘和磁带驱动器. 内核功能的这个方面是本书中的我们主要感兴趣的地方.
(5)网络: 网络必须由操作系统来管理, 因为大部分网络操作不是特定于某一个进程: 进入系统的报文是异步事件. 报文在某一个进程接手之前必须被收集, 识别, 分发. 系统负责在程序和网络接口之间递送数据报文, 它必须根据程序的网络活动来控制程序的执行. 另外, 所有的路由和地址解析问题都在内核中实现.
Linux设备
以 Linux 的方式看待设备可区分为 3 种基本设备类型: 字符模块, 块模块,网络模块.
(1)字符设备: 一个字符(char)设备是一种可以当作一个字节流来存取的设备(如同一个文件); 一个字符驱动负责实现这种行为. 这样的驱动常常至少实现 open, close, read, 和 write 系统调用. 文本控制台(/dev/console)和串口(/dev/ttyS0及其它)是字符设备的例子, 因为它们很好地展现了流的抽象. 字符设备通过文件系统结点来存取, 例如 /dev/tty1和/dev/lp0. 在一个字符设备和一个普通文件之间唯一有关的不同就是, 你经常可以在普通文件中移来移去, 但是大部分字符设备仅仅是数据通道, 你只能顺序存取.
(2)块设备: 如同字符设备, 块设备通过位于 /dev 目录的文件系统结点来存取. 一个块设备(例如一个磁盘)应该是可以驻有一个文件系统的. 在大部分的 Unix 系统, 一个块设备只能处理这样的 I/O 操作, 传送一个或多个长度经常是 512 字节( 或一个更大的 2 的幂的数 )的整块. Linux, 相反, 允许应用程序读写一个块设备象一个字符设备一样 – 它允许一次传送任意数目的字节. 结果就是, 块和字符设备的区别仅仅在内核在内部管理数据的方式上, 并且因此在内核/驱动的软件接口上不同.如同一个字符设备, 每个块设备都通过一个文件系统结点被存取的, 它们之间的区别对用户是透明的. 块驱动和字符驱动相比, 与内核的接口完全不同.
(3)网络接口: 任何网络事务都通过一个接口来进行, 就是说, 一个能够与其他主机交换数据的设备. 通常, 一个接口是一个硬件设备, 但是它也可能是一个纯粹的软件设备, 比如环回接口. 一个网络接口负责发送和接收数据报文, 在内核网络子系统的驱动下,不必知道单个事务是如何映射到实际的被发送的报文上的. 很多网络连接(特别那些使用TCP的)是面向流的, 但是网络设备却常常设计成处理报文的发送和接收.一个网络驱动对单个连接一无所知; 它只处理报文.
内核模块和应用程序
(1)每个内核模块只注册自己以便来服务将来的请求, 并且它的初始化函数立刻终止. 换句话说, 模块初始化函数的任务是为以后调用模块的函数做准备; 好像是模块说, ” 我在这里, 这是我能做的.”模块的退出函数(例子里是 hello_exit)就在模块被卸载时调用. 它好像告诉内核, “我不再在那里了, 不要要求我做任何事了.” 每个内核模块都是这种类似于事件驱动的编程方法, 但不是所有的应用程序都是事件驱动的.
(2)事件驱动的应用程序和内核代码的退出函数不同: 一个终止的应用程序可以在释放资源方面”懒惰”, 或者完全不做清理工作, 但是模块的退出函数必须小心恢复每个由初始化函数建立的东西, 否则会保留一些东西直到系统重启.
insmod命令用于将给定的模块加载到内核中。Linux有许多功能是通过模块的方式,在需要时才载入kernel。如此可使kernel较为精简,进而提高效率,以及保有较大的弹性。这类可载入的模块,通常是设备驱动程序。例如:insmod xxx.ko
rmmod命令用于从当前运行的内核中移除指定的内核模块。执行rmmod指令,可删除不需要的模块。Linux操作系统的核心具有模块化的特性,应此在编译核心时,务须把全部的功能都放入核心。你可以将这些功能编译成一个个单独的模块,待有需要时再分别载入它们。例如:rmmod xxx.ko
(3) 一个模块在内核空间运行, 而应用程序在用户空间运行. 内核空间和用户空间特权级别不同,而且每个模式有它自己的内存映射–它自己的地址空间.
(4) 内核编程与传统应用程序编程方式很大不同的是并发问题. 大部分应用程序, 多线程的应用程序是一个明显的例外, 典型地是顺序运行的, 从头至尾, 不必要担心其他事情会发生而改变它们的环境. 内核代码没有运行在这样的简单世界中, 即便最简单的内核模块必须在这样的概念下编写, “很多事情可能马上发生”.
并发的理解如下:
内核编程中有几个并发的来源. 自然的, Linux 系统运行多个进程, 在同一时间, 不止一个进程能够试图使用你的驱动. 大部分设备能够中断处理器; 中断处理异步运行, 并且可能在你的驱动试图做其他事情的同一时间被调用. 几个软件抽象(例如内核定时器)也异步运行. 而且, 当然, Linux 可以在对称多处理器系统(SMP)上运行, 结果是你的驱动可能在多个 CPU 上并发执行. 最后, 在2.6, 内核代码已经是可抢占的了; 这个变化使得即便是单处理器会有许多与多处理器系统同样的并发问题.结果, Linux 内核代码, 包括驱动代码, 必须是可重入的–它必须能够同时在多个上下文中运行. 数据结构必须小心设计以保持多个执行线程分开, 并且代码必须小心存取共享数据, 避免数据的破坏. 编写处理并发和避免竞争情况(一个不幸的执行顺序导致不希望的行为的情形)的代码需要仔细考虑并可能是微妙的. 正确的并发管理在编写正确的内核代码时是必须的; 由于这个理由, 驱动都是考虑了并发下编写的.
(5)应用程序存在于虚拟内存中, 有一个非常大的堆栈区. 堆栈, 当然, 是用来保存函数调用历史以及所有的由当前活跃的函数创建的自动变量. 内核, 相反, 有一个非常小的堆栈;它可能小到一个, 4096 字节的页. 你的函数必须与这个内核空间调用链共享这个堆栈. 因此, 声明一个巨大的自动变量从来就不是一个好主意; 如果你需要大的结构, 你应当在调用时间内动态分配.
当前进程:
内核代码可以通过使用current指针指向当前在运行的进程. 实际上, current 不是一个全局变量. 支持SMP系统的需要强迫内核开发者去开发一种机制, 在相关的CPU上来找到当前进程. 这种机制也必须快速, 因为对current的引用非常频繁地发生. 结果就是一个依赖体系的机制, 常常, 隐藏了一个指task_struct 的指针在内核堆栈内. 实现的细节对别的内核子系统保持隐藏, 一个设备驱动可以只包含
insmod
modprobe
rmmod用户空间工具, 加载模块到运行中的内核以及去除它们.
