对于一个Android的apk应用程序,其主要的执行代码都在其中的class.dex文件中。在程序第一次被加载的时候,为了提高以后的启动速度和执行效率,Android系统会对这个class.dex文件做一定程度的优化,并生成一个ODEX文件,存放在/data/dalvik-cache目录下。以后再运行这个程序的时候,就只要直接加载这个优化过的ODEX文件就行了,省去了每次都要优化的时间。
不过,这个优化过程会根据不同设备上Dalvik虚拟机的版本、Framework库的不同等因素而不同。在一台设备上被优化过的ODEX文件,拷贝到另一台设备上不一定能够运行。
那么,这个对应的ODEX文件到底包含了哪些内容呢?本文就通过分析Android代码中,对应生成ODEX文件的代码,来一步步解释其中的奥秘。
Android是通过dexopt程序对DEX文件进行优化的,除去一些参数的解释,我们选择其中的processZipFile函数作为切入点,这个函数是dexopt程序用来处理一个待优化的apk文件的(代码位于dalvik\dexopt\OptMain.cpp中):
- static int processZipFile(int zipFd, int cacheFd, const char* zipName,
- const char *dexoptFlags)
- {
- ……
-
- const char* bcp = getenv("BOOTCLASSPATH");
- ……
-
- bool isBootstrap = false;
- const char* match = strstr(bcp, zipName);
- if (match != NULL) {
- ……
-
- isBootstrap = true;
- }
-
- int result = extractAndProcessZip(zipFd, cacheFd, zipName, isBootstrap,
- bcp, dexoptFlags);
-
- ……
- return result;
- }
先来说说这个函数的几个入参,zipFd是要优化的那个apk应用程序的文件句柄,cacheFd是要优化后存放的那个ODEX文件的句柄,dexoptFlags表示的是优化模式。
首先,函数要获得系统中环境变量BOOTCLASSPATH的值(这个值通常是设置在init.rc中)。接下来,还要判断一下是要优化的这个程序是否就是BOOTCLASSPATH中的某一个,我们要分析的是优化自己写的程序,所以isBootstrap的值是false。
该函数接下来调用extractAndProcessZip函数。这个函数看起来比较长,我们可以顺着它的处理逻辑来分段解释一下:
- static int extractAndProcessZip(int zipFd, int cacheFd,
- const char* debugFileName, bool isBootstrap, const char* bootClassPath,
- const char* dexoptFlagStr)
- {
- ZipArchive zippy;
- ZipEntry zipEntry;
- size_t uncompLen;
- long modWhen, crc32;
- off_t dexOffset;
- int err;
- int result = -1;
- int dexoptFlags = 0;
- DexClassVerifyMode verifyMode = VERIFY_MODE_ALL;
- DexOptimizerMode dexOptMode = OPTIMIZE_MODE_VERIFIED;
- ……
-
- err = dexOptCreateEmptyHeader(cacheFd);
- if (err != 0)
- goto bail;
-
- ……
首先,函数中会调用函数dexOptCreateEmptyHeader(代码位于dalvik\libdex\OptInvocation.cpp中):
- int dexOptCreateEmptyHeader(int fd)
- {
- DexOptHeader optHdr;
- ssize_t actual;
-
- ……
-
- memset(&optHdr, 0xff, sizeof(optHdr));
- optHdr.dexOffset = sizeof(optHdr);
- actual = write(fd, &optHdr, sizeof(optHdr));
- if (actual != sizeof(optHdr)) {
- int err = errno ? errno : -1;
- return errno;
- }
-
- return 0;
- }
这个函数就是构造了一个DexOptHeader结构体,将结构体中的所有字节全部赋值成0xff。不过,函数内还是给结构体中的dexOffset变量赋了值,其值是DexOptHeader结构体的大小。最后,将其写入要优化成的那个ODEX文件中。当然,这个头几乎是空的,没什么用,后面这个头还会被改写。
