









记者 | 白羽
几乎每周,人工智能深度学习,总会在某个领域有新的技术突破,新的亮眼成果出来。
不过,这些最新的突破和成果,更多还是在深度学习的各大社区流动,更多是被顶尖教授、学者所掌握和应用,对于普通的程序员来说,有点太高冷了。
尤其是对于大数据工程师、分析师、数据科学家这类人,他们虽并太懂深度学习,而是大量使用Hadoop、Spark平台来管理数据,对数据进行SQL处理、流分析,但工作中却也需要搞搞数据挖掘,机器学习、深度学习、做做图片分析等。
问题来了。面对最新的深度学习技术,他们到底得怎么应对呢?
要知道,他们目前所使用的一整套工具和架构,和深度学习社区里面所给出的这些架构,中间是有断层的。
为了解决这个问题,降低这些人群使用深度学习的门槛,使他们能在现有的Hadoop、Spark平台就能将深度学习的技术直接运用起来,英特尔最近低调透露了其专门为这类人群构建的BigDL。
其实,早在2016年12月,这个项目就已开源,并在GitHub上发布了第一个版本。
截止目前,BigDL已发布4个版本,支持Spark1.5到2.2。
不过,关于这个项目本身,英特尔官方极少披露更多信息。
比如:BigDL为什么架构在Spark上,而不直接架构在Hadoop上呢?未来主要的演进方向是什么?BigDL对使用者有什么要求?在具体的企业应用中,到底有哪些是真正落地的?
就此,AI科技大本营专门采访了英特尔高级首席工程师、大数据技术全球CTO戴金权,看看这个工具,到底能给普通数据分析师带来多大程度的利好,对企业到底能产生怎样的价值。
为方便读者阅读,也为了保持戴金权的原话,我们将以小标题的形式,对比较核心的问题,逐一展开问答。
AI科技大本营:对于普通数据工程师以及数据科学的社区来说,BigDL到底能带来哪些方便之处?
戴金权:大致来说,有这么几个好处吧。
第一、它可以让用户直接在现有的大数据集群,比如说Hadoop集群、Spark集群上直接运行新的深度学习的应用。这样就提高整个集群或者硬件资源的利用率,从而能够降低成本。
第二、可以在存储数据同一个集群上使用深度学习的技术来分析大数据。在真正的现实生产环境当中,数据其实非常庞大,要做非常多的数据清洗、数据处理。而这些生产数据通常存储在大数据集群里,比如Hadoop集群、Spark集群上,如何直接在这些数据存储的地方进行分析,在现实生产环境当中是非常重要的考量。如果用户有一个专门设立单独的集群,这个集群专门做深度学习,用户需要将深度学习应用部署到相应的产生环境中,这就需要把数据从几千台、几万台大数据集群上拷贝到新的集群上去,再进行分析。而且这还不是一次性的过程,因为数据在不停的变化中,需要对数据进行不同的处理和分析。这是数据拷贝的过程非常大的瓶颈。
我们所做的,就是让用户直接在现有的大数据集群上,不需要对数据进行任何拷贝,就可以用深度学习来分析大数据。
第三、这些数据工程师可以重用现有的大数据的工具,比如说工作流的管理,资源管理,来对集群进行资源管理等等。这样就大大提高用户对深度学习的开发效率、应用部署的效率。
AI科技大本营:具体来说,BigDL有哪几项比较实在的功能?
戴金权: 第一,BigDL可以说是目前唯一一个针对大数据平台,对广泛部署的大数据平台专门进行性能,包括扩展性进行优化的一个深度学习的框架。
大家知道,大数据平台基本上是基于Hadoop、Spark为标准的大规模分布式,从某种意义上基于英特尔至强处理器的一个大规模的集群。BigDL在上面做了大量的优化工作,比如说使用我们的硬件指令,使用我们的MKL的数学库,使用多线程编程等等,在英特尔至强服务器上得到了非常好的性能。
我们又利用Apache Spark这样一个非常高效的低延迟,基于内存的这样一个分布式数据的处理引擎来支持高效的所谓横向扩展scale-out,从某种意义上是目前最方便的进行大规模分布式的训练和推理的框架,对用户来说其实不需要做任何事情,所有的分布式工作对用户都是透明的,这个框架可以无缝地支持进来。
第二、提供了对现有的深度学习的生态系统的深度支持。
BigDL可以直接支持现有的Tensor Flow、Keras、Caffe、Torch的模型,因此,第三方的框架里所训练的模型和所构建的模型可以直接在BigDL的框架里所使用,这其实对于很多用户来说,是非常重要的使用场景。
第三、对现有的大数据生态系统的无缝集成。
从某种程度上BigDL就是标准的Spark上面的一个组件,跟Spark上其他的组件,比如说Spark SQL也好,Spark Streaming也好,ML pipeline也好,其实从技术上来说没有任何区别,对现有大数据生态系统,应该说它就是大数据生态系统的一个组成部分。
所以不管是对Spark SQL、Data Frame、ML Pipeline等等,包括最新的Spark on Kubernetes这样一些新功能都可以直接无缝地或者原生地支持起来。
同时BigDL还提供了深度学习的模型,用户可以直接在一个GBM里面,一个本地的JAVA程序里面运行起来。
这个好处是什么?