#include <linux/init.h>
module_init(init_function);
module_exit(cleanup_function);指定模块的初始化和清理函数的宏定义.
__init
__initdata
__exit
__exitdata函数( __init 和 __exit )和数据 (__initdata 和 __exitdata)的标记, 只用在模块初始化或者清理时间. 为初始化所标识的项可能会在初始化完成后丢弃; 退出的项可能被丢弃如果内核没有配置模块卸载. 这些标记通过使相关的目标在可执行文件的特定的 ELF 节里被替换来工作.
#include
struct task_struct *current;当前进程.
current->pid
current->comm进程 ID 和 当前进程的命令名.
obj-m一个 makefile 符号, 内核建立系统用来决定当前目录下的哪个模块应当被建立.
/sys/module
/proc/modules/sys/module 是一个 sysfs 目录层次, 包含当前加载模块的信息. /proc/modules是旧式的, 那种信息的单个文件版本. 其中的条目包含了模块名, 每个模块占用的内存数量, 以及使用计数. 另外的字串追加到每行的末尾来指定标志, 对这个模块当前是活动的.
vermagic.o来自内核源码目录的目标文件, 描述一个模块为之建立的环境.
#include <linux/module.h>必需的头文件. 它必须在一个模块源码中包含.
#include <linux/version.h>头文件, 包含在建立的内核版本信息.
LINUX_VERSION_CODE整型宏定义, 对 #ifdef 版本依赖有用.
EXPORT_SYMBOL (symbol);
EXPORT_SYMBOL_GPL (symbol);宏定义, 用来输出一个符号给内核. 第 2 种形式输出没有版本信息, 第 3 种限制输出给 GPL 许可的模块.
MODULE_AUTHOR(author);
MODULE_DESCRIPTION(description);
MODULE_VERSION(version_string);
MODULE_DEVICE_TABLE(table_info);
MODULE_ALIAS(alternate_name);放置文档在目标文件的模块中.
module_init(init_function);
module_exit(exit_function);宏定义, 声明一个模块的初始化和清理函数.
#include <linux/moduleparam.h>
module_param(variable, type, perm);宏定义, 创建模块参数, 可以被用户在模块加载时调整( 或者在启动时间, 对于内嵌代码). 类型可以是 bool, charp, int, invbool, short, ushort, uint, ulong或者 intarray.
#include <linux/kernel.h>
int printk(const char * fmt, ...);内核代码的 printf 类似物.
字符设备之编号
编写驱动的第一步是定义驱动将要提供给用户程序的能力(机制).因为我们的”设备”是计算机内存的一部分, 我们可自由做我们想做的事情. 它可以是一个顺序的或者随机存取的设备, 一个或多个设备, 等等.
字符设备通过文件系统中的名子来存取. 那些名子称为文件系统的特殊文件, 或者设备文件, 或者文件系统的简单结点; 惯例上它们位于 /dev 目录. 块设备也出现在 /dev 中。如果你发出 ls -l 命令, 你会看到在设备文件项中有 2 个数(由一个逗号分隔)在最后修改日期前面, 这里通常是文件长度出现的地方. 这些数字是给特殊设备的主次设备编号.下面的列表显示了一个典型系统上出现的几个设备. 它们的主编号是 1, 4, 7, 和 10, 而次编号是 1, 3, 5, 64, 65, 和 129.
crw-rw-rw- 1 root root 1, 3 Apr 11 2002 null
crw------- 1 root root 10, 1 Apr 11 2002 psaux
crw------- 1 root root 4, 1 Oct 28 03:04 tty1
crw-rw-rw- 1 root tty 4, 64 Apr 11 2002 ttys0
crw-rw---- 1 root uucp 4, 65 Apr 11 2002 ttyS1
crw--w---- 1 vcsa tty 7, 1 Apr 11 2002 vcs1
crw--w---- 1 vcsa tty 7,129 Apr 11 2002 vcsa1
crw-rw-rw- 1 root root 1, 5 Apr 11 2002 zero传统上, 主编号标识设备相连的驱动. 例如, /dev/null 和 /dev/zero 都由驱动 1 来管理, 而虚拟控制台和串口终端都由驱动 4 管理; 同样, vcs1 和 vcsa1 设备都由驱动 7管理. 现代 Linux 内核允许多个驱动共享主编号, 但是你看到的大部分设备仍然按照一个主编号一个驱动的原则来组织.
次编号被内核用来决定引用哪个设备. 依据你的驱动是如何编写的(如同我们下面见到的),你可以从内核得到一个你的设备的直接指针, 或者可以自己使用次编号作为本地设备数组的索引. 不论哪个方法, 内核自己几乎不知道次编号的任何事情, 除了它们指向你的驱动实现的设备.
在建立一个字符驱动时你的驱动需要做的第一件事是获取一个或多个设备编号来使用. 为此目的的必要的函数是 register_chrdev_region, 在
int register_chrdev_region(dev_t first, unsigned int count, char *name);这里, first 是你要分配的起始设备编号. first 的次编号部分常常是 0, 但是没有要求是那个效果. count 是你请求的连续设备编号的总数. 注意, 如果 count 太大, 你要求的范围可能溢出到下一个次编号; 但是只要你要求的编号范围可用, 一切都仍然会正确工作.最后, name 是应当连接到这个编号范围的设备的名子; 它会出现在 /proc/devices和sysfs 中.
如同大部分内核函数, 如果分配成功进行, register_chrdev_region 的返回值是 0. 出错的情况下, 返回一个负的错误码, 你不能存取请求的区域.
如果你确实事先知道你需要哪个设备编号, register_chrdev_region 工作得好. 然而, 你常常不会知道你的设备使用哪个主编号; 在 Linux 内核开发社团中一直努力使用动态分配设备编号. 内核会乐于动态为你分配一个主编号, 但是你必须使用一个不同的函数来请求这个分配.
int alloc_chrdev_region(dev_t *dev, unsigned int firstminor, unsigned int count,char *name);使用这个函数, dev 是一个只输出的参数, 它在函数成功完成时持有你的分配范围的第一个数. fisetminor 应当是请求的第一个要用的次编号; 它常常是 0. count 和 name 参数如同给 request_chrdev_region 的一样.
不管你任何分配你的设备编号, 你应当在不再使用它们时释放它. 设备编号的释放使用:
void unregister_chrdev_region(dev_t first, unsigned int count);调用 unregister_chrdev_region 的地方常常是你的模块的 cleanup 函数.上面的函数分配设备编号给你的驱动使用, 但是它们不告诉内核你实际上会对这些编号做什么. 在用户空间程序能够存取这些设备号中一个之前, 你的驱动需要连接它们到它的实现设备操作的内部函数上. 我们将描述如何简短完成这个连接, 但首先顾及一些必要的枝节问题.