我们来看看这个结构体是什么样的(代码位于dalvik\libdex\DexFile.h中):
- struct DexOptHeader {
- u1 magic[8];
-
- u4 dexOffset;
- u4 dexLength;
- u4 depsOffset;
- u4 depsLength;
- u4 optOffset;
- u4 optLength;
-
- u4 flags;
- u4 checksum;
- };
1)前面的8个字节magic[8]是魔数头,表明这个文件是一个ODEX文件,其会被设置成“dey\n036\0”;
2)接着的4个字节dexOffset表示ODEX文件中包含的那个DEX文件在ODEX文件中的偏移;
3)接着的4个字节dexLength表示ODEX文件中包含的那个DEX文件的长度;
4)接着的4个字节depsOffset表示依赖库列表段的偏移;
5)接着的4个字节depsLength表示表示依赖库列表段的长度;
6)接着的4个字节optOffset表示优化数据段的偏移;
7)接着的4个字节optLength表示优化数据段的长度。
这也就解释了为什么在dexOptCreateEmptyHeader函数中dexOffset会被设置成结构体DexOptHeader的大小,说明在这个DexOptHeader结构体后面紧接着就会放原始的待优化的那个DEX文件。
好,我们还是回到extractAndProcessZip函数中:
- ……
- dexOffset = lseek(cacheFd, 0, SEEK_CUR);
- if (dexOffset < 0)
- goto bail;
-
- ……
-
- zipEntry = dexZipFindEntry(&zippy, kClassesDex);
- if (zipEntry == NULL) {
- goto bail;
- }
-
- if (dexZipGetEntryInfo(&zippy, zipEntry, NULL, &uncompLen, NULL, NULL,
- &modWhen, &crc32) != 0)
- {
- goto bail;
- }
-
- uncompLen = uncompLen;
- modWhen = modWhen;
- crc32 = crc32;
-
- if (dexZipExtractEntryToFile(&zippy, zipEntry, cacheFd) != 0) {
- goto bail;
- }
-
- ……
首先,会通过读取ODEX文件的当前指针位置来获得DEX文件偏移的大小(其实没必要,前面看到了,这个偏移一定就是DexOptHeader结构体的大小)。然后,找到这个apk文件中,“class.dex”文件的ZIP项(apk文件其实就是一个zip文件)。通过这个ZIP项,可以获得对应文件的一些信息,包括它的长度、修改时间和CRC校验值。最后,将这个class.dex文件直接写到ODEX文件中去。
分析到这里,可以看出在ODEX文件中,其实是包含了一个完整的DEX文件的。不过在后面的优化步骤中,其中的某些指令会被优化(通过rewriteDex函数,有机会会另外介绍这个),和原始的那个DEX文件已经并不完全相同了。
好,我们接着看extractAndProcessZip函数:
- ……
- if (!dvmContinueOptimization(cacheFd, dexOffset, uncompLen, debugFileName,
- modWhen, crc32, isBootstrap))
- {
- goto bail;
- }
-
- result = 0;
-
- bail:
- ……
- return result;
- }
该函数接着调用了dvmContinueOptimization函数(代码位于dalvik\vm\analysis\DexPrepare.cpp中),接着优化:
- bool dvmContinueOptimization(int fd, off_t dexOffset, long dexLength,
- const char* fileName, u4 modWhen, u4 crc, bool isBootstrap)
- {
- DexClassLookup* pClassLookup = NULL;
- RegisterMapBuilder* pRegMapBuilder = NULL;
-
- ……
-
- off_t depsOffset, optOffset, endOffset, adjOffset;
- int depsLength, optLength;
- u4 optChecksum;
-
- depsOffset = lseek(fd, 0, SEEK_END);
- if (depsOffset < 0) {
- goto bail;
- }
- adjOffset = (depsOffset + 7) & ~(0x07);
- if (adjOffset != depsOffset) {
