









1、 列表:待搜索的数据集合。
2、 关键字:要查找的那个数据。
3、 查找,检索:一种算法过程。给出一个key值(关键字),在含有若干个结点的序列中找出它。
4、 查找表:同一类型的数据元素的集合。
5、 静态查找表:查询某个元素、检索指定元素的属性。
6、 动态查找表:查找后插入、删除。
7、 查找成功:当某个元素的key值等于给定值k,返回该元素的位置。
8、 查找失败:所有元素的key值均不等于给定的值k,返回表示失败的标识。
二、基于线性表的查找:
1、 顺序查找:<适合对象——无序或有序队列>
(1)思想:逐个比较,直到找到或者查找失败。
(2)时间复杂度:T(n) = O(n)。
(3)空间复杂度:S(n) = O(n)。
(4)程序:
Int SeqSearch(RecordList l, KeyType key)
{
l.r[0].key = k; //k作哨兵,减少用for循环判断下标是否越界的操作
I = l.length;
while(l.r[i].key != k)
i--;
return I;
} (5)缺点:当n较大时,平均查找长度较大,效率低。
2、 折半查找:<适合对象——只是适用于有序表,且限于顺序存储结构(线性链表无法进行折半查找)>
(1)思想:又称二分查找,对于已经按照一定顺序排列好的列表,每次都用关键字和中间的元素对比,然后判断是在前部分还是后部分还是就是中间的元素,然后继续用关键字和中间的元素对比。
(2)时间复杂度:T(n) =O(logn)。具有n 个结点的完全二叉树的深度为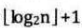
(3)程序:
Int BinSrch(RecordList l, KeyType k)
{
low = 1;
high = l.length;
while(low <= high)
{
mid = (low + high) / 2;
if(k == l.r[mid].key)
return mid;
else if(k < l.r[mid].key)
high = mid -1;
else
low = mid + 1;
}
return 0;
} (4)小结:由于折半查找的前提条件是需要有序表顺序存储,对于静态查找表,一次排序后不再变化,折半查找比较适合。但对于需要频繁执行插入或删除操作的数据集来说,维护有序的排序会带来不小的工作量,则不建议使用。
3、 分块查找:<适合对象——块内的元素可以无序,但块之间是有序的>
(1)思想:把无序的列表分成若干子块(子表),然后建立一个索引表,记录每个子块中的某个关键字(最大的数或是最小的数),然后用关键字和这个索引表进行对比。该索引表还存储子块的起始位置,所以可以使用折半查找或者顺序查找确定关键字所在的子块位置。进入子块后,使用顺序查找查找。
(2)结构:分块索引的索引项结构分三个数据项,最大关键码,它存储每一块中的最大关键字,这样的好处就是可以使得在它之后的下一块中的最小关键字也能比这一块最大的关键字要大;块长,便于循环时使用;首数据元素指针,便于开始对这一块中记录进行遍历。
(3)时间复杂度:O(logn)
(4)平均查找长度:设n 个记录的数据集被平均分成m块,每个块中有t 条记录,显然n=mt,或者说m=n/t。再假设Lb为查找索引表的平均查找长度,因最好与最差的等概率原则,所以Lb的平均查找长度为(m+1)/2。 Lw为块中查找记录的平均查找长度,同理可知它的平均查找长度为(t+1)/2。这样分块索引查找的平均查找长度为:
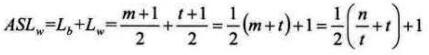
由此可知,平均长度不仅仅取决于数据集的总记录数n,还和每一个块的记录个数t相关。 最佳的情况就是分的块数m与块中的记录数t相同,此时意味着n=mt=t^2。即

可见,分块索引的效率比顺序查找的O(n)是高了不少,不过显然与折半查找的O(logn)相比还有不小的差距。因此在确定所在块的过程中,由于块间有序,所以可以应用折半等手段来提高效率。
(5)程序:
/**
* 分块查找
*
* @param index 索引表,其中放的是各块的最大值
* @param st 顺序表,
* @param key 要查找的值
* @param m 顺序表中各块的长度相等,为m
* @return
*/
private int BlockSearch(int[ ] index, int[ ] st, int key, int m)
{
// 在序列st数组中,用分块查找方法查找关键字为key的记录
// 1.在index[ ] 中折半查找,确定要查找的key属于哪个块中
int i = partSearch(index, key);
if(i >= 0)
{
int j = i > 0 ? i * m : i;
int len = (i + 1) * m;
// 在确定的块中用顺序查找方法查找key
for(int k = j; k < len; k++)
{
if(key == st[k])
{
System.out.println("查询成功");
return k;
}
}
}
System.out.println("查找失败");
return -1;
}
public int partSearchs(int[] data, int tmpData)
{
int mid;
int low = 0;
int high = data.length - 1;
while(low <= high)
{
mid = (low + high) / 2; // 中间位置
if(tmpData == data[mid])
{
return mid;
}
else if(tmpData < data[mid])
{
high = mid - 1;
}
else
{
low = mid + 1;
return low;
}
}
return -1; // 没有查找到
}
三、基于树的查找:
1、 二叉排序树:
(1)思想:二叉排序树:①若它的左子树非空,则左子树上所有节点的值均小于它的根节点的值;②若它的右子树非空,则右子树上所有结点的值均大于(或大于等于)它的根节点的值;③它的左、右子树也分别为二叉排序树。查找的时候,中序遍历二叉树,得到一个递增有序序列。查找思路类似于折半查找。
(2)时间复杂度:插入一个节点算法的O(㏒n),插入n个的总复杂度为O(n㏒n)。
(4)程序:
BSTree SearchBST(BSTree bst, KeyType key)//递归算法
{
If(!bst)
return NULL;
else if(bst->key == key)
return bst;
else if(bst->key > key)
return SearchBST(bst->lchild, key);
else
return SearchBST(bst->rchild, key);
}
BSTree SearchBST(BSTree bst, KeyType key)//非递归算法
{
BSTree q;
q = bst;
while(q)
{
If(q->key == key)
return q;
else if(q->key > key)
q = q->lchild;
else
q = q->rchild;
}
return NULL;
} 3、 B_树:(略)
四、计算式查找:
1、 哈希查找:
(1)思想:首先在元素的关键字k和元素的存储位置p之间建立一个对应关系H,使得p=H(k),H称为哈希函数。创建哈希表时,把关键字为k的元素直接存入地址为H(k)的单元;以后当查找关键字为k的元素时,再利用哈希函数计算出该元素的存储位置p=H(k),从而达到按关键字直接存取元素的目的。难点在于处理冲突的方式:①开放定址法②再哈希法③链地址法④建立公共溢出区。
(2)时间复杂度:O(1)
(3)程序:
#define m <哈希表长度>
#define NULLKEY <代表空记录的关键字值>
typedef int KeyType;
typedef struct
{
KeyType key;
}RecordType;
typedef RecordType HashTable[m];
int HashSearch(HashTable ht, KeyType K)
{
h0 = hash(K);
if(ht[h0].key == NULLKEY)
return -1;
else if(ht[h0].key == K)
return h0;
else
{
for(i = 1; i <= m - 1; i++)
{
hi = (h0 + 1) % m;
if(ht[hi].key == NULLKEY)
return -1;
else if(ht[hi].key == K)
return hi;
}
return -1;
}
} 













 489
489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









