







自动确定k值的k均值聚类
说实话刚刚看到这个作业我是懵逼的。k均值本身不难,可是要自动确定k值,我就不知所措了。于是脑补了无数种方法,最后决定求助度娘。研究了几个小时以后,渐渐有了思路,于是一步步展开,写一下自己的想法吧。
K均值聚类
首先实现传统的简单K均值(也就是指定k的情况)聚类。K均值可能是最容易理解的机器学习算法了。但是具体来说,这一算法在细节上也存在很多不同的版本,我选取了一个自认为效率比较高的版本。大体步骤如下:
从数据中随机抽取一个点 c1 作为第一个中心点;
计算各点到 c1 的距离(欧氏距离),选取距离最远的点 c2 作为第二个中心点;
重新计算数据到各个中心点的距离,并将数据划分到距离其最近的中心点;
选择3中离中心点最远的数据点 cm ,将其作为第 m 个中心点;
重复步骤3和4,直到找到 k 个中心点;
执行步骤3进行划分,之后求每一类下数据的坐标平均值,并将中心点坐标设为该平均值;
重复步骤6,直到达到最大迭代次数或中心点坐标变化小于阈值。
上述过程可能写得比较繁琐,说简单点就是先初始化k个点,然后根据算距离->划分->更新中心点这一思路来进行迭代。只不过初始化k个点我用的是求距离原中心点距离最远的点这一方法,比直接取k个随机数点要复杂一些。
那么首先在Python中实现上述代码,重要部分我都用注释写出来了。
# 该函数用于计算当k指定时的k均值中心点
def __fit_k_means(self, data, k):
data_size, distance_group = len(data), []
# 随机选取第一个中心点
central_dots = [data[np.random.randint(0, data_size, dtype=np.int)]]
distance_group.append(self.__calc_distance(central_dots[0], data))
for counter in range(k-1):
# 设当前已经有了k个中心点,则每个点都会被分配到一个中心点
# 寻找距离其中心点距离最远的点,将其分割出来作为新的中心点
# 重复上述步骤k-1次,即可得到k个中心点
farthest_dot = np.argmax(np.min(distance_group, axis=0))
distance_group.append(self.__calc_distance(data[farthest_dot], data))
central_dots.append(data[farthest_dot])
data_type = np.argmin(distance_group, axis=0)
# 标准k均值算法步骤,迭代更新各中心点坐标,最大迭代次数50
for repeat_times in range(50):
new_dots = np.copy(central_dots)
for idx in range(len(central_dots)):
new_dots[idx] = np.average(data[np.where(data_type == idx)], axis=0)
# 如果更新以后和更新之前的差距小于临界值,则停止迭代
if np.max(np.linalg.norm(new_dots - central_dots, axis=0) < 0.1):
break
distance_group.clear()
central_dots = new_dots
for dot in central_dots:
# 按照新的中心点坐标更新各点到中心点距离
distance_group.append(self.__calc_distance(dot, data))
data_type = np.argmin(distance_group, axis=0)
return central_dots, distance_group, data_type可以看出这个函数是私有的,因为这个函数并不具有自动确定k值的功能,只是用于给其他函数调用的。接下来实现关键的“确定k值”的代码。据说k值的确定是一个难题,并没有绝对高效的方法,下面我写的方法对于简单数据效果挺好的,但是一旦数据复杂(维度高或者数据量大),结果如何我就不知道啦~
自动确定k值
确定k值需要指定一个上界
令 ki 从1开始,循环到 max_k ,对于每个 ki ,调用上面的函数获得k均值聚类器 Ci ;
利用 Ci 对数据进行聚类(__fit_k_means函数为了简单起见,直接将聚类结果作为返回值返回);
利用2中的聚类结果,对每个簇(类别) Tx(x∈(1,k)) ,计算其半径。半径的定义为距离中心最远的点到中心的距离;
求得3中所有类型半径之和,然后开根号并乘上 ki ,得到结果 ri ;
循环结束后,计算使得 ri 下降速度最快的 i ,则
i 为最佳k值。
说实话上述步骤有点哲♂学,哦不……玄学成分。主要思路是求半径之和。但是很明显,k 越大半径之和越小,极端情况下k等于数据个数,那么每个数据到其中心点距离都为0,半径之和就是0了。所以这里需要引入k进行抑制,k越大,半径乘上k的平方可能就会下降的比较缓慢了。考虑到半径乘k的平方可能不利于计算(有可能产生inf),所以改成半径的平方根乘上k。