现有的大数据生态系统Hadoop也好、Hbase也好、Kafka也好、Storm也好等等,基本上是基于GBM的框架。相当于用户可以直接在这些框架里面也可以将BigDL的模型,深度学习的模型使用起来。
第四、大量的高级算法和模型已被整合到BigDL以及BigDL相关的项目中,这样用户可以直接在Spark应用程序里使用这些高级的算法、高级的模型,而不需要做额外的开发工作。
比如说在深度学习里面,大部分的应用是进行计算机是视觉的处理,怎么样对图像进行很好的处理,确实是非常重要的一个方面。
在业界其实对图像进行处理很重要的一个Library就是OpenCV,BigDL也直接提供对OpenCV在Spark上直接进行分布式的图像处理这样的工作,这样用户很容易对图像进行处理和增强等等,而且可以跟Spark RDD相结合,进行大规模分布式的处理,这其实我们在后面也会看到我们的用户也使用这样的一个技术来对它的应用程序进行非常高效的处理。
AI科技大本营:可否详细谈谈对现在学习框架的支持,以及带来的好处?
戴金权:刚才我提到,可以支持现有的深度学习框架包括:Tensor Flow模型,Keras模型、Caffe模型、Torch模型等等,有这么几个好处:
第一、新的深度学习研究成果发布出来后,可以直接将这些成果和现有模型在大数据平台上进行推理,微调等。
第二、方便用户进行大规模分布式处理。原来一些单机训练出来的模型可以直接无缝透明地跑在大规模分布式的环境里,不管推理也好,进一步训练也好。
第三、对于社区是极大利好。很多时候,当我们真正将一个应用产品化时,需要生产环境,而生产环境的工程师可能会使用大数据平台来对研究成果进行生产化部署。这样,不管是原来的研究人员,还是内部的研究人员,还是外部的人员,不管使用什么框架,都可以直接将这个模型共享给生产环境当中的工程师来进行处理。
四、我们也会支持跟TensorFlow集成。TensorFlow是谷歌这边发布的深度学习应用可视化的工具。因为深度学习从本质上是很复杂,需要非常多人工参与的过程。我们跟TensorFlow集成,能够将BigDL的应用通过TensorFlow来提供可视化的支持。
举个例子,假定数据库里存放许多图片,一位数据分析师想搜索这些图片,原来可能只能通过图片描述和标题来进行搜索,而现在使用BigDL之后,就可以很方便地将深度学习的模型,比如说一个图片识别的模型变成嵌入成BigDL的模型,直接把它变成基于SQL处理的UDF用户定义的函数。比如,所有狗的图片,就直接可以把狗的图片找出来,它不是通过图片的描述来找,而是直接通过图片的象素来找。
这样,就大大降低了使用深度学习的门槛,哪怕这位分析师不会写任何代码,只会写SQL,但仍然能将人工智能用起来。
AI科技大本营:就图片处理这个具体的应用场景,可否举例说明一下,到底如何帮助企业解决相关的痛点问题?
