







一、引入
极大似然估计,我们也把它叫做最大似然估计(Maximum Likelihood Estimation),英文简称MLE。它是机器学习中常用的一种参数估计方法。它提供了一种给定观测数据来评估模型参数的方法。也就是模型已知,参数未定。
在我们正式讲解极大似然估计之前,我们先简单回顾以下两个概念:
- 概率密度函数(Probability Density function),英文简称pdf
- 似然函数(Likelyhood function)
1.1 概率密度函数
连续型随机变量的概率密度函数(pdf)是一个描述随机变量在某个确定的取值点附近的可能性的函数(也就是某个随机变量值的概率值,注意这是某个具体随机变量值的概率,不是一个区间的概率)。给个最简单的概率密度函数的例子,均匀分布密度函数。
对于一个取值在区间[a,b]上的均匀分布函数
I
[
a
,
b
]
I_{[a,b]}
I[a,b],它的概率密度函数为:
f
I
[
a
,
b
]
(
x
)
=
1
b
−
a
I
[
a
,
b
]
f_{I_{[a,b]}}(x) = \frac{1}{b-a}I_{[a,b]}
fI[a,b](x)=b−a1I[a,b]
其图像为:
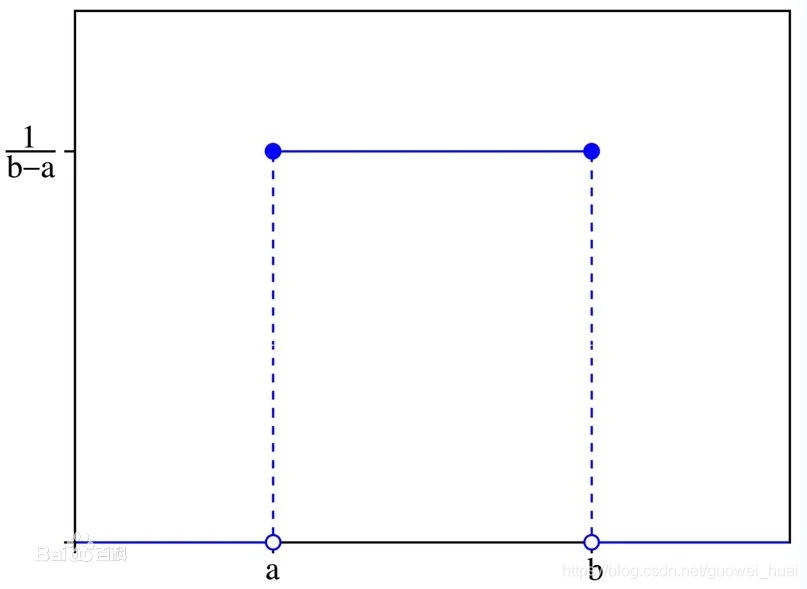
其中横轴为随机变量的取值,纵轴为概率密度函数的值。
也就是说,当
x
x
x不在区间
[
a
,
b
]
[a,b]
[a,b]上的时候,函数值为0,在区间
[
a
,
b
]
[a,b]
[a,b]上的时候,函数值等于
1
b
−
a
\frac{1}{b-a}
b−a1,函数值即当随机变量
X
=
a
X=a
X=a的概率值。这个函数虽然不是完全连续的函数,但是它可以积分。而随机变量的取值落在某个区域内的概率为概率密度函数在这个区域上的积分。
Tips:
- 当概率密度函数存在的时候,累计分布函数是概率密度函数的积分。
- 对于离散型随机变量,我们把它的密度函数称为概率质量密度函数
- 对概率密度函数作类似福利叶变换可以得到特征函数。特征函数与概率密度函数有一对一的关系。因此,知道一个分布的特征函数就等同于知道一个分布的概率密度函数。(这里就是提一嘴,本文所讲的内容与特征函数关联不大,如果不懂可以暂时忽略。)
1.2 似然函数
官方一点解释似然函数是,它是一种关于统计模型中的参数的函数,表示模型参数的似然性(likelyhood)。 相信看着这句话的同志们都挺懵的,这是在说什么鬼话,啥叫关于参数的函数??啥叫似然性??