- depsOffset = adjOffset;
- lseek(fd, depsOffset, SEEK_SET);
- }
-
- if (writeDependencies(fd, modWhen, crc) != 0) {
- goto bail;
- }
-
- ……
代码首先通过读取ODEX文件当前末尾的位置,获得了存放所谓依赖(Dependency)库列表的位置。不过,这个依赖库列表必须被存放到64比特对齐的位置,也就是8字节对齐,所以接下来的代码还要计算一下修正后的位置,并把当前文件指针指向那里。接着调用了writeDependencies函数,写入依赖库列表。那么,这个依赖库列表到底是什么东西,该以什么样的格式存放呢?我们接着看writeDependencies函数的实现(代码位于dalvik\vm\analysis\DexPrepare.cpp中):
- static int writeDependencies(int fd, u4 modWhen, u4 crc)
- {
- u1* buf = NULL;
- int result = -1;
- ssize_t bufLen;
- ClassPathEntry* cpe;
- int numDeps;
-
- numDeps = 0;
- bufLen = 0;
- for (cpe = gDvm.bootClassPath; cpe->ptr != NULL; cpe++) {
- const char* cacheFileName =
- dvmPathToAbsolutePortion(getCacheFileName(cpe));
- assert(cacheFileName != NULL);
-
- numDeps++;
- bufLen += strlen(cacheFileName) +1;
- }
-
- bufLen += 4*4 + numDeps * (4+kSHA1DigestLen);
-
- ……
可以看到,所谓的依赖库列表,其实就是全局变量gDvm中bootClassPath变量中存放的所有ClassPathEntry,其实也就是系统环境变量BOOTCLASSPATH中存放的列表。这些指定的库,都会被预先加载进Dalvik虚拟机,供你的程序直接使用。
代码首先将所有的依赖库都遍历一遍,获得该库文件对应的优化文件的绝对路径(依赖库本身也是一个程序,同样是跑在Dalvik虚拟机下的,照样会被优化)。这次遍历其实只是想计算一下到底要开多大的缓存存放全部要写入ODEX文件的数据,所以最后会把这个路径的长度加上1(因为字符串最后要补上“\0”)累加到bufLen变量中。循环结束后,只是得到了所有依赖库路径字符串的长度,还要加上一个头的长度(4个4字节结构体),同时对每个依赖库还要记录下它的SHA1摘要,因此还要加上摘要的长度。
好了,在堆上分配好空间之后,就要开始正式写数据了:
- ……
- buf = (u1*)malloc(bufLen);
-
- set4LE(buf+0, modWhen);
- set4LE(buf+4, crc);
- set4LE(buf+8, DALVIK_VM_BUILD);
- set4LE(buf+12, numDeps);
-
- u1* ptr = buf + 4*4;
- for (cpe = gDvm.bootClassPath; cpe->ptr != NULL; cpe++) {
- const char* cacheFileName =
- dvmPathToAbsolutePortion(getCacheFileName(cpe));
- assert(cacheFileName != NULL);
-
- const u1* signature = getSignature(cpe);
- int len = strlen(cacheFileName) +1;
-
- ……
-
- set4LE(ptr, len);
- ptr += 4;
- memcpy(ptr, cacheFileName, len);
- ptr += len;
- memcpy(ptr, signature, kSHA1DigestLen);
- ptr += kSHA1DigestLen;
- }
-
- assert(ptr == buf + bufLen);
-
- result = sysWriteFully(fd, buf, bufLen, "DexOpt dep info");
-
- free(buf);
- return result;
首先要写入一个头,其主要有4个4字节组成,结构如下:
1)最开始4个字节写的是前面获得的class.dex文件的修改时间;
2)接着的4个字节是class.dex文件的CRC校验值;
3)接着的4个字节是当前Dalvik虚拟机的版本号,对于Android 4.4.2系统来说,其值是27(代码位于dalvik\vm\DalvikVersion.h中);
- #define DALVIK_VM_BUILD 27
4) 最后的4个字节是表示到底有多少个依赖库。
注意,这些值都是以小端(Little-Endian)字节序写入的。