主编号的动态分配
一些主设备编号是静态分派给最普通的设备的. 一个这些设备的列表在内核源码树的Documentation/devices.txt 中. 分配给你的新驱动使用一个已经分配的静态编号的机会很小, 但是, 并且新编号没在分配. 因此, 作为一个驱动编写者, 你有一个选择: 你可以简单地捡一个看来没有用的编号, 或者你以动态方式分配主编号. 只要你是你的驱动的唯一用户就可以捡一个编号用; 一旦你的驱动更广泛的被使用了, 一个随机捡来的主编号将导致冲突和麻烦.
因此, 对于新驱动, 我们强烈建议你使用动态分配来获取你的主设备编号, 而不是随机选取一个当前空闲的编号. 换句话说, 你的驱动应当几乎肯定地使用 alloc_chrdev_region,不是 register_chrdev_region.
动态分配的缺点是你无法提前创建设备节点, 因为分配给你的模块的主编号会变化. 对于驱动的正常使用, 这不是问题, 因为一旦编号分配了, 你可从/proc/devices 中读取它.
字符型设备之一些重要数据结构
根据自己的理解画了一个结构图(如有错误,恳请指正!)
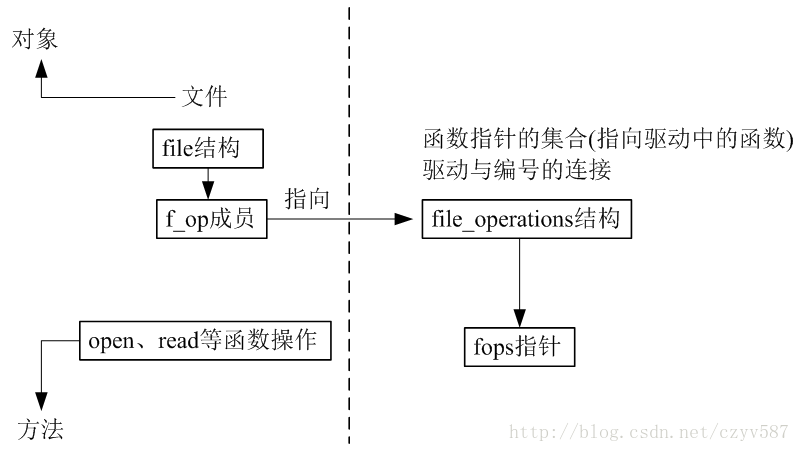
如同你想象的, 注册设备编号仅仅是驱动代码必须进行的诸多任务中的第一个.大部分的基础性的驱动操作包括3个重要的内核数据结构, 称为 file_operations, file, 和 inode. 需要对这些结构的基本了解才能够做大量感兴趣的事情。
到现在, 我们已经保留了一些设备编号给我们使用, 但是我们还没有连接任何我们设备操作到这些编号上. file_operation 结构将一个字符驱动与设备编号建立连接. 这个结构, 定义在
file_operations函数列表
struct module *owner
第一个 file_operations 成员根本不是一个操作; 它是一个指向拥有这个结构的模块的指针. 这个成员用来在它的操作还在被使用时阻止模块被卸载. 几乎所有时间中, 它被简单初始化为 THIS_MODULE, 一个在 <linux/module.h> 中定义的宏.
loff_t (*llseek) (struct file *, loff_t, int);llseek 方法用作改变文件中的当前读/写位置, 并且新位置作为(正的)返回值.
loff_t 参数是一个”long offset”, 并且就算在 32 位平台上也至少 64 位宽. 错误由一个负返回值指示. 如果这个函数指针是 NULL, seek 调用会以潜在地无法预知的方式修改 file 结构中的位置计数器( 在”file 结构” 一节中描述).
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);用来从设备中获取数据. 在这个位置的一个空指针导致 read 系统调用以 -EINVAL(“Invalid argument”) 失败. 一个非负返回值代表了成功读取的字节数( 返回值是一个 “signed size” 类型, 常常是目标平台本地的整数类型).
ssize_t (*aio_read)(struct kiocb *, char __user *, size_t, loff_t);初始化一个异步读 – 可能在函数返回前不结束的读操作. 如果这个方法是 NULL,所有的操作会由 read 代替进行(同步地).
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);发送数据给设备. 如果 NULL, -EINVAL 返回给调用 write 系统调用的程序. 如果非负, 返回值代表成功写的字节数.
ssize_t (*aio_write)(struct kiocb *, const char __user *, size_t, loff_t *);初始化设备上的一个异步写.
int (*readdir) (struct file *, void *, filldir_t);对于设备文件这个成员应当为 NULL; 它用来读取目录, 并且仅对文件系统有用.
unsigned int (*poll) (struct file *, struct poll_table_struct *);poll 方法是 3 个系统调用的后端: poll, epoll, 和 select, 都用作查询对一个或多个文件描述符的读或写是否会阻塞. poll 方法应当返回一个位掩码指示是否非阻塞的读或写是可能的, 并且, 可能地, 提供给内核信息用来使调用进程睡眠直到I/O 变为可能. 如果一个驱动的 poll 方法为 NULL, 设备假定为不阻塞地可读可写.
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);ioctl 系统调用提供了发出设备特定命令的方法(例如格式化软盘的一个磁道, 这不是读也不是写). 另外, 几个 ioctl 命令被内核识别而不必引用 fops 表. 如果设备不提供 ioctl 方法, 对于任何未事先定义的请求(-ENOTTY, “设备无这样的ioctl”), 系统调用返回一个错误.
int (*mmap) (struct file *, struct vm_area_struct *);mmap 用来请求将设备内存映射到进程的地址空间. 如果这个方法是 NULL, mmap 系统调用返回 -ENODEV.
int (*open) (struct inode *, struct file *);尽管这常常是对设备文件进行的第一个操作, 不要求驱动声明一个对应的方法. 如果这个项是 NULL, 设备打开一直成功, 但是你的驱动不会得到通知.
int (*flush) (struct file *);flush 操作在进程关闭它的设备文件描述符的拷贝时调用; 它应当执行(并且等待)设备的任何未完成的操作. 这个必须不要和用户查询请求的 fsync 操作混淆了. 当前, flush 在很少驱动中使用; SCSI 磁带驱动使用它, 例如, 为确保所有写的数据在设备关闭前写到磁带上. 如果 flush 为 NULL, 内核简单地忽略用户应用程序的请求.
int (*release) (struct inode *, struct file *);在文件结构被释放时引用这个操作. 如同 open, release 可以为 NULL.
int (*fsync) (struct file *, struct dentry *, int);这个方法是 fsync 系统调用的后端, 用户调用来刷新任何挂着的数据. 如果这个指针是 NULL, 系统调用返回 -EINVAL.
int (*aio_fsync)(struct kiocb *, int);这是 fsync 方法的异步版本.
int (*fasync) (int, struct file *, int);这个操作用来通知设备它的 FASYNC 标志的改变. 异步通知是一个高级的主题, 这个成员可以是NULL 如果驱动不支持异步通知.
int (*lock) (struct file *, int, struct file_lock *);lock 方法用来实现文件加锁; 加锁对常规文件是必不可少的特性, 但是设备驱动几乎从不实现它.
ssize_t (*readv) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t (*writev) (struct file *, const struct iovec *, unsigned long, loff_t *);这些方法实现发散/汇聚读和写操作. 应用程序偶尔需要做一个包含多个内存区的单个读或写操作; 这些系统调用允许它们这样做而不必对数据进行额外拷贝. 如果这些函数指针为 NULL, read 和 write 方法被调用( 可能多于一次 ).
ssize_t (*sendfile)(struct file *, loff_t *, size_t, read_actor_t, void *);这个方法实现 sendfile 系统调用的读, 使用最少的拷贝从一个文件描述符搬移数据到另一个. 例如, 它被一个需要发送文件内容到一个网络连接的 web 服务器使用.设备驱动常常使 sendfile 为 NULL.