戴金权:比如,京东有非常多的图片,它要找到图片当中相关物品,这里做的事情是特征提取,这就需要首先检测到这个物品,再做特征提取。
特征提取的应用场景有哪些呢?比如拍照购买,拍一张图片,找到跟图片相类似的产品。还有对图片去重等等。
原来是基于GPU做模型,有了模型之后,下一个问题是怎么样将这个模型扩展到几亿张图片上去,进行大规模的分布式处理。
这时候GPU的解决方案就会遇到很多的问题,包括在分布式的GPU集群上怎么进行资源的管理调度,怎么样处理各种各样的错误行为,怎么样部署等,因为分布式环境非常容易出现异常情况。
京东现在是用BigDL直接在现有的Hadoop、Spark集群上运行深度学习的应用,这就可以将其他框架的模型,比如训练好的模型直接Load进BigDL,在BigDL使用OpenCV技术在Spark集群上进行并行处理。

这样的好处就是,第一可以有更高的资源利用率,可以重用现有的Hadoop、Spark集群,而且并不是独栈式的使用。
大数据集群之间本身是作为一个服务提供给所有的用户,所有的数据都在这个集群上,所有用户可以共享这个集群,任务的调度分配是动态的过程。
其实不光是运行深度学习,比如说有人跑SQL,有人跑ETL,在上面运行BigDL的深度学习的应用,就得到一个动态的共享,其大大提高了资源利用率,降低了成本。
第二,从开发、从大规模分布式部署的角度来说,大数据的集群可以帮助自动化,大大提高开发部署的效率。
第三,从性能上来说,相比GPU,用BigDL在Spark上进行高效的分布式的处理,在这个集群上可以取得3.8倍的性能提升。
AI科技大本营:除了图片外,语音方面是否有可以分享的案例呢?
戴金权: 语音方面,我分享一个关于GigaSpaces的例子。
GigaSpaces是美国的一个服务商,它做的事情是基于自然语言处理来对呼叫中心进行管理、组织。
他们的流程是这样的。
首先你打电话进来,它有一个Voice Recognition(语音识别)的系统,把你的Speech(语音)转成文字,然后它直接扔到Kafka。这个有一定实时性的要求。
然后通过Spark streaming把它从Kafka读进来。
读进来之后,基于BigDL,我们做了一个基于文本的自然语言处理的文本分类算法。也就是说,你打电话进来,它就知道你说的是Windows系统有问题,还是Mac系统有问题,是什么系统有问题。
根据自然语言做文本分类,然后就可以直接将呼叫中心的电话自动转给不同的专家。
如果是Mac的问题,就自动转给Mac系统专家。
这就是它整个的流程,从前端的Web应用,到Kafka,然后经过Spark streaming进行流式处理,再使用BigDL的分类模型,最后自动进行转接。