接着,代码又遍历了一遍所有的依赖库,对于每一条依赖库来说,都要写入其优化文件名字符串长度、优化文件名字符串还有这个依赖库的SHA1值。
最后,将缓存里的值全部写入ODEX文件中。
好了,写完了依赖库,我们还是回到dvmContinueOptimization函数中:
- ……
- optOffset = lseek(fd, 0, SEEK_END);
- depsLength = optOffset - depsOffset;
-
- adjOffset = (optOffset + 7) & ~(0x07);
- if (adjOffset != optOffset) {
- optOffset = adjOffset;
- lseek(fd, optOffset, SEEK_SET);
- }
-
- if (!writeOptData(fd, pClassLookup, pRegMapBuilder)) {
- goto bail;
- }
- ……
处理的逻辑和前面很像,也还是要8字节对齐,不过这次要写的是所谓的优化数据(Optimization Data)。那么优化数据包含哪些呢?我们接着看writeOptData函数的实现(代码位于dalvik\vm\analysis\DexPrepare.cpp中):
- static bool writeOptData(int fd, const DexClassLookup* pClassLookup,
- const RegisterMapBuilder* pRegMapBuilder)
- {
- if (!writeChunk(fd, (u4) kDexChunkClassLookup,
- pClassLookup, pClassLookup->size))
- {
- return false;
- }
-
- if (pRegMapBuilder != NULL) {
- if (!writeChunk(fd, (u4) kDexChunkRegisterMaps,
- pRegMapBuilder->data, pRegMapBuilder->size))
- {
- return false;
- }
- }
-
- if (!writeChunk(fd, (u4) kDexChunkEnd, NULL, 0)) {
- return false;
- }
-
- return true;
- }
可以看出,代码写了两个数据块(Chunk),再写了一个表示结尾的数据块,就结束了。那么,数据块的结构又是怎样的呢?我们接着看writeChunk函数(代码位于dalvik\vm\analysis\DexPrepare.cpp中):
- static bool writeChunk(int fd, u4 type, const void* data, size_t size)
- {
- union {
- char raw[8];
- struct {
- u4 type;
- u4 size;
- } ts;
- } header;
-
- ……
-
- header.ts.type = type;
- header.ts.size = (u4) size;
- if (sysWriteFully(fd, &header, sizeof(header),
- "DexOpt opt chunk header write") != 0)
- {
- return false;
- }
-
- if (size > 0) {
- if (sysWriteFully(fd, data, size, "DexOpt opt chunk write") != 0)
- return false;
- }
-
- if ((size & 7) != 0) {
- int padSize = 8 - (size & 7);
- lseek(fd, padSize, SEEK_CUR);
- }
-
- assert( ((int)lseek(fd, 0, SEEK_CUR) & 7) == 0);
-
- return true;
- }
可以看到,每一个数据块都有一个8字节的头,前4字节表示这个数据块的类型,后4个字节表示这个数据块占用多少字节的空间。头之后,就是数据块的具体内容。最后,还要保证数据块8字节对齐,适当的在后面填充数据。
数据块的类型主要有三种,分别是(代码位于dalvik\libdex\DexFile.h中):
- enum {
- kDexChunkClassLookup = 0x434c4b50,
- kDexChunkRegisterMaps = 0x524d4150,
-
- kDexChunkEnd = 0x41454e44,
- };
第一种类型是用来存放针对该DEX文件的DexClassLookup结构,它主要是用来帮助快速查找DEX中的某个类的,想要具体了解的话,可以参考《Dalvik虚拟机中DexClassLookup结构解析》一文。
最后一种类型只是用来表示数据块结束了,没什么好说的。