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);sendpage 是 sendfile 的另一半; 它由内核调用来发送数据, 一次一页, 到对应的文件. 设备驱动实际上不实现 sendpage.
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);这个方法的目的是在进程的地址空间找一个合适的位置来映射在底层设备上的内存段中. 这个任务通常由内存管理代码进行; 这个方法存在为了使驱动能强制特殊设备可能有的任何的对齐请求. 大部分驱动可以置这个方法为 NULL.
int (*check_flags)(int)这个方法允许模块检查传递给 fnctl(F_SETFL…) 调用的标志.
int (*dir_notify)(struct file *, unsigned long);这个方法在应用程序使用 fcntl 来请求目录改变通知时调用. 只对文件系统有用;驱动不需要实现 dir_notify.
scull 设备驱动只实现最重要的设备方法. 它的 file_operations 结构是如下初始化的:
struct file_operations scull_fops = {
.owner = THIS_MODULE,
.llseek = scull_llseek,
.read = scull_read,
.write = scull_write,
.ioctl = scull_ioctl,
.open = scull_open,
.release = scull_release,
};这个声明使用标准的 C 标记式结构初始化语法. 这个语法是首选的, 因为它使驱动在结构定义的改变之间更加可移植, 并且, 有争议地, 使代码更加紧凑和可读. 标记式初始化允许结构成员重新排序; 在某种情况下, 真实的性能提高已经实现, 通过安放经常使用的成员的指针在相同硬件高速存储行中.
struct file
定义于
mode_t f_mode;文件模式确定文件是可读的或者是可写的(或者都是), 通过位 FMODE_READ 和FMODE_WRITE. 你可能想在你的 open 或者 ioctl 函数中检查这个成员的读写许可,但是你不需要检查读写许可, 因为内核在调用你的方法之前检查. 当文件还没有为那种存取而打开时读或写的企图被拒绝, 驱动甚至不知道这个情况.
loff_t f_pos;当前读写位置. loff_t 在所有平台都是 64 位( 在 gcc 术语里是 long long ).驱动可以读这个值, 如果它需要知道文件中的当前位置, 但是正常地不应该改变它;读和写应当使用它们作为最后参数而收到的指针来更新一个位置, 代替直接作用于filp->f_pos. 这个规则的一个例外是在 llseek 方法中, 它的目的就是改变文件位置.
unsigned int f_flags;这些是文件标志, 例如 O_RDONLY, O_NONBLOCK, 和 O_SYNC. 驱动应当检查O_NONBLOCK 标志来看是否是请求非阻塞操作( 我们在第一章的”阻塞和非阻塞操作”一节中讨论非阻塞 I/O ); 其他标志很少使用. 特别地, 应当检查读/写许可, 使用f_mode 而不是 f_flags. 所有的标志在头文件
struct file_operations *f_op;和文件关联的操作. 内核安排指针作为它的 open 实现的一部分, 接着读取它当它需要分派任何的操作时. filp->f_op 中的值从不由内核保存为后面的引用; 这意味着你可改变你的文件关联的文件操作, 在你返回调用者之后新方法会起作用. 例如,关联到主编号 1 (/dev/null, /dev/zero, 等等)的 open 代码根据打开的次编号来替代 filp->f_op 中的操作. 这个做法允许实现几种行为, 在同一个主编号下而不必在每个系统调用中引入开销. 替换文件操作的能力是面向对象编程的”方法重载”的内核对等体.
void *private_data;open 系统调用设置这个指针为 NULL, 在为驱动调用 open 方法之前. 你可自由使用这个成员或者忽略它; 你可以使用这个成员来指向分配的数据, 但是接着你必须记住在内核销毁文件结构之前, 在 release 方法中释放那个内存. private_data是一个有用的资源, 在系统调用间保留状态信息, 我们大部分例子模块都使用它.
struct dentry *f_dentry;关联到文件的目录入口(dentry)结构. 设备驱动编写者正常地不需要关心 dentry结构, 除了作为 filp->f_dentry->d_inode 存取 inode 结构. 真实结构有多几个成员, 但是它们对设备驱动没有用处. 我们可以安全地忽略这些成员,因为驱动从不创建文件结构; 它们真实存取别处创建的结构.
inode 结构
inode 结构由内核在内部用来表示文件. 因此, 它和代表打开文件描述符的文件结构是不同的. 可能有代表单个文件的多个打开描述符的许多文件结构, 但是它们都指向一个单个inode 结构.inode 结构包含大量关于文件的信息. 作为一个通用的规则, 这个结构只有 2 个成员对于编写驱动代码有用:
dev_t i_rdev;对于代表设备文件的节点, 这个成员包含实际的设备编号.
struct cdev *i_cdev;struct cdev 是内核的内部结构, 代表字符设备; 这个成员包含一个指针, 指向这个结构, 当节点指的是一个字符设备文件时.
内核在内部使用类型 struct cdev 的结构来代表字符设备. 在内核调用你的设备操作前, 你编写分配并注册一个或几个这些结构. 为此, 你的代码应当包含
struct cdev *my_cdev = cdev_alloc();
my_cdev->ops = &my_fops;但是, 偶尔你会想将 cdev 结构嵌入一个你自己的设备特定的结构; scull 这样做了. 在这种情况下, 你应当初始化你已经分配的结构, 使用:
void cdev_init(struct cdev *cdev, struct file_operations *fops);
任一方法, 有一个其他的 struct cdev 成员你需要初始化. 象 file_operations 结构,
struct cdev 有一个拥有者成员, 应当设置为 THIS_MODULE. 一旦 cdev 结构建立, 最后
的步骤是把它告诉内核, 调用:
int cdev_add(struct cdev *dev, dev_t num, unsigned int count);这里, dev 是 cdev 结构, num 是这个设备响应的第一个设备号, count 是应当关联到设备的设备号的数目. 常常 count 是 1, 但是有多个设备号对应于一个特定的设备的情形.例如, 设想 SCSI 磁带驱动, 它允许用户空间来选择操作模式(例如密度), 通过安排多个次编号给每一个物理设备.
