









年底工作不是很忙,今天复习了下概率论中贝叶斯的基础知识,动手写了个Java版本的简单的拼写检查器。
我们在使用Google时,当我们输入一个错误的单词,经常可以看到Google提示我们是不是要查找什么什么。
它是怎样做到的呢?现在我们就来实现一个简单的拼写检查器。
1. 什么是贝叶斯公式?
来看来自维基百科的定义:
贝叶斯定理
贝叶斯定理由英国数学家贝叶斯 ( Thomas Bayes 1702-1761 ) 发展,用来描述两个条件概率之间的关系,比如 P(A|B) 和 P(B|A)。按照定理 6 的乘法法则,P(A∩B)=P(A)·P(B|A)=P(B)·P(A|B),可以立刻导出贝叶斯定理:
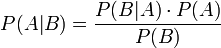
如上公式也可变形为 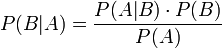
另一个例子,现分别有 A,B 两个容器,在容器 A 里分别有 7 个红球和 3 个白球,在容器 B 里有 1 个红球和 9 个白球,现已知从这两个容器里任意抽出了一个球,且是红球,问这个红球是来自容器 A 的概率是多少?
假设已经抽出红球为事件 B,从容器 A 里抽出球为事件 A,则有:P(B) = 8 / 20,P(A) = 1 / 2,P(B | A) = 7 / 10,按照公式,则有:
![]()
在上面的例子中,
事件A:要猜测事件的概率(从容器A里抽出球 - 要猜测和计算的事件)
事件B:现实已发生事件的概率(抽出红球 - 已经抽出红球,已经发生的事件)
正因贝叶斯公式可用于事件发生概率的推测,因此它广泛应用于计算机领域。从垃圾邮件的过滤,中文分词,机器翻译等等。下面的拼写检查器可以说是牛刀小试了。
2. 拼写检查器
第一步,以一个比较大的文本文件big.txt作为样本,分析每个单词出现的概率作为语言模型(Language Model)和词典。
big.txt的地址是:http://norvig.com/big.txt
第二步,如果用户输入的单词不在词典中,则产生编辑距离(Edit Distance)为2的所有可能单词。所谓编辑距离为1就是对用户输入的单词进行删除1个字符、添加1个字符、交换相邻字符、替换1个字符产生的所有单词。而编辑距离为2就是对这些单词再进行一次上述所有变换,因此最后产生的单词集会很大。可以与词典作差集,只保留词典中存在的单词。
第三步,假设事件c是我们猜测用户可能想要输入的单词,而事件w是用户实际输入的错误单词,根据贝叶斯公式可知:
P(c|w) = P(w|c) * P(c) / P(w)。
这里的P(w)对于每个单词都是一样的,可以忽略。而P(w|c)是误差模型(Error Model),是用户想要输入w却输入c的概率,这是需要大量样本数据和事实依据来得到的,为了简单起见也忽略掉。因此,我们可以找出编辑距离为2的单词集中P(c)概率最大的几个来提示用户。
3. Java代码实现
package
com.cdai.studio.spellcheck;
import
java.io.BufferedReader;
import
java.io.FileReader;
import
java.io.IOException;
import
java.io.InputStreamReader;
import
java.util.Collections;
import
java.util.Comparator;
import
java.util.HashMap;
import
java.util.HashSet;
import
java.util.LinkedList;
import
java.util.List;
import
java.util.Map;
import
java.util.Map.Entry;
import
java.util.Set;
import
java.util.regex.Pattern;
public
class
SpellCheck {
private
static
final
char
[]
ALPHABET
=
"abcdefghijklmnopqrstuvwxyz"
.toCharArray();
public
static
void
main(String[] args)
throws
Exception {
new
SpellCheck().start();
}
public
void
start()
throws
IOException {
// 1.Build language model
Map<String, Double> langModel = buildLanguageModel(
"big.txt"
);
Set<String> dictionary = langModel.keySet();
// 2.Read user input loop
BufferedReader reader =
new
BufferedReader(
new
InputStreamReader(System.
in
));
String input;
while
((input = reader.readLine()) !=
null
) {
input = input.trim().toLowerCase();
if
(
"bye"
.equals(input))
break
;
if
(dictionary.contains(input))
continue
;
long
startTime = System.currentTimeMillis();
// 3.Build set for word in edit distance and remove inexistent in dictionary
Set<String> wordsInEditDistance2 = buildEditDistance2Set(langModel, input);
wordsInEditDistance2.retainAll(dictionary);
// 4.Calculate Bayes's probability
// c - correct word we guess, w - wrong word user input in reality
// argmax P(c|w) = argmax P(w|c) * P(c) / P(w)
// we ignore P(w) here, because it's the same for all words
List<String> guessWords = guessCorrectWord(langModel, wordsInEditDistance2);
System.