第二种类型是用来存放针对该DEX文件的寄存器图(Register Map)信息的,它主要用来帮助Dalvik虚拟机做精确GC用的。在《Dalvik虚拟机中RegisterMap结构解析》一文中,我介绍了一下RegisterMap的大致结构以及用处。不过RegisterMap是针对某一个方法的,而DEX文件中有包含了许多类,每个类又有很多方法,这就需要将大量不同的RegisterMap结构按照某种规则存放下来。我们在前面的代码可以看到,这个块的数据是通过一个叫做RegisterMapBuilder的结构体来储存的,而这个结构体又是通过dvmGenerateRegisterMaps函数获得的(代码位于dalvik\vm\analysis\DexPrepare.cpp内的dvmContinueOptimization函数中):
- ……
- if (dvmDexFileOpenPartial(dexAddr, dexLength, &pDvmDex) != 0) {
- success = false;
- } else {
- if (gDvm.generateRegisterMaps) {
- pRegMapBuilder = dvmGenerateRegisterMaps(pDvmDex);
- if (pRegMapBuilder == NULL) {
- success = false;
- }
- }
-
- DexHeader* pHeader = (DexHeader*)pDvmDex->pHeader;
- updateChecksum(dexAddr, dexLength, pHeader);
-
- dvmDexFileFree(pDvmDex);
- }
- ……
我们先来看看RegisterMapBuilder结构体里有什么(代码位于dalvik\vm\analysis\RegisterMap.h中):
- struct RegisterMapBuilder {
- void* data;
- size_t size;
-
- MemMapping memMap;
- };
没什么特别的,有一个存放数据的data域,一个估计是表明数据大小的size域,还有一个私有的memMap域。
既然什么想要的信息都没有,那接下来我们只能顺藤摸瓜,看看这个结构体中的数据是如何生成的(代码位于dalvik\vm\analysis\RegisterMap.cpp中):
- RegisterMapBuilder* dvmGenerateRegisterMaps(DvmDex* pDvmDex)
- {
- RegisterMapBuilder* pBuilder;
-
- pBuilder = (RegisterMapBuilder*) calloc(1, sizeof(RegisterMapBuilder));
- if (pBuilder == NULL)
- return NULL;
-
- if (sysCreatePrivateMap(4 * 1024 * 1024, &pBuilder->memMap) != 0) {
- free(pBuilder);
- return NULL;
- }
-
- size_t actual = writeMapsAllClasses(pDvmDex, (u1*)pBuilder->memMap.addr,
- pBuilder->memMap.length);
- if (actual == 0) {
- dvmFreeRegisterMapBuilder(pBuilder);
- return NULL;
- }
-
- pBuilder->data = pBuilder->memMap.addr;
- pBuilder->size = actual;
- return pBuilder;
- }
代码很简单,主要是在内存中开了一个足够大的空间,然后调用函数writeMapsAllClasses对其进行写入,最后将内存空间的地址和实际写入的字节数放到data和size域中。所以,奥秘应该就在函数writeMapsAllClasses函数里(代码位于dalvik\vm\analysis\RegisterMap.cpp中):
- static size_t writeMapsAllClasses(DvmDex* pDvmDex, u1* basePtr, size_t length)
- {
- DexFile* pDexFile = pDvmDex->pDexFile;
- u4 count = pDexFile->pHeader->classDefsSize;
- RegisterMapClassPool* pClassPool;
- u4* offsetTable;
- u1* ptr = basePtr;
- u4 idx;
-
- pClassPool = (RegisterMapClassPool*) ptr;
- ptr += offsetof(RegisterMapClassPool, classDataOffset);
- offsetTable = (u4*) ptr;
- ptr += count * sizeof(u4);
-