在使用 cdev_add 是有几个重要事情要记住. 第一个是这个调用可能失败. 如果它返回一个负的错误码, 你的设备没有增加到系统中. 它几乎会一直成功, 但是, 并且带起了其他的影响: cdev_add 一返回, 你的设备就是”活的”并且内核可以调用它的操作. 除非你的驱动完全准备好处理设备上的操作, 你不应当调用 cdev_add.
为从系统去除一个字符设备, 调用:
void cdev_del(struct cdev *dev);在内部, scull 使用一个 struct scull_dev 类型的结构表示每个设备. 这个结构定义为:
struct scull_dev {
struct scull_qset *data; /* Pointer to first quantum set */
int quantum; /* the current quantum size */
int qset; /* the current array size */
unsigned long size; /* amount of data stored here */
unsigned int access_key; /* used by sculluid and scullpriv */
struct semaphore sem; /* mutual exclusion semaphore */
struct cdev cdev; /* Char device structure */
};我们在遇到它们时讨论结构中的各个成员, 但是现在, 我们关注于 cdev, 我们的设备与内核接口的 struct cdev. 这个结构必须初始化并且如上所述添加到系统中; 处理这个任务的 scull 代码是:
static void scull_setup_cdev(struct scull_dev *dev, int index)
{
int err, devno = MKDEV(scull_major, scull_minor + index);
cdev_init(&dev->cdev, &scull_fops);
dev->cdev.owner = THIS_MODULE;
dev->cdev.ops = &scull_fops;
err = cdev_add (&dev->cdev, devno, 1);
/* Fail gracefully if need be */
if (err)
printk(KERN_NOTICE "Error %d adding scull%d", err, index);
}因为 cdev 结构嵌在 struct scull_dev 里面, cdev_init 必须调用来进行那个结构的初始化.
open 方法
open 方法提供给驱动来做任何的初始化来准备后续的操作. 在大部分驱动中, open 应当进行下面的工作:
• 检查设备特定的错误(例如设备没准备好, 或者类似的硬件错误
• 如果它第一次打开, 初始化设备
• 如果需要, 更新 f_op 指针.
• 分配并填充要放进 filp->private_data 的任何数据结构
但是, 事情的第一步常常是确定打开哪个设备. 记住 open 方法的原型是:
int (*open)(struct inode *inode, struct file *filp);inode 参数有我们需要的信息,以它的 i_cdev 成员的形式, 里面包含我们之前建立的cdev 结构. 唯一的问题是通常我们不想要 cdev 结构本身, 我们需要的是包含 cdev 结构的 scull_dev 结构. C 语言使程序员玩弄各种技巧来做这种转换; 但是, 这种技巧编程是易出错的, 并且导致别人难于阅读和理解代码. 幸运的是, 在这种情况下, 内核 hacker已经为我们实现了这个技巧, 以 container_of 宏的形式, 在
container_of(pointer, container_type, container_field);这个宏使用一个指向 container_field 类型的成员的指针, 它在一个 container_type 类型的结构中, 并且返回一个指针指向包含结构. 在 scull_open, 这个宏用来找到适当的设备结构:
struct scull_dev *dev; /* device information */
dev = container_of(inode->i_cdev, struct scull_dev, cdev);
filp->private_data = dev; /* for other methods */scull_open 的代码(稍微简化过)是:
int scull_open(struct inode *inode, struct file *filp)
{
struct scull_dev *dev; /* device information */
dev = container_of(inode->i_cdev, struct scull_dev, cdev);
filp->private_data = dev; /* for other methods */
/* now trim to 0 the length of the device if open was write-only */
if ( (filp->f_flags & O_ACCMODE) == O_WRONLY)
{
scull_trim(dev); /* ignore errors */
}
return 0; /* success */
}代码看来相当稀疏, 因为在调用 open 时它没有做任何特别的设备处理. 它不需要, 因为scull 设备设计为全局的和永久的. 特别地, 没有如”在第一次打开时初始化设备”等动作,因为我们不为 scull 保持打开计数.
唯一在设备上的真实操作是当设备为写而打开时将它截取为长度为 0. 这样做是因为, 在设计上, 用一个短的文件覆盖一个 scull 设备导致一个短的设备数据区. 这类似于为写而打开一个常规文件, 将其截短为 0. 如果设备为读而打开, 这个操作什么都不做.
release 方法的角色是 open 的反面. 有时你会发现方法的实现称为 device_close, 而不是 device_release. 任一方式, 设备方法应当进行下面的任务:
• 释放 open 分配在 filp->private_data 中的任何东西
• 在最后的 close 关闭设备
scull 的基本形式没有硬件去关闭, 因此需要的代码是最少的:
int scull_release(struct inode *inode, struct file *filp)
{
return 0;
}你可能想知道当一个设备文件关闭次数超过它被打开的次数会发生什么. 毕竟, dup 和fork 系统调用不调用 open 来创建打开文件的拷贝; 每个拷贝接着在程序终止时被关闭.例如, 大部分程序不打开它们的 stdin 文件(或设备), 但是它们都以关闭它结束. 当一个打开的设备文件已经真正被关闭时驱动如何知道?
答案简单: 不是每个 close 系统调用引起调用 release 方法. 只有真正释放设备数据结构的调用会调用这个方法 – 因此得名. 内核维持一个文件结构被使用多少次的计数.fork 和 dup 都不创建新文件(只有 open 这样); 它们只递增正存在的结构中的计数.close 系统调用仅在文件结构计数掉到 0 时执行 release 方法, 这在结构被销毁时发生.release 方法和 close 系统调用之间的这种关系保证了你的驱动一次 open 只看到一次release.
读和写方法都进行类似的任务, 就是, 从和到应用程序代码拷贝数据. 因此, 它们的原型相当相似, 可以同时介绍它们:
ssize_t read(struct file *filp, char __user *buff, size_t count, loff_t *offp);
ssize_t write(struct file *filp, const char __user *buff, size_t count, loff_t *offp);对于 2 个方法, filp 是文件指针, count 是请求的传输数据大小. buff 参数指向持有被写入数据的缓存, 或者放入新数据的空缓存. 最后, offp 是一个指针指向一个”long offset type”对象, 它指出用户正在存取的文件位置. 返回值是一个”signed size type”.
让我们重复一下, read 和 write 方法的 buff 参数是用户空间指针. 因此, 它不能被内核代码直接解引用. 这个限制有几个理由:
(1) 依赖于你的驱动运行的体系, 以及内核被如何配置的, 用户空间指针当运行于内核模式可能根本是无效的. 可能没有那个地址的映射, 或者它可能指向一些其他的随机数据.
(2) 就算这个指针在内核空间是同样的东西, 用户空间内存是分页的, 在做系统调用时这个内存可能没有在 RAM 中. 试图直接引用用户空间内存可能产生一个页面错, 这是内核代码不允许做的事情. 结果可能是一个”oops”, 导致进行系统调用的进程死亡.