咱们这就来解释:
“似然性”它 与 ("或然性"或 “概率性”或”概率“)意思相近,都是指事件发生的可能性。但是 似然性 和 概率 在统计学中还是有明确的区分。
- 概率:在参数已知的情况下,预测观测结果;
- 似然性:在观测结果已知的情况下,对参数进行估值和猜测。
按照上面的说法,其实我们很容易联想到的就是条件概率。我们也可以将似然函数理解为条件概率的逆反。
在已知某个参数B时,事情A会发生的概率为
P
(
A
∣
B
)
=
P
(
A
,
B
)
P
(
B
)
P(A|B) = \frac{P(A,B)}{P(B)}
P(A∣B)=P(B)P(A,B)
又贝叶斯定理可得
P
(
B
∣
A
)
=
P
(
A
∣
B
)
P
(
B
)
P
(
A
)
P(B|A) = \frac{P(A|B)P(B)}{P(A)}
P(B∣A)=P(A)P(A∣B)P(B)
我们可以反过来构造来表示似然性的方法:已知有事情A发生,运用似然函数
L
(
B
∣
A
)
L(B|A)
L(B∣A),我们估计参数B的不同值的可能性。形式上,似然函数也是一种条件概率函数,但是我们关注的变量改变了
b
→
P
(
A
∣
B
=
b
)
b \rightarrow P(A| B= b)
b→P(A∣B=b)
注意: 这里并不要求似然函数满足归一性:即
∑
b
∈
β
P
(
A
∣
B
=
b
)
=
1
\sum_{b \in \beta} P(A|B=b) = 1
b∈β∑P(A∣B=b)=1
(在1.3的例子中会作出解释)
一个似然函数乘以一个正的常数之后仍然是似然函数。对所有的
α
>
0
\alpha>0
α>0,都可以有似然函数:
L
(
b
∣
A
)
=
α
P
(
A
∣
B
=
b
)
L(b|A) = \alpha P(A|B=b)
L(b∣A)=αP(A∣B=b)
其中,
α
=
P
(
B
)
P
(
A
)
\alpha = \frac{P(B)}{P(A)}
α=P(A)P(B)
1.3 似然函数的举例
以经典的投掷硬币试验为例子。已知掷出一枚硬币,正面朝上和反面朝上的概率相同,正面向上概率为
p
H
p_{H}
pH。比如说,连续扔两次都是正面向上的概率是0.25,如果我们用条件概率表示就是:
P
(
H
H
∣
p
H
)
=
0.
5
2
=
0.25
P(HH|p_{H}) = 0.5^2 = 0.25
P(HH∣pH)=0.52=0.25其中
H
H
H表示正面朝上。
但是,一般来说我们更关心的是在已知一系列投掷结果的同时,关于单独投掷一次硬币时正面向上的概率(即
p
H
p_{H}
pH)的值。
实际上我们无法从一系列的结果中来直接逆推真实的值
p
H
p_{H}
pH,但是我们可以去估计
p
H
p_{H}
pH是某个值的可能性是多少。比如,当这个硬币正面向上和反面向上的可能性是不同的且
p
H
p_{H}
pH未知,此时如果我们想要求投掷三次硬币,其中两次是正面的概率是无法求出的。现在如果我们实际去投掷三次硬币,结果中两次正面向上,一次反面向上,我们能否逆推出
p
H
p_{H}
pH呢?如果不能,那么我们能不能推出
p
H
=
0.5
的
可
能
性
?
或
者
p
H
=
0.6
的
可
能
性
是
多
少
p_{H}=0.5的可能性?或者p_{H}=0.6的可能性是多少
pH=0.5的可能性?或者pH=0.6的可能性是多少 再退一步,就算我们不能直接求出这两个值的可能性,我们能否间接比较出这两个值的可能性大小?
顺着上面的思路,我们先将上面的例子进行数学化表示::
比如投掷一次硬币,正面朝上的概率有
p
H
p_{H}
pH代表,它就是这个例子的参数。我们用事件A来代表三次硬币中两次是正面的这个事实。使用联合概率计算可知:
P
(
A
∣
p
H
)
=
3
×
p
H
2
×
(
1
−
p
H
)
P(A|p_{H}) = 3 \times p_{H}^2 \times (1 - p_{H})
P(A∣pH)=3×pH2×(1−pH)
- 假设 p H = 0.5 p_{H} = 0.5 pH=0.5,则三次投掷中两次是正面的概率为 P ( A ∣ p H = 0.5 ) = 0.375 P(A|p_{H}=0.5) = 0.375 P(A∣pH=0.5)=0.375
- 再假设 p H = 0.6 p_{H} = 0.6 pH=0.6,则三次投掷中两次是正面的概率为 P ( A ∣ p H = 0.6 ) = 0.432 P(A|p_{H}=0.6) = 0.432 P(A∣pH=0.6)=0.432
显然,如果 p H = 0.6 p_{H}=0.6 pH=0.6的话,我们看到两个正面的机会比较高。而根据试验我们已经知道三次实验中,确切的是有两枚硬币正面向上。虽然我们不知道实际上 p H p_{H} pH的值具体是多少,可能是0.62 or 0.58 等等,但是我们至少知道 p H p_{H} pH是0.6的可能性比是0.5的可能性还要高。因此我们合理的估计 p H p_{H} pH比较可能是0.6而不是0.5。