- pClassPool->numClasses = count;
-
- for (idx = 0; idx < count; idx++) {
- const DexClassDef* pClassDef;
- const char* classDescriptor;
- ClassObject* clazz;
-
- pClassDef = dexGetClassDef(pDexFile, idx);
- classDescriptor = dexStringByTypeIdx(pDexFile, pClassDef->classIdx);
-
- clazz = NULL;
- if ((pClassDef->accessFlags & CLASS_ISPREVERIFIED) != 0)
- clazz = dvmLookupClass(classDescriptor, NULL, false);
-
- if (clazz != NULL) {
- offsetTable[idx] = ptr - basePtr;
-
- if (!writeMapsAllMethods(pDvmDex, clazz, &ptr,
- length - (ptr - basePtr)))
- {
- return 0;
- }
-
- ptr = align32(ptr);
- } else {
- assert(offsetTable[idx] == 0);
- }
- }
-
- if (ptr - basePtr >= (int)length) {
- dvmAbort();
- }
-
- return ptr - basePtr;
- }
代码中又涉及到了一个新的结构体RegisterMapMethodPool(代码位于dalvik\vm\analysis\RegisterMap.h中):
- struct RegisterMapClassPool {
- u4 numClasses;
- u4 classDataOffset[1];
- };
所以,代码首先写入了DEX文件中存放的所有类的个数。接着遍历DEX文件中的所有类,先是填写一个所谓的偏移表,其中的每一项都是4个字节,有几个类就有几项。每一项的值都表示其后的一块数据相对于结构体头之间的偏移。并且那块数据所代表的类在DEX文件中出现的下标,就是这个偏移表的下标。最后,对每一个类,调用writeMapsAllMethods函数,在指定偏移位置写入数据。注意,每个类的数据并不一定是紧挨着存放的,因为每块数据要32比特对齐。
- static bool writeMapsAllMethods(DvmDex* pDvmDex, const ClassObject* clazz,
- u1** pPtr, size_t length)
- {
- RegisterMapMethodPool* pMethodPool;
- u1* ptr = *pPtr;
- int i, methodCount;
-
- if (clazz->virtualMethodCount + clazz->directMethodCount >= 65536) {
- return false;
- }
-
- pMethodPool = (RegisterMapMethodPool*) ptr;
- ptr += offsetof(RegisterMapMethodPool, methodData);
- methodCount = 0;
-
- for (i = 0; i < clazz->directMethodCount; i++) {
- const Method* meth = &clazz->directMethods[i];
- if (dvmIsMirandaMethod(meth))
- continue;
- if (!writeMapForMethod(&clazz->directMethods[i], &ptr)) {
- return false;
- }
- methodCount++;
- }
-
- for (i = 0; i < clazz->virtualMethodCount; i++) {
- const Method* meth = &clazz->virtualMethods[i];
- if (dvmIsMirandaMethod(meth))
- continue;
- if (!writeMapForMethod(&clazz->virtualMethods[i], &ptr)) {
- return false;
- }
- methodCount++;
- }
-
- pMethodPool->methodCount = methodCount;
-
- *pPtr = ptr;
- return true;
- }
这里又引入了一个叫做RegisterMapMethodPool的结构体(代码位于dalvik\vm\analysis\RegisterMap.h中):
- struct RegisterMapMethodPool {
- u2 methodCount;
- u4 methodData[1];