(3) 置疑中的指针由一个用户程序提供, 它可能是错误的或者恶意的. 如果你的驱动盲目地解引用一个用户提供的指针, 它提供了一个打开的门路使用户空间程序存取或覆盖系统任何地方的内存. 如果你不想负责你的用户的系统的安全危险, 你就不能直接解引用用户空间指针.
read 方法的任务是从设备拷贝数据到用户空间(使用copy_to_user), 而 write 方法必须从用户空间拷贝数据到设备(使用 copy_from_user).
unsigned long copy_to_user(void __user *to,const void *from,unsigned long count);
unsigned long copy_from_user(void *to,const void __user *from,unsigned long count);read 的参数表示了一个典型读实现是如何使用它的参数
read 和 write 方法都在发生错误时返回一个负值. 相反, 大于或等于 0 的返回值告知调用程序有多少字节已经成功传送. 如果一些数据成功传送接着发生错误, 返回值必须是成功传送的字节数, 错误不报告直到函数下一次调用. 实现这个传统, 当然, 要求你的驱动记住错误已经发生, 以便它们可以在以后返回错误状态.尽管内核函数返回一个负数指示一个错误, 这个数的值指出所发生的错误类型, 用户空间运行的程序常常看到 -1 作为错误返回值. 它们需要存取 errno 变量来找出发生了什么. 用户空间的行为由 POSIX 标准来规定, 但是这个标准没有规定内核内部如何操作.
read
read 的返回值由调用的应用程序解释:
(1) 如果这个值等于传递给 read 系统调用的 count 参数, 请求的字节数已经被传送.这是最好的情况.
(2) 如果是正数, 但是小于 count, 只有部分数据被传送. 这可能由于几个原因, 依赖于设备. 常常, 应用程序重新试着读取. 例如, 如果你使用 fread 函数来读取, 库函数重新发出系统调用直到请求的数据传送完成.
(3) 如果值为 0, 到达了文件末尾(没有读取数据).
(4) 一个负值表示有一个错误. 这个值指出了什么错误, 根据
ssize_t scull_read(struct file *filp, char __user *buf, size_t count, loff_t *f_pos)
{
struct scull_dev *dev = filp->private_data;
struct scull_qset *dptr; /* the first listitem */
int quantum = dev->quantum, qset = dev->qset;
int itemsize = quantum * qset; /* how many bytes in the listitem */
int item, s_pos, q_pos, rest;
ssize_t retval = 0;
if (down_interruptible(&dev->sem))
return -ERESTARTSYS;
if (*f_pos >= dev->size)
goto out;
if (*f_pos + count > dev->size)
count = dev->size - *f_pos;
/* find listitem, qset index, and offset in the quantum */
item = (long)*f_pos / itemsize;
rest = (long)*f_pos % itemsize;
s_pos = rest / quantum;
q_pos = rest % quantum;
/* follow the list up to the right position (defined elsewhere) */
dptr = scull_follow(dev, item);
if (dptr == NULL || !dptr->data || ! dptr->data[s_pos])
goto out; /* don't fill holes */
/* read only up to the end of this quantum */
if (count > quantum - q_pos)
count = quantum - q_pos;
if (copy_to_user(buf, dptr->data[s_pos] + q_pos, count))
{
retval = -EFAULT;
goto out;
}
*f_pos += count;
retval = count;
out:
up(&dev->sem);
return retval;
}write
write, 像 read, 可以传送少于要求的数据, 根据返回值的下列规则:
(1) 如果值等于 count, 要求的字节数已被传送.
(2) 如果正值, 但是小于 count, 只有部分数据被传送. 程序最可能重试写入剩下的数据.
(3) 如果值为 0, 什么没有写. 这个结果不是一个错误, 没有理由返回一个错误码. 再一次, 标准库重试写调用. 我们将在第 6 章查看这种情况的确切含义, 那里介绍了阻塞.
(4) 一个负值表示发生一个错误; 如同对于读, 有效的错误值是定义于
ssize_t scull_write(struct file *filp, const char __user *buf, size_t count, loff_t *f_pos)
{
struct scull_dev *dev = filp->private_data;
struct scull_qset *dptr;
int quantum = dev->quantum, qset = dev->qset;
int itemsize = quantum * qset;
int item, s_pos, q_pos, rest;
ssize_t retval = -ENOMEM; /* value used in "goto out" statements */
if (down_interruptible(&dev->sem))
return -ERESTARTSYS;
/* find listitem, qset index and offset in the quantum */
item = (long)*f_pos / itemsize;
rest = (long)*f_pos % itemsize;
s_pos = rest / quantum;
q_pos = rest % quantum;
/* follow the list up to the right position */
dptr = scull_follow(dev, item);
if (dptr == NULL)
goto out;
if (!dptr->data)
{
dptr->data = kmalloc(qset * sizeof(char *), GFP_KERNEL);
if (!dptr->data)
goto out;
memset(dptr->data, 0, qset * sizeof(char *));
}
if (!dptr->data[s_pos])
{
dptr->data[s_pos] = kmalloc(quantum, GFP_KERNEL);
if (!dptr->data[s_pos])
goto out;
}
/* write only up to the end of this quantum */
if (count > quantum - q_pos)
count = quantum - q_pos;
if (copy_from_user(dptr->data[s_pos]+q_pos, buf, count))
{
retval = -EFAULT;
goto out;
}
*f_pos += count;
retval = count;
/* update the size */
if (dev->size < *f_pos)
dev->size = *f_pos;
out:
up(&dev->sem);
return retval;
}介绍了下面符号和头文件. struct file_operations 和 struct file 中的成员的列表这里不重复了.
#include <linux/types.h>
dev_tdev_t 是用来在内核里代表设备号的类型.
int MAJOR(dev_t dev);
int MINOR(dev_t dev);从设备编号中抽取主次编号的宏.
dev_t MKDEV(unsigned int major, unsigned int minor);从主次编号来建立 dev_t 数据项的宏定义.
#include <linux/fs.h>“文件系统”头文件是编写设备驱动需要的头文件. 许多重要的函数和数据结构在此定义.
int register_chrdev_region(dev_t first, unsigned int count, char *name)
int alloc_chrdev_region(dev_t *dev, unsigned int firstminor, unsigned int count, char *name)
void unregister_chrdev_region(dev_t first, unsigned int count);允许驱动分配和释放设备编号的范围的函数. register_chrdev_region 应当用在事先知道需要的主编号时; 对于动态分配, 使用 alloc_chrdev_region 代替.
int register_chrdev(unsigned int major, const char *name, struct
file_operations *fops);老的(2.6之前) 字符设备注册函数. 它在 2.6 内核中被模拟, 但是不应当给新代码使用. 如果主编号不是 0, 可以不变地用它; 否则一个动态编号被分配给这个设备.
int unregister_chrdev(unsigned int major, const char *name);
恢复一个由 register_chrdev 所作的注册的函数. major 和 name 字符串必须包含之前用来注册设备时同样的值.
struct file_operations;
struct file;
struct inode;大部分设备驱动使用的 3 个重要数据结构. file_operations 结构持有一个字符驱动的方法; struct file 代表一个打开的文件, struct inode 代表磁盘上的一个文件.