那么,思路大概就是这样,接下来上代码:
def fit(self, data):
central_dots, radius = [], np.zeros(self.__max_k, np.float32)
# 寻找最佳的k值,k值范围在1到max_k之间
for k in range(1, self.__max_k):
_, distance_group, data_type = self.__fit_k_means(data, k)
type_distance = np.min(distance_group, axis=0)
central_dots.append(_)
# 计算各个簇的半径(中心点到簇中最远的点的距离)之和
for idx in range(k):
type_data_idx = np.where(data_type == idx)
radius[k] += np.max(type_distance[type_data_idx])
# 加权求和,k用于抑制
radius[k] = np.sqrt(radius[k]) * k
# 交叉相减,得出半径之和下降最快的k值,并认定为最佳k值
best_k = np.argmax(radius[:self.__max_k-1] - radius[1:])
self.__dots = central_dots[best_k]这段代码并不长,应该不难理解。接下来就可以测试啦~本次测试选用的数据集是网上找的,我也不知道名字,大家可以到项目文件夹的Data目录中查看。原数据集总共有4个类别,为了测试自动确定k的效果,我分别选用2类、3类、4类来进行测试。另外,聚类实际上是不需要训练的,但是为了方便起见,我还是将训练和测试分开了。数据准备部分的代码如下:
if __name__ == '__main__':
print('正在初始化聚类器')
data_file = open('Data/2dims.txt')
color_list = ['red', 'blue', 'green', 'black', 'pink', 'orange', 'purple', 'gray', 'gold']
data_lines, data = data_file.readlines(), []
data_type_count = np.zeros([4], np.int)
for line in data_lines:
raw_data = line.split('\t')
data_type_count[int(raw_data[0]) - 1] += 1
data.append(np.array(raw_data[1:], np.float32))
cls = KMeans.Classifier(max_k=9)
for n in range(3):
# 分别选取两类、三类和四类数据进行训练
data_n_types = np.array(data[:np.sum(data_type_count[:n+2])], np.float32)
print('正在对 %d 种类型的数据进行聚类...' % (n + 2), end='')
np.random.shuffle(data_n_types)
cls.fit(data_n_types)
label_n_types = cls.predict(data_n_types)
for i in range(9):
# 最大的可能种类为9种,所以用不同颜色绘制出不同种类下的样本点
type_i_in_n = data_n_types[np.where(label_n_types == i)]
scatter(type_i_in_n[:, 0], type_i_in_n[:, 1], c=color_list[i], s=20)
print('完毕')
show()
data_file.close()这是我第一次使用可视化。为了检验效果,我准备了9种颜色,这样一来如果k选择错误,多出来的种类可以很直观的看出来。程序针对2类、3类和4类分别进行训练和验证,并分别输出结果。
2类的结果如下:
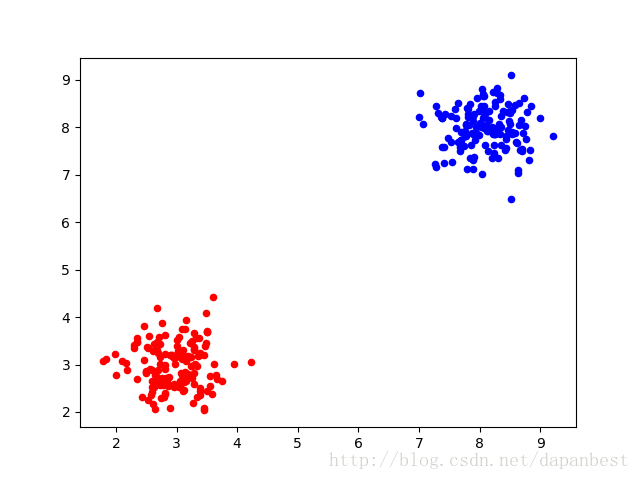
3类的结果如下:
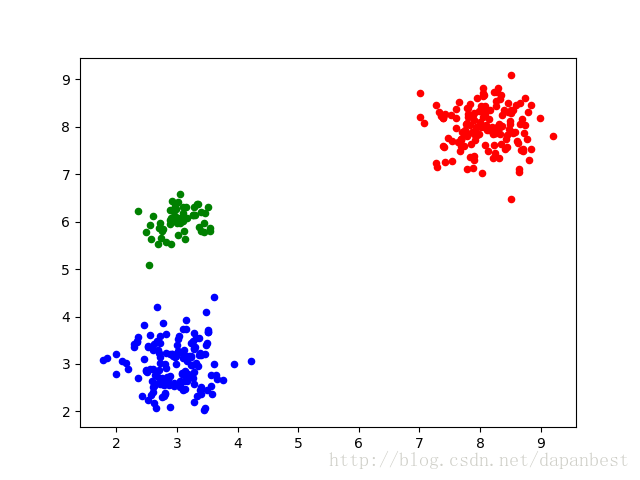
4类的结果如下:
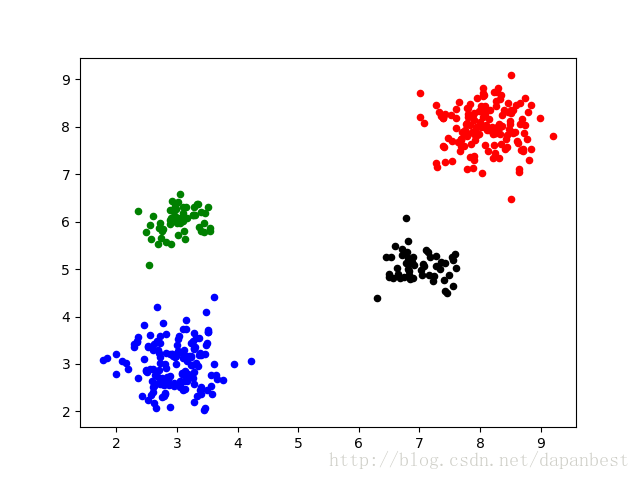
注意:由于第三类、第四类数据相对比较少,所以当种类数为4时,k值有时候会被确定为3,这时候左边绿色和蓝色的点会被分为同一类。因此,我的这种实现方式并不能保证k的值一定是最佳的,应该还有改进的空间。
那么,这次作业就写到这里啦~源码可以点击这里下载。完结撒花!














 712
712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