- };
也没什么重要的信息,所以还是只能回过头看writeMapsAllMethods函数的实现。通过阅读可以看出,代码遍历了类中所有的函数,不过是以先直接方法后虚拟方法的顺序遍历的(同时还可以看出,一个类中的所有方法数目不能超过65535)。然后对每一个方法调用writeMapForMethod(代码位于dalvik\vm\analysis\RegisterMap.cpp中)函数,顺序的在methodData段写入数据(不用考虑对齐的问题):
- static bool writeMapForMethod(const Method* meth, u1** pPtr)
- {
- if (meth->registerMap == NULL) {
- *(*pPtr)++ = kRegMapFormatNone;
- return true;
- }
-
- size_t mapSize = computeRegisterMapSize(meth->registerMap);
- memcpy(*pPtr, meth->registerMap, mapSize);
-
- assert(**pPtr == meth->registerMap->format);
- **pPtr &= ~(kRegMapFormatOnHeap);
-
- *pPtr += mapSize;
-
- return true;
- }
很简单,直接写入对应方法的寄存器图RegisterMap结构体数据就好了。如果方法没有寄存器图RegisterMap的话,就写入一个字节,值为kRegMapFormatNone(1)。关于RegisterMap的结构以及用处,可以参考《Dalvik虚拟机中RegisterMap结构解析》一文。
最后,再回到函数dvmContinueOptimization中,看看收尾的工作:
- ……
- endOffset = lseek(fd, 0, SEEK_END);
- optLength = endOffset - optOffset;
-
- if (!computeFileChecksum(fd, depsOffset,
- (optOffset+optLength) - depsOffset, &optChecksum))
- {
- goto bail;
- }
-
- DexOptHeader optHdr;
- memset(&optHdr, 0xff, sizeof(optHdr));
- memcpy(optHdr.magic, DEX_OPT_MAGIC, 4);
- memcpy(optHdr.magic+4, DEX_OPT_MAGIC_VERS, 4);
- optHdr.dexOffset = (u4) dexOffset;
- optHdr.dexLength = (u4) dexLength;
- optHdr.depsOffset = (u4) depsOffset;
- optHdr.depsLength = (u4) depsLength;
- optHdr.optOffset = (u4) optOffset;
- optHdr.optLength = (u4) optLength;
- #if __BYTE_ORDER != __LITTLE_ENDIAN
- optHdr.flags = DEX_OPT_FLAG_BIG;
- #else
- optHdr.flags = 0;
- #endif
- optHdr.checksum = optChecksum;
-
- fsync(fd);
-
- lseek(fd, 0, SEEK_SET);
- if (sysWriteFully(fd, &optHdr, sizeof(optHdr), "DexOpt opt header") != 0)
- goto bail;
-
- result = true;
-
- bail:
- dvmFreeRegisterMapBuilder(pRegMapBuilder);
- free(pClassLookup);
- return result;
- }
这里主要是重写处于ODEX头部的DexOptHeader结构体中的数据。最开始的魔数是“dey\n036\0”(代码位于dalvik\libdex\DexFile.h中):
- #define DEX_OPT_MAGIC "dey\n"
- #define DEX_OPT_MAGIC_VERS "036\0"
下面是DEX文件的偏移和长度、依赖库列表的偏移和长度以及优化数据的偏移和长度。下面的flags域说明是用的大端字节序还是小端字节序,一般是小端,所以是0。最后是校验和的值,注意这个校验和不是算整个ODEX文件的,而是只算依赖库列表段和优化数据段的。
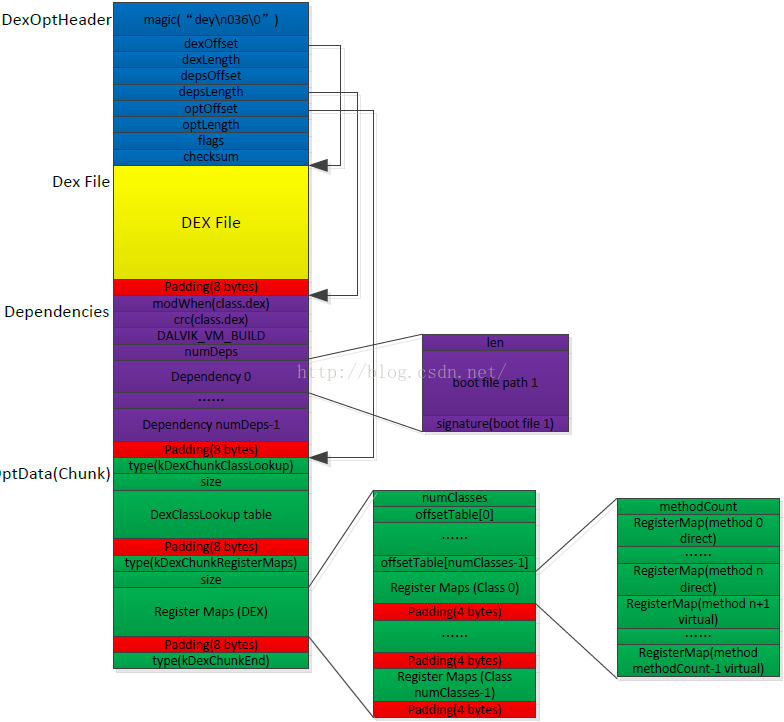
最后,画张图将整体结构总结一下:






















 1185
1185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