#include <linux/cdev.h>
struct cdev *cdev_alloc(void);
void cdev_init(struct cdev *dev, struct file_operations *fops);
int cdev_add(struct cdev *dev, dev_t num, unsigned int count);
void cdev_del(struct cdev *dev);cdev 结构管理的函数, 它代表内核中的字符设备.
#include <linux/kernel.h>
container_of(pointer, type, field);一个传统宏定义, 可用来获取一个结构指针, 从它里面包含的某个其他结构的指针.
#include <asm/uaccess.h>这个包含文件声明内核代码使用的函数来移动数据到和从用户空间.
unsigned long copy_from_user (void *to, const void *from, unsigned long count);
unsigned long copy_to_user (void *to, const void *from, unsigned long count);在用户空间和内核空间拷贝数据.
ioctl 方法
大部分驱动需要 – 除了读写设备的能力 – 通过设备驱动进行各种硬件控制的能力. 大部分设备可进行超出简单的数据传输之外的操作; 用户空间必须常常能够请求, 例如, 设备锁上它的门, 弹出它的介质, 报告错误信息, 改变波特率, 或者自我销毁. 这些操作常常通过 ioctl 方法来支持, 它通过相同名子的系统调用来实现.
ioctl是设备驱动程序中对设备的I/O通道进行管理的函数。所谓对I/O通道进行管理,就是对设备的一些特性进行控制,例如串口的传输波特率、马达的转速等等。它的参数个数如下:int ioctl(int fd, int cmd, …);其中fd就是用户程序打开设备时使用open函数返回的文件标示符,cmd就是用户程序对设备的控制命令,至于后面的省略号,那是一些补充参数,一般最多一个,有或没有是和cmd的意义相关的。ioctl函数是文件结构中的一个属性分量,就是说如果你的驱动程序提供了对ioctl的支持,用户就能在用户程序中使用ioctl函数控制设备的I/O通道。
控制I/O设备 ,提供了一种获得设备信息和向设备发送控制参数的手段。用于向设备发控制和配置命令 ,有些命令需要控制参数,这些数据是不能用read / write 读写的,称为Out-of-band数据。也就是说,read / write 读写的数据是in-band数据,是I/O操作的主体,而ioctl 命令传送的是控制信息,其中的数据是辅助的数据。
必要性:如果不用IOCTL的话,也能实现对设备I/O通道的控制,但那就是蛮拧了。例如,我们可以在驱动程式中实现WRITE的时候检查一下是否有特别约定的数据流通过,如果有的话,那么后面就跟着控制命令(一般在SOCKET编程中常常这样做)。不过如果这样做的话,会导致代码分工不明,程式结构混乱,程式员自己也会头昏眼花的。所以,我们就使用IOCTL来实现控制的功能。要记住,用户程式所作的只是通过命令码告诉驱动程式他想做什么,至于怎么解释这些命令和怎么实现这些命令,这都是驱动程式要做的事情。
读者只要把write换成ioctl,就知道用户程式的ioctl是怎么和驱动程式中的ioctl实现联系在一起的了。我这里说一个大概思路,因为我觉得《Linux设备驱动程序》这本书已说的非常清晰了,不过得花一些时间来看。在驱动程式中实现的ioctl函数体内,实际上是有一个switch{case}结构,每一个case对应一个命令码,做出一些相应的操作。怎么实现这些操作,这是每一个程式员自己的事情,因为设备都是特定的,这里也没法说。关键在于怎么样组织命令码,因为在ioctl中命令码是唯一联系用户程式命令和驱动程式支持的途径。命令码的组织是有一些讲究的,因为我们一定要做到命令和设备是一一对应的,这样才不会将正确的命令发给错误的设备,或是把错误的命令发给正确的设备,或是把错误的命令发给错误的设备。这些错误都会导致不可预料的事情发生,而当程式员发现了这些奇怪的事情的时候,再来调试程式查找错误,那将是非常困难的事情。所以在Linux核心中是这样定义一个命令码的:
| 设备类型 | 序列号 | 方向 | 数据尺寸 |
|---|---|---|---|
| 8 bit | 8 bit | 2 bit | 8~14 bit |
这样一来,一个命令就变成了一个整数形式的命令码。不过命令码非常的不直观,所以Linux Kernel中提供了一些宏,这些宏可根据便于理解的字符串生成命令码,或是从命令码得到一些用户能理解的字符串以标明这个命令对应的设备类型、设备序列号、数据传送方向和数据传输尺寸。这些宏我就不在这里解释了,具体的形式请读者察看Linux核心原始码中的和,文件里给除了这些宏完整的定义。这里我只多说一个地方,那就是”幻数”。幻数是个字母,数据长度也是8,所以就用一个特定的字母来标明设备类型,这和用一个数字是相同的,只是更加利于记忆和理解。就是这样,再没有更复杂的了。更多的说了也没有,读者还是看一看原始码吧,推荐各位阅读《Linux 设备驱动程序》所带原始码中的short一例,因为他比较短小,功能比较简单,能看明白ioctl的功能和细节。
ioctl其实没有什么非常难的东西需要理解,关键是理解cmd命令码是怎么在用户程序里生成并在驱动程序里解析的,程序员最主要的工作量在switch{case}结构中,因为对设备的I/O控制都是通过这一部分的代码实现的。
ioctl 的 scull 实现只传递设备的配置参数, 并且象下面这样容易:
switch(cmd)
{
case SCULL_IOCRESET:
scull_quantum = SCULL_QUANTUM;
scull_qset = SCULL_QSET;
break;
case SCULL_IOCSQUANTUM: /* Set: arg points to the value */
if (! capable (CAP_SYS_ADMIN))
return -EPERM;
retval = __get_user(scull_quantum, (int __user *)arg);
break;
case SCULL_IOCTQUANTUM: /* Tell: arg is the value */
if (! capable (CAP_SYS_ADMIN))
return -EPERM;
scull_quantum = arg;
break;
case SCULL_IOCGQUANTUM: /* Get: arg is pointer to result */
retval = __put_user(scull_quantum, (int __user *)arg);
break;
case SCULL_IOCQQUANTUM: /* Query: return it (it's positive) */
return scull_quantum;
case SCULL_IOCXQUANTUM: /* eXchange: use arg as pointer */
if (! capable (CAP_SYS_ADMIN))
return -EPERM;
tmp = scull_quantum;
retval = __get_user(scull_quantum, (int __user *)arg);
if (retval == 0)
retval = __put_user(tmp, (int __user *)arg);
break;
case SCULL_IOCHQUANTUM: /* sHift: like Tell + Query */
if (! capable (CAP_SYS_ADMIN))
return -EPERM;
tmp = scull_quantum;
scull_quantum = arg;
return tmp;
default: /* redundant, as cmd was checked against MAXNR */
return -ENOTTY;
}
return retval;从调用者的观点看(即从用户空间), 这 6 种传递和接收参数的方法看来如下:
int quantum;
ioctl(fd,SCULL_IOCSQUANTUM, &quantum); /* Set by pointer */
ioctl(fd,SCULL_IOCTQUANTUM, quantum); /* Set by value */
ioctl(fd,SCULL_IOCGQUANTUM, &quantum); /* Get by pointer */
quantum = ioctl(fd,SCULL_IOCQQUANTUM); /* Get by return value */
ioctl(fd,SCULL_IOCXQUANTUM, &quantum); /* Exchange by pointer */
quantum = ioctl(fd,SCULL_IOCHQUANTUM, quantum); /* Exchange by value */在用户空间, ioctl 系统调用有下面的原型:
int ioctl(int fd, unsigned long cmd, ...);这个原型由于这些点而凸现于 Unix 系统调用列表, 这些点常常表示函数有数目不定的参数. 在实际系统中, 但是, 一个系统调用不能真正有变数目的参数. 系统调用必须有一个很好定义的原型, 因为用户程序可存取它们只能通过硬件的”门”. 因此, 原型中的点不表示一个变数目的参数, 而是一个单个可选的参数, 传统上标识为 char *argp. 这些点在那里只是为了阻止在编译时的类型检查. 第 3 个参数的实际特点依赖所发出的特定的控制命令(第2个参数). 一些命令不用参数, 一些用一个整数值, 以及一些使用指向其他数据的指针. 使用一个指针是传递任意数据到 ioctl 调用的方法; 设备接着可与用户空间交换任何数量的数据.
