







 本文介绍了稀疏自动编码(Sparse Autoencoder)的基本结构和作用,它是一种非监督神经网络,用于学习输入数据的低维表示。通过引入稀疏性约束,使隐藏层节点大部分抑制,小部分激活,以发现数据的潜在结构。损失函数结合了相对熵,以保持隐藏层的平均激活度在一个较小的值。文章详细讨论了损失函数、其偏导数计算以及参数求解的过程。
本文介绍了稀疏自动编码(Sparse Autoencoder)的基本结构和作用,它是一种非监督神经网络,用于学习输入数据的低维表示。通过引入稀疏性约束,使隐藏层节点大部分抑制,小部分激活,以发现数据的潜在结构。损失函数结合了相对熵,以保持隐藏层的平均激活度在一个较小的值。文章详细讨论了损失函数、其偏导数计算以及参数求解的过程。
在之前的博文中,我总结了神经网络的大致结构,以及算法的求解过程,其中我们提高神经网络主要分为监督型和非监督型,在这篇博文我总结下一种比较实用的非监督神经网络——稀疏自编码(Sparse Autoencoder)。
1.简介
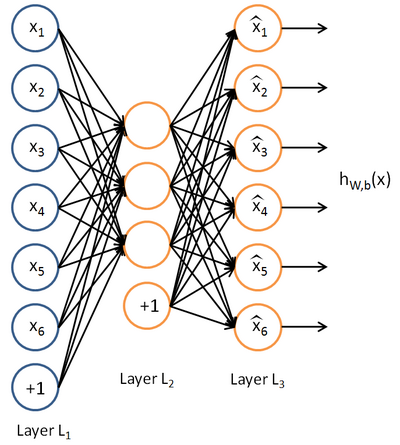
上图是稀疏自编码的一般结构,最大的特点是输入层结点数(不包括bias结点)和输出层结点数相同,而隐藏层结点个数少于输入层和输出层结点的个数。该模型的目的是学习得到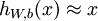
在监督神经网络中,训练数据为(x(i),y(i)),我们希望模型能够准确的预测y,从而使得损失函数(具体实际需求建立不同的损失函数)的值最小
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 928
928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