out
.printf(
"Do you mean %s ? Cost time: %.3f second(s)\n"
,
guessWords.toString(), (System.currentTimeMillis() - startTime) / 1000D);
}
}
private
Map<String, Double> buildLanguageModel(String sample)
throws
IOException {
Map<String, Double> langModel =
new
HashMap<String, Double>();
BufferedReader reader =
new
BufferedReader(
new
FileReader(sample));
Pattern pattern = Pattern.compile(
"[a-zA-Z]+"
);
String line;
int
totalCnt = 0;
while
((line = reader.readLine()) !=
null
) {
String[] words = line.split(
" "
);
for
(String word : words) {
if
(pattern.matcher(word).matches()) {
word = word.toLowerCase();
Double wordCnt = langModel.get(word);
if
(wordCnt ==
null
)
langModel.put(word, 1D);
else
langModel.put(word, wordCnt + 1D);
totalCnt++;
}
}
}
reader.close();
for
(Entry<String, Double> entry : langModel.entrySet())
entry.setValue(entry.getValue() / totalCnt);
return
langModel;
}
private
Set<String> buildEditDistance1Set(
Map<String, Double> langModel,
String input) {
Set<String> wordsInEditDistance =
new
HashSet<String>();
char
[] characters = input.toCharArray();
// Deletion: delete letter[i]
for
(
int
i = 0; i < input.length(); i++)
wordsInEditDistance.add(input.substring(0,i) + input.substring(i+1));
// Transposition: swap letter[i] and letter[i+1]
for
(
int
i = 0; i < input.length()-1; i++)
wordsInEditDistance.add(input.substring(0,i) + characters[i+1] +
characters[i] + input.substring(i+2));
// Alteration: change letter[i] to a-z
for
(
int
i = 0; i < input.length(); i++)
for
(
char
c :
ALPHABET
)
wordsInEditDistance.add(input.substring(0,i) + c + input.substring(i+1));
// Insertion: insert new letter a-z
for
(
int
i = 0; i < input.length()+1; i++)
for
(
char
c :
ALPHABET
)
wordsInEditDistance.add(input.substring(0,i) + c + input.substring(i));
return
wordsInEditDistance;
}
private
Set<String> buildEditDistance2Set(
Map<String, Double> langModel,
String input) {
Set<String> wordsInEditDistance1 = buildEditDistance1Set(langModel, input);
Set<String> wordsInEditDistance2 =
new
HashSet<String>();
for
(String editDistance1 : wordsInEditDistance1)
wordsInEditDistance2.addAll(buildEditDistance1Set(langModel, editDistance1));
wordsInEditDistance2.addAll(wordsInEditDistance1);
return
wordsInEditDistance2;
}
private
List<String> guessCorrectWord(
final
Map<String, Double> langModel,
Set<String> wordsInEditDistance) {
List<String> words =
new
LinkedList<String>(wordsInEditDistance);
Collections.sort(words,
new
Comparator<String>() {
@Override
public
int
compare(String word1, String word2) {
return
langModel.get(word2).compareTo(langModel.get(word1));
}
});
return
words.size() > 5 ? words.subList(0, 5) : words;
}
}
运行结果:
raechel
Do you mean [reached, reaches, ranches, rachel] ? Cost time: 0.219 second(s)
thew
Do you mean [the, that, he, her, they] ? Cost time: 0.062 second(s)
虽然不是很准确,但是不是很有趣呢?如果感兴趣,我们可以继续深入学习。
有了兴趣和求知欲,并不断实践,才能学好编程。
2011.12.28更新:
产生编辑距离为2的单词时,应该让编辑距离为1的单词具有更高的优先级。并且当用户输入的单词长度较长时,产生编辑距离为2的单词可能会花费一些时间。所以可以优化为首先产生编辑距离为1的单词,如果与词典做差集后为空,再产生编辑距离为2的单词。将main方法中的第三步代码修改为:
// 3.Build set for word in edit distance and remove inexistent in dictionary
Set<String> wordsInEditDistance = buildEditDistance1Set(langModel, input);
wordsInEditDistance.retainAll(dictionary);
if
(wordsInEditDistance.isEmpty()) {
wordsInEditDistance = buildEditDistance2Set(langModel, input);
wordsInEditDistance.retainAll(dictionary);
if
(wordsInEditDistance.isEmpty()) {
System.
out
.println(
"Failed to check this spell"
);
continue
;
}
}
参考文章
怎样写一个拼写检查器
http://blog.youxu.info/spell-correct.html















 3638
3638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