ioctl 驱动方法有和用户空间版本不同的原型:
int (*ioctl) (struct inode *inode, struct file *filp, unsigned int cmd,
unsigned long arg);inode 和 filp 指针是对应应用程序传递的文件描述符 fd 的值, 和传递给 open 方法的相同参数. cmd 参数从用户那里不改变地传下来, 并且可选的参数 arg 参数以一个unsigned long 的形式传递, 不管它是否由用户给定为一个整数或一个指针. 如果调用程序不传递第 3 个参数, 被驱动操作收到的 arg 值是无定义的. 因为类型检查在这个额外参数上被关闭, 编译器不能警告你如果一个无效的参数被传递给 ioctl, 并且任何关联的错误将难以查找.如果你可能想到的, 大部分 ioctl 实现包括一个大的 switch 语句来根据 cmd 参数, 选择正确的做法. 不同的命令有不同的数值, 它们常常被给予符号名来简化编码. 符号名通过一个预处理定义来安排.
在为 ioctl 编写代码之前, 你需要选择对应命令的数字. 许多程序员的第一个本能的反应是选择一组小数从0 或1 开始, 并且从此开始向上. 但是, 有充分的理由不这样做.ioctl 命令数字应当在这个系统是唯一的, 为了阻止向错误的设备发出正确的命令而引起的错误. 这样的不匹配不会不可能发生, 并且一个程序可能发现它自己试图改变一个非串口输入系统的波特率, 例如一个 FIFO 或者一个音频设备. 如果这样的 ioctl 号是唯一的, 这个应用程序得到一个 EINVAL 错误而不是继续做不应当做的事情.
定义 ioctl 命令号的正确方法使用 4 个位段, 它们有下列的含义. 这个列表中介绍的新符号定义在
unsigned int (*poll) (struct file *filp, poll_table *wait);这个驱动方法被调用, 无论何时用户空间程序进行一个 poll, select, 或者 epoll 系统调用, 涉及一个和驱动相关的文件描述符. 这个设备方法负责这 2 步:
• 1. 在一个或多个可指示查询状态变化的等待队列上调用 poll_wait. 如果没有文件描述符可用作 I/O, 内核使这个进程在等待队列上等待所有的传递给系统调用的文件描述符.
• 2. 返回一个位掩码, 描述可能不必阻塞就立刻进行的操作.
这2个操作常常是直接的, 并且趋向与各个驱动看起来类似. 但是, 它们依赖只能由驱动提供的信息, 因此, 必须由每个驱动单独实现.
poll_table 结构, 给 poll 方法的第 2 个参数, 在内核中用来实现 poll, select, 和epoll 调用; 它在
void poll_wait (struct file *, wait_queue_head_t *, poll_table *);poll 方法的第 2 个任务是返回位掩码, 它描述哪个操作可马上被实现; 这也是直接的.例如, 如果设备有数据可用, 一个读可能不必睡眠而完成; poll 方法应当指示这个时间状态. 几个标志(通过
POLLIN如果设备可被不阻塞地读, 这个位必须设置.
POLLRDNORM这个位必须设置, 如果”正常”数据可用来读. 一个可读的设备返回( POLLIN|POLLRDNORM ).
POLLRDBAND这个位指示带外数据可用来从设备中读取. 当前只用在 Linux 内核的一个地方( DECnet 代码 )并且通常对设备驱动不可用.
POLLPRI高优先级数据(带外)可不阻塞地读取. 这个位使 select 报告在文件上遇到一个异常情况, 因为 selct 报告带外数据作为一个异常情况.
POLLHUP当读这个设备的进程见到文件尾, 驱动必须设置 POLLUP(hang-up). 一个调用select 的进程被告知设备是可读的, 如同 selcet 功能所规定的.
POLLERR一个错误情况已在设备上发生. 当调用 poll, 设备被报告位可读可写, 因为读写都返回一个错误码而不阻塞.
POLLOUT这个位在返回值中设置, 如果设备可被写入而不阻塞.
POLLWRNORM这个位和 POLLOUT 有相同的含义, 并且有时它确实是相同的数. 一个可写的设备返回( POLLOUT|POLLWRNORM).
POLLWRBAND如同 POLLRDBAND , 这个位意思是带有零优先级的数据可写入设备. 只有 poll 的数据报实现使用这个位, 因为一个数据报看传送带外数据.
static unsigned int scull_p_poll(struct file *filp, poll_table *wait)
{
struct scull_pipe *dev = filp->private_data;
unsigned int mask = 0;
/*
* The buffer is circular; it is considered full
* if "wp" is right behind "rp" and empty if the
* two are equal.
*/
down(&dev->sem);
poll_wait(filp, &dev->inq, wait);
poll_wait(filp, &dev->outq, wait);
if (dev->rp != dev->wp)
mask |= POLLIN | POLLRDNORM; /* readable */
if (spacefree(dev))
mask |= POLLOUT | POLLWRNORM; /* writable */
up(&dev->sem);
return mask;
}这个代码简单地增加了 2 个 scullpipe 等待队列到 poll_table, 接着设置正确的掩码位, 根据数据是否可以读或写.














 1373
1373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









