






c++为了兼容c保留了struct类型,但是c++中的struct和c有明显的区别,c++中的struct可以继承,可以有成员函数,但是在c中却不行,在c++中struc和class更相似(还是有一些区别的,这里不再叙述),c中struct的内存分布很简单,那么c++中的class(struct)是怎么样的呢?
首先没有虚函数的类其内存布局和c的struct没有什么根本的区别,其实例效率和c是一样的。当有虚函数时对象会有一个特殊的指针指向虚函数表(vpt),在最初的cfront(c++的第一个编译器)实现中,虚函数表指针(vpt)储存在对象的底部。这保持了与C结构布局的兼容性。但是,在C++中加入了多重继承和虚基类后,许多实现开始将vptr置于对象的顶部。在多重继承环境中,如果可以通过指向成员的指针调用虚函数,使用这个方案更加效率。但是,它破坏了C++对象与c结构的互操作性。目前,许多实现都将vptr置于对象的顶部。
class B{ class D1: public B{
public: public:
virtual void f() virtual void g();
virtual void g();
virtual void h() private:
private: int y;
int i; }
}
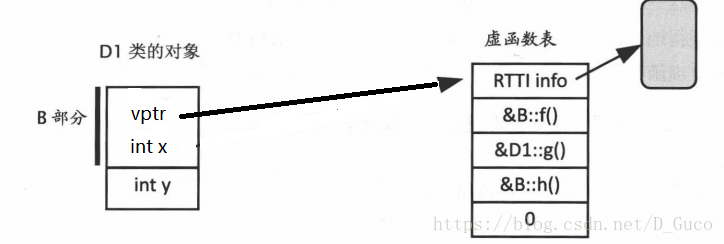
这里的RTTI时c++的运行时类型识别信息,我们知道只有带有虚函数的类才会生成虚函数表,因此动态类型强制转换只用于多态类型,在进行动态类型转换时只要取虚函数表中的第-1个元素得到type_info类对象判断其真正的类型在进行操作(vptr实际上向后移动了一个位置,编译器取虚函数的时候vptr[0]是第一个虚函数指针,vptr[-1]就能取到指向type_info的指针,一般我们不会主动去取type_info指针).
接下来看一个复杂的:
class B{
public:
virtual void f()
virtual void g()
virtual void h()
private:
int x;
}
cass D1{
public:
void ff();
virtual void f()
private:
int y;
}
class D3 : public B, public D1{
public:
virtual void f();
void hh()
private:
int w;
}
public:
virtual void f()
virtual void g()
virtual void h()
private:
int x;
}
cass D1{
public:
void ff();
virtual void f()
private:
int y;
}
class D3 : public B, public D1{
public:
virtual void f();
void hh()
private:
int w;
}
考虑下面的例子:
B* pb= new B
pb->X=0;
D3* pd3= new D3
pd3->ff();//ff在D1中
pb->X=0;
D3* pd3= new D3
pd3->ff();//ff在D1中
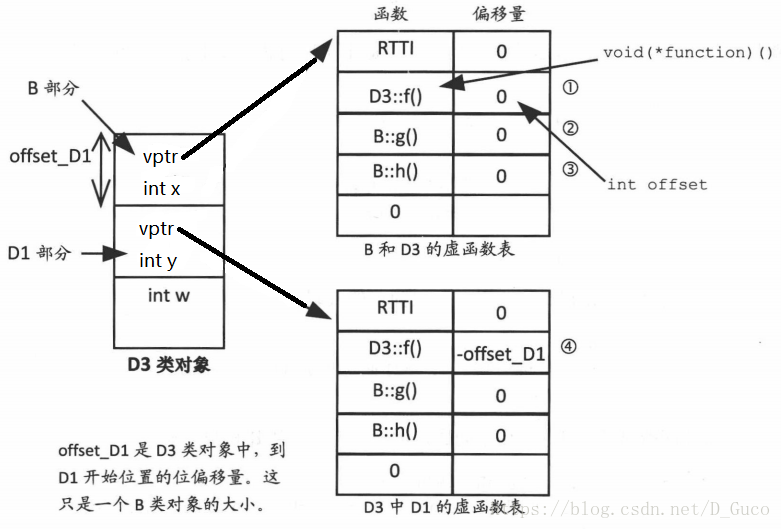
这是一个有效调用。但是,这里有一个问题。成员函数D1:ff()需要的参数是指向Dl的(this)指针,而不是指向D3的指针。D3类对象的地址与B类对象的地址相同一它们开始于相同的地址。但是,D3内的D1地址是D3(或者B)的地址加上D3到D1的偏移量。成员函数D1:ff()应该接收正确的this指针(指向D1对象的指针)。在编译时,已知D3内部Dl1的偏移量,所以可以在编译时很方便地处理这个问题,不会引入任何运行时开销。我们将D3内部D1的偏移量称为 offset D1。
