







注:本文主要出自于维基百科。
原理
给定一个概率分布D,假定器概率密度函数(连续分布)或概率质量函数(离散分布)为 fD ,以及一个分布参数 θ ,我们可以从这个分布中抽取一个具有n个值的采样 X1,X2,...,Xn ,通过利用 fD ,我们就能计算出其概率:
参数 θ 不确定,但是模型 fD 是确定的,所以要估计 θ 的值,就要从这个分布中抽取n个值的采样 X1,X2,...,Xn ,利用这些采样数据来估计参数 θ 。
要在数学上实现最大似然估计,首先要定义似然函数:
注意: 似然函数是指当 x1,x2,...,xn 不变时,关于 θ 的一个函数;最大似然函数不一定唯一,也可能不存在。
举例
离散分布,离散有限参数空间
考虑一个抛硬币的例子。假设这个硬币正面跟反面轻重不同。我们把这个硬币抛80次(即,我们获取一个采样
x1=H,x2=T,...,x80=T
,并把正面的次数记下来,正面记为H,反面记为T)。并把抛出一个正面的概率记为
p
,抛出一个反面的概率记为
我们可以看到当 p^=2/3 时,似然函数取得最大值,这就是p的最大似然估计。
离散分布,连续参数空间
现在假设例子1中的盒子中有无数个硬币,对于
0≤p≤1
中的任何一个
p
, 都有一个抛出正面概率为
可用微分法来求最值,对方程求微,并让其等于0。
最后的解为: p=0,p=1,p=49/80 ,最大似然估计值为 p^=49/80 ,符合伯努利试验– p^=t/n ,t为成功次数,n为总次数。
连续分布,连续参数空间
最常见的连续概率分布是正态分布,其概率密度函数如下:
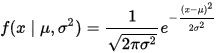
现在有
n
个正态随机变量的采样点,要求的是一个这样的正态分布,这些采样点分布到这个正态分布可能性最大(也就是概率密度积最大,每个点更靠近中心点),其
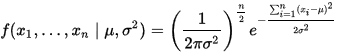
或
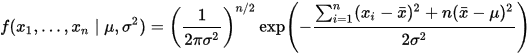
这个分布有两个参数: μ,σ2 .实际上,在两个参数上的求最大值的方法也差不多:只需要分别把可能性 lik(μ,σ)=f(x1,x2,...,xn|μ,σ2) 在两个参数上最大化即可。当然这比一个参数麻烦一些,但是一点也不复杂。使用上边例子同样的符号,我们有 θ=(μ,σ2) .
最大化一个似然函数同最大化它的自然对数是等价的。因为自然对数log是一个连续且在似然函数的值域内严格递增的上凸函数。[注意:可能性函数(似然函数)的自然对数跟信息熵以及Fisher信息联系紧密。]求对数通常能够一定程度上简化运算,比如在这个例子中可以看到:
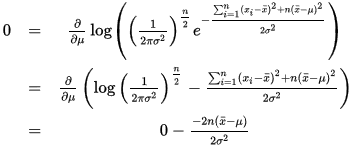
这个方程的解是 μ^=x¯=∑ni=1xi/n 这的确是这个函数的最大值,因为它是 μ 里头惟一的一阶导数等于零的点并且二阶导数严格小于零。
同理,对 σ 求导,并令其等于0.
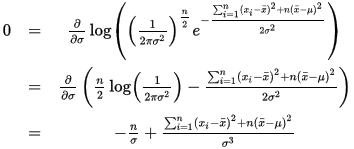
这个方程的解为: σ^2=∑ni=1(xi−μ^)2/n .
所以关于
θ=(μ,σ2)
的最大似然估计为:
小结
最大似然估计其实是已知函数模型,但是模型中的部分参数未知,于是采样N个样本值,来估计使其函数值最大的参数值。“已知模型,最大参数估计”。PS:最大似然估计中采样需满足一个很重要的假设,就是所有的采样都是独立同分布的。
由上可知最大似然估计的一般求解过程:
(1) 写出似然函数;
(2) 对似然函数取对数,并整理;
(3) 求导数 ;
(4) 解似然方程















 1486
1486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