因此,我们进一步理解了似然性的概念:
**似然性代表某个参数为特定值的可能性。**由上面例子知,在观察到事件A的情况下,参数
p
H
p_{H}
pH在不同值的可能性或似然性为:
L
(
p
H
∣
A
)
=
P
(
A
∣
p
H
)
L(p_{H}|A) = P(A|p_{H})
L(pH∣A)=P(A∣pH)
所以当我们投掷硬币三次,其中两次是正面,则
p
H
=
0.5
p_{H}=0.5
pH=0.5的似然性是
L
(
p
H
=
0.5
∣
A
)
=
P
(
A
∣
p
H
=
0.5
)
=
0.375
L(p_{H}=0.5|A) = P(A|p_{H}=0.5) = 0.375
L(pH=0.5∣A)=P(A∣pH=0.5)=0.375。而
p
H
=
0.6
p_{H}=0.6
pH=0.6的似然性是
L
(
p
H
=
0.6
∣
A
)
=
P
(
A
∣
p
H
=
0.6
)
=
0.432
L(p_{H}=0.6|A) = P(A|p_{H}=0.6) = 0.432
L(pH=0.6∣A)=P(A∣pH=0.6)=0.432。注意,
L
(
p
H
=
0.5
∣
A
)
=
0.375
L(p_{H}=0.5|A) = 0.375
L(pH=0.5∣A)=0.375并不是说已知A发生了,则
p
H
为
0.5
p_{H}为0.5
pH为0.5的概率是0.375。似然性和概率具有不同的意义,上面已经谈过。 如果单独看0.375和0.432数字是没有意义的。因为似然性并不是概率,也并不是介于0-1之间的,而所有可能的p_{H}的似然性加起来也不是1,所以单独看0.375或者0.432这个数字是没有意义的。似然性是把各种可能的
p
H
p_{H}
pH值放在一起去比较,来得知哪个
p
H
p_{H}
pH值的可能性比较高。而似然函数除了用于计算似然性之外,还用来了解当参数
p
H
p_{H}
pH变化时,似然性怎么变换,由此来寻找最大可能性的
p
H
p_{H}
pH的值会是多少。
P
(
A
∣
p
H
)
=
3
×
p
H
2
×
(
1
−
p
H
)
P(A|p_{H}) = 3 \times p_{H}^2 \times (1 - p_{H})
P(A∣pH)=3×pH2×(1−pH)
由该式子可知,我们知道当
p
x
=
2
3
p_{x}= \frac{2}{3}
px=32时,其值最大(可以通过求导来计算),也就是说最大似然性发生在了
p
H
=
2
3
p_{H}= \frac{2}{3}
pH=32。所以当我们投掷了三次硬币得到两次正面,最合理的猜测应该是
p
H
=
2
3
p_{H} = \frac{2}{3}
pH=32。
因此,我们得出结论:
对同一个似然函数,其所代表的模型中,某项参数值具有多种可能,但如果存在一个参数值,使得概似函数值达到最大的话,那么这个值就是该项参数最为“合理”的参数值。
二、 最大似然估计
最大似然估计是似然函数最初的应用。上面已经提到,似然函数取得最大值表示相应的参数能够使得统计模型最为合理。从这样一个想法出发,最大似然估计的做法是:首先选取似然函数 (一般是概率密度函数或概率质量函数),整理之后求最大值点。实际应用中一般会取似然函数的 对数 作为求最大值的函数,这样求出的最大值点和直接求最大值点得到的结果是相同的。==似然函数的最大值点不一定唯一,也不一定存在。==与矩法估计比较,最大似然估计的精确度较高,信息损失较少,但计算量较大。
2.1 例1:离散分布、离散有限参数空间举例

2.2 例2:离散分布,连续参数空间举例

三、最大似然估计的瓶颈
极大似然估计假设连续数据服从正态分布,虽然由于中心极限定理在样本量足够大的时候这一假设都能够满足,但当样本量过小且数据不服从正态分布时,估计误差会比较大。另一个缺点就是当样本服从的概率分布过于复杂时算法的计算也非常复杂而且耗时(可以了解一下EM算法和准极大似然估计,这两种算法都是基于简化计算的思想而发明的)
四、总结
在了解最大似然估计方法后,我们就会对机器学习的经典算法有更深的理解,朴素贝叶斯、决策树等等算法,在进行参数估计是都会使用到最大似然估计。上面有提到最大似然估计的瓶颈,但是它也有自己的优势:一致性、渐进正态性、泛函不变性。在初期学习时,我们学的是如何套用这种算法;学到深处,我们要考虑如何通过具体场景、具体问题,选择合适的算法来提高性能,这也是融会贯通的一种表现吧。
Reference:
极大似然估计-机器之心
最大似然估计-维基百科
似然函数-维基百科
















 4152
4152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