因此,pd3->ff()变为:((DI*)(((char*)pd3)+ offset D1 ))->ff();编译器只需将 offset D1加入到pd3中的地址上,然后将其强制转换为D1·。但是,在将 offset DI1与pd3相加之前,必须将pd3当作char指针,而不是D3指针,以确保正确进行指针运算。因此,pd3被强制转换为char*,然后加上偏移量,最后,将所得地址转换为D1*并调用ff(),这些都在编译时完成,没有运行时开销。
继续看:
D3* pd3 = new D3;
D1* pd1 = new D3;//pd1必须指向D3中的D1部分
B* pb = new D3;
//3个指针都指向D3对象,这没问题,因为D3同时从B和D1派生。
pd3->f();//由于动态绑定,调用D3::f()
pd1->f();//还是调用D3::f(),但是pd1指向D3类对象中D1部分的开始位置。
pb->f();//D3::f()
D1* pd1 = new D3;//pd1必须指向D3中的D1部分
B* pb = new D3;
//3个指针都指向D3对象,这没问题,因为D3同时从B和D1派生。
pd3->f();//由于动态绑定,调用D3::f()
pd1->f();//还是调用D3::f(),但是pd1指向D3类对象中D1部分的开始位置。
pb->f();//D3::f()struct vtb1_entry{
void (*function)();
int offset;
}
void (*function)();
int offset;
}②在D3类对象内部,B::g()未被覆盖。因此,D3内g0的虚函数表入口是B::g()的地址。由于B和D3的地址相同,所以不需要调整this指针。所以,存储的偏移量是0
③与②相同,因为在D3中并未覆盖B::h()。
④用指向D3类对象的D1类型的指针调用f()时,被调用的函数仍然是D3::f(),因为D3覆盖了B::f()。需要注意的是,D1类型的指针指向的是D3内部的D1类对象(参见上面的pd1),然而,在进入D3::f()中时,this指针必须指向D3的开始位置,而不是D1的开始位置。D1类对象的地址是D3类对象的地址与D3类对象开始位置到D1类对象开始位置的偏移量的代数和。这个偏移量就是 offset_D1,也就是到D3类对象内部D1部分开始位置的偏移量。因此,为了获得D3的开始位置,需要加上- offset D1。这就是储存在(D3内部D1的)虚函数表中第二个位置的内容。
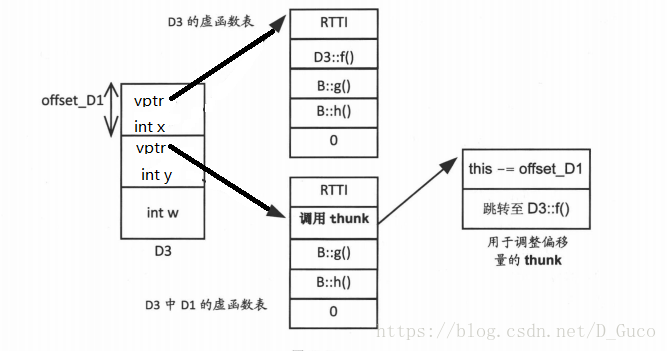
这里,(pd1->vptr[1]. function)给出了虚函数表中函数的地址,而剩下的部分是操控地址,以获得对象的开始位置。在这个例子中,偏移量是负值。
要调整this指针的偏移量,储存在虚函数中的地址则指向某段进行调整的代码( thunk),并调用合适的函数。现在,执行实际函数分成两个步骤。该方案的优点是,只有那些需要调整this指针偏移量的虚函数调用,才会有额外的开销,同时还能保持较小的虚函数表大
小。这两种方案,在计算偏移量方面的开销相同。在执行pd1->f()时,编译器像对待任何虚函数那样进行常规地操作:它在虚函数表中找到该函数,然后调用,然而这不是最终的结果,这个函数只是对this指针做出了调整,通过调整this指针的位置进而调用到实际的函数。如下图:
(a)访问非虚成员函数和数据成员非常简单,不会导致任何额外的运行时开销
(b)但是,根据编译器的实现不同,在调用虚函数时,有些调用可能导致增加虚函数表大小的额外开销,或者只有那些需要调整this指针的调用才会发生额外的运行开销,但不会增加虚函数表的大小。
所有这些问题都不能作为反对多重继承的论据。的确,这些问题涉及开销,但是,多重继承减少了编码的负担,同时也让问题的解决方案更加简洁,这当然要付出一些代价.
(a)类包含内嵌对象(即,将另一个类的对象作为数据成员),这些内嵌对象中包含复制构造函数(编译器生成或程序员定义)。
(b)类从一个或多个包含复制构造函数(程序员定义或者编译器生成)的基类派生。
(c)类声明了虚函数。
(d)当类从虚基类继承时(与虚基类是否存在复制构造函数无关)。














 1495
1495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