这个应用使用了BigDL提供的一个基于自然语言分析的现有模型,直接把它嵌入到整个streaming的应用当中,可以非常方便的做到基于自然语言处理智能呼叫中心的一个路由。
AI科技大本营:BigDL到底能带来多大的性能提升呢?有没有具体的数据?
戴金权:我举个跟AWS合作的例子,从中可以看出使用BigDL低精度和量化机制运行于AWS C5时,模型大小和推理速度这两个方面的表现。
AWS在去年发布了最新的AWS EC2 C5 instance,这是基于英特尔的至强可扩展平台构建一个最新的高性能基础平台。在这个平台上,我们对BigDL进行了大量的优化。
当前,深度学习其实是基于神经网络,主要是基于大量的浮点运算,但事实上深度学习的模型可以拥有一定的随机性,从某种意义上,可以采用更低的精度。
所以,我们使用了8位整数,而不是浮点计算来进行深度学习模型的推理。8位整数就是低精度或者量化的机制。
同时在硬件上我们直接使用了最新的至强可扩展处理器(AVX-512指令)。
这样相结合,可以看到模型大小有接近四倍的压缩比,同时接近两倍的推理速度的提高。
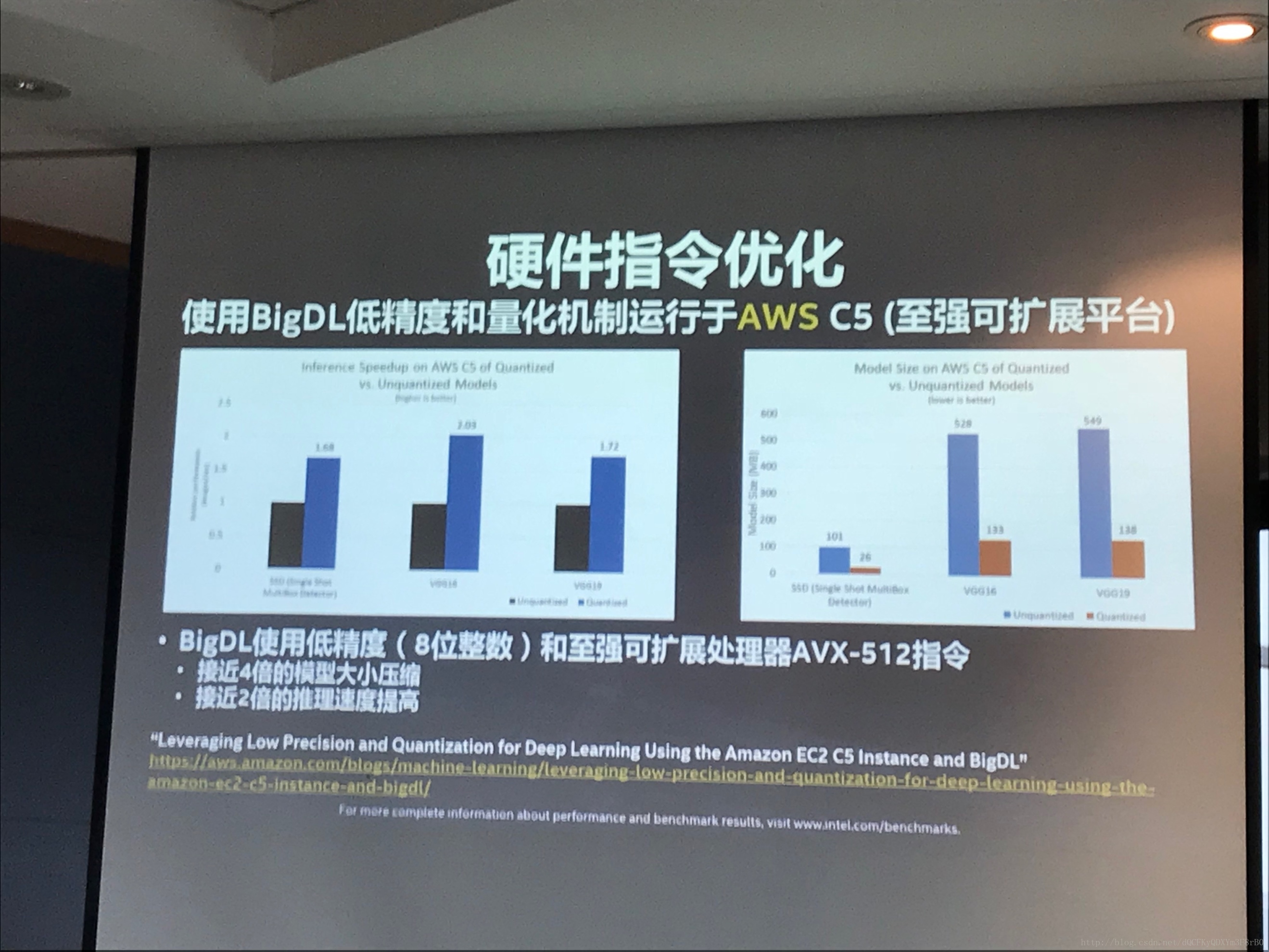
这个优化对所有最新的至强可扩展平台来讲,都可以达到这样效果。
AI科技大本营:BigDL最近为用户带来了哪些新的功能呢?
戴金权:BigDL最近做了一件事情——提供“Model Zoo”,它能提供更丰富的深度学习的预训练出来的模型,以及应用的参考实现,包括图像分类、物品检测、情感分析、欺诈检测、推荐以及强化学习等等。
这些模型,大多都已预训练好,可以直接load到大数据的开发和应用当中。
还有一些构建了端到端的参考实现,比如说要做推荐模型,不同人有不同的数据,这可能需要自己去构建整个Pipeline做训练和最后的推荐,不过它可以帮你把端到端的流程,应用参考实现给实现起来。
这是很多用户的需求,可以大大提高他们对深度学习应用开发的效率。
我稍微举例详细展开一下。
比如物品检测。
关于物品检测,这里提供了非常多的预训练模型,使用BigDL的Object Detection API就非常方便。
首先把模型Load进来,Load进来之后构建一个Predictor预测器,然后对图片进行预测。
你可以检测视频,视频无非就是一帧一帧的图片。我可以直接下载一个视频,然后对视频进行处理,变成一帧一帧图片,对每一帧图片进行检测。
比如,在视频中跟踪足球明星梅西。
当然,首先要对视频里面的图片做一些简单的标签,然后预训练一个模型。预训练出模型之后,就可以在视频里跟踪到梅西在哪里了。














 4078
4078











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









